如何使用Python中的np.random.permutation函数?
 发布于2023-05-10 阅读(0)
发布于2023-05-10 阅读(0)
扫一扫,手机访问
一:函数介绍
np.random.permutation() 总体来说他是一个随机排列函数,就是将输入的数据进行随机排列,官方文档指出,此函数只能针对一维数据随机排列,对于多维数据只能对第一维度的数据进行随机排列。
简而言之:np.random.permutation函数的作用就是按照给定列表生成一个打乱后的随机列表
在处理数据集时,通常可以使用该函数进行打乱数据集内部顺序,并按照同样的顺序进行标签序列的打乱。
二:实例
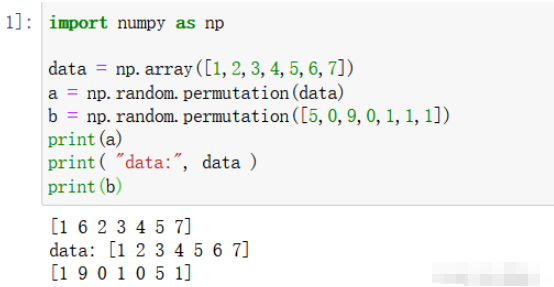
2.1 直接处理数组或列表数
import numpy as np data = np.array([1,2,3,4,5,6,7]) a = np.random.permutation(data) b = np.random.permutation([5,0,9,0,1,1,1]) print(a) print( "data:", data ) print(b)
2.2 间接处理:不改变原数据(对数组下标的处理)
label = np.array([1,2,3,4,5,6,7])
a = np.random.permutation(np.arange(len(label)))
print("Label[a] :" ,label[a] )
补:一般只能用于N维数组 只能将整数标量数组转换为标量索引
why?label1[a1] label1是列表,a1是列表下标的随机排列 但是! 列表结构没有标量索引 label1[a1]报错
label1=[1,2,3,4,5,6,7]
print(len(label1))
a1 = np.random.permutation(np.arange(len(label1)))#有结果
print(a1)
print("Label1[a1] :" ,label1[a1] )#这列表结构没有标量索引 所以会报错
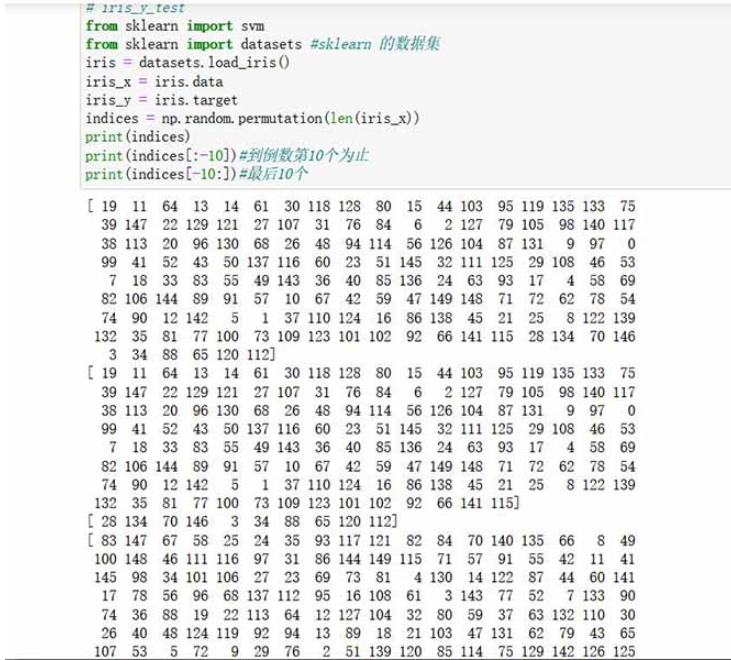
2.3 实例:鸢尾花数据中对鸢尾花的随机打乱(可以直接用)
from sklearn import svm from sklearn import datasets #sklearn 的数据集 iris = datasets.load_iris() iris_x = iris.data iris_y = iris.target indices = np.random.permutation(len(iris_x)) #此时 打乱的是数组的下标的排序 print(indices) print(indices[:-10])#到倒数第10个为止 print(indices[-10:])#最后10个 # print(type(iris_x)) <class 'numpy.ndarray'> #9:1分类 #iris_x_train = iris_x[indices[:-10]]#使用的数组打乱后的下标 #iris_y_train = iris_y[indices[:-10]] #iris_x_test= iris_x[indices[-10:]] #iris_y_test= iris_y[indices[-10:]]
数组下标 即标量索引的重新分布情况: 下标是0开始
本文转载于:https://www.yisu.com/zixun/779738.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:实例分析:Python的并行执行
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Laravel Blade 中遍历嵌套数组的正确方式
- 本文详解LaravelBlade模板中因错误嵌套@for与@foreach导致“Tryingtoaccessarrayoffsetonthevalueoftypeint”错误的原因,并提供安全、简洁、符合Laravel最佳实践的数组遍历方案。
- 2小时前 23:45 0
-
 正版软件
正版软件
- RNN与LSTM基础详解及应用
- RNN通过隐藏状态传递时序信息,但难以捕捉长期依赖;LSTM引入遗忘门、输入门和输出门机制,有效解决梯度消失问题,提升对长距离依赖的学习能力,适用于语言建模、翻译等序列任务。
- 2小时前 23:30 0
-
 正版软件
正版软件
- Go 中动态设置 glog 日志路径方法
- 本文介绍如何绕过命令行参数,直接在Go源码中通过flag包动态配置glog的log_dir、logtostderr和日志等级等关键选项,实现运行时日志路径与行为的灵活控制。
- 2小时前 23:15 0
-
 正版软件
正版软件
- Nginx基于Cookie灰度发布实现方法
- Nginx可通过Cookie实现灰度发布:先定义stable/beta两组upstream,再用map指令根据$cookie_version值映射$backend_group,最后在location中proxy_pass动态路由至backend_$backend_group。
- 3小时前 23:00 0
-
 正版软件
正版软件
- Python与C语言区别详解
- Python与C本质是设计哲学不同的工具:Python追求开发效率与表达力,C专注运行效率与底层控制;选择取决于具体问题而非优劣。
- 3小时前 22:45 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 215天前
-
4
- 探析Spring Boot框架的优点和特色
- 530天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 468天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 444天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1076天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 904天前
-
 9
9
- 解决Python安装失败的问题
- 454天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00