涨知识!用逻辑规则进行机器学习
 发布于2023-05-16 阅读(0)
发布于2023-05-16 阅读(0)
扫一扫,手机访问
Skope-rules使用树模型生成规则候选项。首先建立一些决策树,并将从根节点到内部节点或叶子节点的路径视为规则候选项。然后通过一些预定义的标准(如精确度和召回率)对这些候选规则进行过滤。只有那些精确度和召回率高于其阈值的才会被保留。最后,应用相似性过滤来选择具有足够多样性的规则。一般情况下,应用Skope-rules来学习每个根本原因的潜在规则。
项目地址:https://github.com/scikit-learn-contrib/skope-rules
- Skope-rules是一个建立在scikit-learn之上的Python机器学习模块,在3条款BSD许可下发布。
- Skope-rules旨在学习逻辑的、可解释的规则,用于 "界定 "目标类别,即高精度地检测该类别的实例。
- Skope-rules是决策树的可解释性和随机森林的建模能力之间的一种权衡。
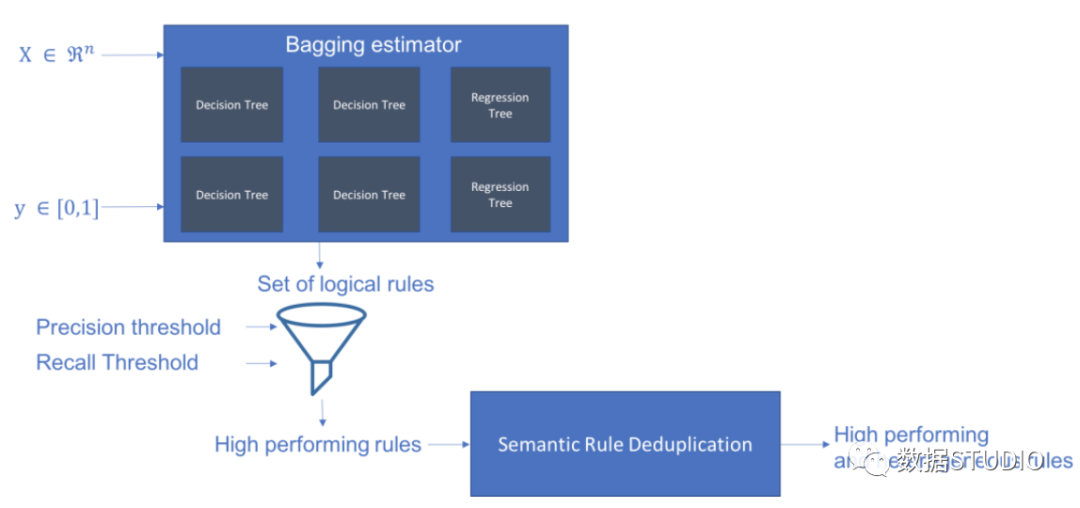
schema
安装
可以使用 pip 获取最新资源:
pip install skope-rules
快速开始
SkopeRules 可用于描述具有逻辑规则的类:
from sklearn.datasets import load_iris
from skrules import SkopeRules
dataset = load_iris()
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
clf = SkopeRules(max_depth_duplicatinotallow=2,
n_estimators=30,
precision_min=0.3,
recall_min=0.1,
feature_names=feature_names)
for idx, species in enumerate(dataset.target_names):
X, y = dataset.data, dataset.target
clf.fit(X, y == idx)
rules = clf.rules_[0:3]
print("Rules for iris", species)
for rule in rules:
print(rule)
print()
print(20*'=')
print()
注意:
如果出现如下错误:

解决方案:
关于 Python 导入错误 : cannot import name 'six' from 'sklearn.externals' ,云朵君在Stack Overflow上找到一个类似的问题:https://stackoverflow.com/questions/61867945/
解决方案如下
import six import sys sys.modules['sklearn.externals.six'] = six import mlrose
亲测有效!
如果使用“score_top_rules”方法,SkopeRules 也可以用作预测器:
from sklearn.datasets import load_boston
from sklearn.metrics import precision_recall_curve
from matplotlib import pyplot as plt
from skrules import SkopeRules
dataset = load_boston()
clf = SkopeRules(max_depth_duplicatinotallow=None,
n_estimators=30,
precision_min=0.2,
recall_min=0.01,
feature_names=dataset.feature_names)
X, y = dataset.data, dataset.target > 25
X_train, y_train = X[:len(y)//2], y[:len(y)//2]
X_test, y_test = X[len(y)//2:], y[len(y)//2:]
clf.fit(X_train, y_train)
y_score = clf.score_top_rules(X_test) # Get a risk score for each test example
precision, recall, _ = precision_recall_curve(y_test, y_score)
plt.plot(recall, precision)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision Recall curve')
plt.show()
实战案例
本案例展示了在著名的泰坦尼克号数据集上使用skope-rules。
skope-rules适用情况:
- 解决二分类问题
- 提取可解释的决策规则
本案例分为5个部分
- 导入相关库
- 数据准备
- 模型训练(使用ScopeRules().score_top_rules()方法)
- 解释 "生存规则"(使用SkopeRules().rules_属性)。
- 性能分析(使用SkopeRules.predict_top_rules()方法)。
导入相关库
# Import skope-rules
from skrules import SkopeRules
# Import librairies
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, precision_recall_curve
from matplotlib import cm
import numpy as np
from sklearn.metrics import confusion_matrix
from IPython.display import display
# Import Titanic data
data = pd.read_csv('../data/titanic-train.csv')数据准备
# 删除年龄缺失的行
data = data.query('Age == Age')
# 为变量Sex创建编码值
data['isFemale'] = (data['Sex'] == 'female') * 1
# 未变量Embarked创建编码值
data = pd.concat(
[data,
pd.get_dummies(data.loc[:,'Embarked'],
dummy_na=False,
prefix='Embarked',
prefix_sep='_')],
axis=1
)
# 删除没有使用的变量
data = data.drop(['Name', 'Ticket', 'Cabin',
'PassengerId', 'Sex', 'Embarked'],
axis = 1)
# 创建训练及测试集
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['Survived'], axis=1),
data['Survived'],
test_size=0.25, random_state=42)
feature_names = X_train.columns
print('Column names are: ' + ' '.join(feature_names.tolist())+'.')
print('Shape of training set is: ' + str(X_train.shape) + '.')Column names are: Pclass Age SibSp Parch Fare isFemale Embarked_C Embarked_Q Embarked_S. Shape of training set is: (535, 9).
模型训练
# 训练一个梯度提升分类器,用于基准测试 gradient_boost_clf = GradientBoostingClassifier(random_state=42, n_estimators=30, max_depth = 5) gradient_boost_clf.fit(X_train, y_train) # 训练一个随机森林分类器,用于基准测试 random_forest_clf = RandomForestClassifier(random_state=42, n_estimators=30, max_depth = 5) random_forest_clf.fit(X_train, y_train) # 训练一个决策树分类器,用于基准测试 decision_tree_clf = DecisionTreeClassifier(random_state=42, max_depth = 5) decision_tree_clf.fit(X_train, y_train) # 训练一个 skope-rules-boosting 分类器 skope_rules_clf = SkopeRules(feature_names=feature_names, random_state=42, n_estimators=30, recall_min=0.05, precision_min=0.9, max_samples=0.7, max_depth_duplicatinotallow= 4, max_depth = 5) skope_rules_clf.fit(X_train, y_train) # 计算预测分数 gradient_boost_scoring = gradient_boost_clf.predict_proba(X_test)[:, 1] random_forest_scoring = random_forest_clf.predict_proba(X_test)[:, 1] decision_tree_scoring = decision_tree_clf.predict_proba(X_test)[:, 1] skope_rules_scoring = skope_rules_clf.score_top_rules(X_test)
"生存规则" 的提取
# 获得创建的生存规则的数量
print("用SkopeRules建立了" + str(len(skope_rules_clf.rules_)) + "条规则n")
# 打印这些规则
rules_explanations = [
"3岁以下和37岁以下,在头等舱或二等舱的女性。"
"3岁以上乘坐头等舱或二等舱,支付超过26欧元的女性。"
"坐一等舱或二等舱,支付超过29欧元的女性。"
"年龄在39岁以上,在头等舱或二等舱的女性。"
]
print('其中表现最好的4条 "泰坦尼克号生存规则" 如下所示:/n')
for i_rule, rule in enumerate(skope_rules_clf.rules_[:4])
print(rule[0])
print('->'+rules_explanations[i_rule]+ 'n')用SkopeRules建立了9条规则。 其中表现最好的4条 "泰坦尼克号生存规则" 如下所示: Age <= 37.0 and Age > 2.5 and Pclass <= 2.5 and isFemale > 0.5 -> 3岁以下和37岁以下,在头等舱或二等舱的女性。 Age > 2.5 and Fare > 26.125 and Pclass <= 2.5 and isFemale > 0.5 -> 3岁以上乘坐头等舱或二等舱,支付超过26欧元的女性。 Fare > 29.356250762939453 and Pclass <= 2.5 and isFemale > 0.5 -> 坐一等舱或二等舱,支付超过29欧元的女性。 Age > 38.5 and Pclass <= 2.5 and isFemale > 0.5 -> 年龄在39岁以上,在头等舱或二等舱的女性。
def compute_y_pred_from_query(X, rule):
score = np.zeros(X.shape[0])
X = X.reset_index(drop=True)
score[list(X.query(rule).index)] = 1
return(score)
def compute_performances_from_y_pred(y_true, y_pred, index_name='default_index'):
df = pd.DataFrame(data=
{
'precision':[sum(y_true * y_pred)/sum(y_pred)],
'recall':[sum(y_true * y_pred)/sum(y_true)]
},
index=[index_name],
columns=['precision', 'recall']
)
return(df)
def compute_train_test_query_performances(X_train, y_train, X_test, y_test, rule):
y_train_pred = compute_y_pred_from_query(X_train, rule)
y_test_pred = compute_y_pred_from_query(X_test, rule)
performances = None
performances = pd.concat([
performances,
compute_performances_from_y_pred(y_train, y_train_pred, 'train_set')],
axis=0)
performances = pd.concat([
performances,
compute_performances_from_y_pred(y_test, y_test_pred, 'test_set')],
axis=0)
return(performances)
print('Precision = 0.96 表示规则确定的96%的人是幸存者。')
print('Recall = 0.12 表示规则识别的幸存者占幸存者总数的12%n')
for i in range(4):
print('Rule '+str(i+1)+':')
display(compute_train_test_query_performances(X_train, y_train,
X_test, y_test,
skope_rules_clf.rules_[i][0])
)Precision = 0.96 表示规则确定的96%的人是幸存者。 Recall = 0.12 表示规则识别的幸存者占幸存者总数的12%。

模型性能检测
def plot_titanic_scores(y_true, scores_with_line=[], scores_with_points=[],
labels_with_line=['Gradient Boosting', 'Random Forest', 'Decision Tree'],
labels_with_points=['skope-rules']):
gradient = np.linspace(0, 1, 10)
color_list = [ cm.tab10(x) for x in gradient ]
fig, axes = plt.subplots(1, 2, figsize=(12, 5),
sharex=True, sharey=True)
ax = axes[0]
n_line = 0
for i_score, score in enumerate(scores_with_line):
n_line = n_line + 1
fpr, tpr, _ = roc_curve(y_true, score)
ax.plot(fpr, tpr, linestyle='-.', c=color_list[i_score], lw=1, label=labels_with_line[i_score])
for i_score, score in enumerate(scores_with_points):
fpr, tpr, _ = roc_curve(y_true, score)
ax.scatter(fpr[:-1], tpr[:-1], c=color_list[n_line + i_score], s=10, label=labels_with_points[i_score])
ax.set_title("ROC", fnotallow=20)
ax.set_xlabel('False Positive Rate', fnotallow=18)
ax.set_ylabel('True Positive Rate (Recall)', fnotallow=18)
ax.legend(loc='lower center', fnotallow=8)
ax = axes[1]
n_line = 0
for i_score, score in enumerate(scores_with_line):
n_line = n_line + 1
precision, recall, _ = precision_recall_curve(y_true, score)
ax.step(recall, precision, linestyle='-.', c=color_list[i_score], lw=1, where='post', label=labels_with_line[i_score])
for i_score, score in enumerate(scores_with_points):
precision, recall, _ = precision_recall_curve(y_true, score)
ax.scatter(recall, precision, c=color_list[n_line + i_score], s=10, label=labels_with_points[i_score])
ax.set_title("Precision-Recall", fnotallow=20)
ax.set_xlabel('Recall (True Positive Rate)', fnotallow=18)
ax.set_ylabel('Precision', fnotallow=18)
ax.legend(loc='lower center', fnotallow=8)
plt.show()
plot_titanic_scores(y_test,
scores_with_line=[gradient_boost_scoring, random_forest_scoring, decision_tree_scoring],
scores_with_points=[skope_rules_scoring]
)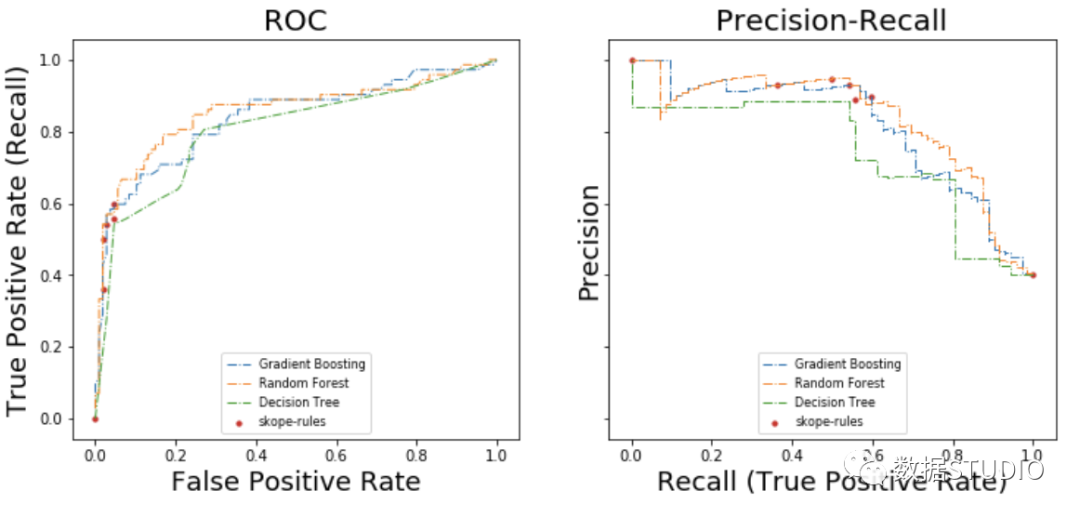
在ROC曲线上,每个红点对应于激活的规则(来自skope-rules)的数量。例如,最低点是1个规则(最好的)的结果点。第二低点是2条规则结果点,等等。
在准确率-召回率曲线上,同样的点是用不同的坐标轴绘制的。警告:左边的第一个红点(0%召回率,100%精度)对应于0条规则。左边的第二个点是第一个规则,等等。
从这个例子可以得出一些结论。
- skope-rules的表现比决策树好。
- skope-rules的性能与随机森林/梯度提升相似(在这个例子中)。
- 使用4个规则可以获得很好的性能(61%的召回率,94%的精确度)(在这个例子中)。
n_rule_chosen = 4
y_pred = skope_rules_clf.predict_top_rules(X_test, n_rule_chosen)
print('The performances reached with '+str(n_rule_chosen)+' discovered rules are the following:')
compute_performances_from_y_pred(y_test, y_pred, 'test_set')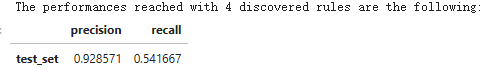
predict_top_rules(new_data, n_r)方法用来计算对new_data的预测,其中有前n_r条skope-rules规则。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 币圈资讯平台有哪些?币圈专业资讯平台推荐
- 获取加密货币市场动态的推荐平台有:CoinMarketCap:实时价格和广泛的数据CoinGecko:深入的分析和新兴加密货币BinanceInfo:行业新闻和币安项目CryptoSlate:独家报道和观点多样性Blockworks:高质量记者报道和教育内容TheBlock:机构投资者新闻和独家数据Cointelegraph:国际记者团队和全球市场视角Decrypt:深入报道和原创视频内容
- 17分钟前 0
-
 正版软件
正版软件
- 中移物联推出“防堵疏监管”五位一体电动自行车安全充电解决方案
- “锵锵一拧,‘咣’的一声,轻轻一拧油门,便可轻松前行,既省力又省时。在国家大力推倡绿色低碳环保的背景下,电动自行车已成为广大市民短途出行的重要方式之一。据国家应急管理部公布数据,目前我国电动自行车保有量已达3.5亿辆。”某社区车库安装的和易充安全充电桩“充电太难了,家住6楼,楼下没有集中充电,家里充电又担心安全问题。”一位小区居民说道。随着电动自行车的普及,小区电动车的充电问题也日益突出,由电动车充电引发的火灾事故也频频发生。因此,规范电动车停放及安全充电管理迫在眉睫。针对现有电动自行车充电安全的痛点问题
- 37分钟前 0
-
 正版软件
正版软件
- 小米规划上海总部地块被收回?徐汇区:该地块已由商办混合用地调整为住宅用地
- 本站5月23日消息,近日,小米于三年前摘得的上海徐汇滨江一宗商业办公用地发生变更引发关注。"小米公司发言人昨天已经对此事进行了回应,称小米在上海的经营发展顺利,徐汇区斜土街道xh128D-07地块的相关事宜系根据发展需求,按程序落实。"据报道,上海市徐汇区官方对此表示:5月20日徐汇区规划和自然资源局已对《上海市徐汇区黄浦江南延伸段WS3单元控制性详细规划xh128D街坊部调整》公众参与草案进行公示。根据公示内容,xh128D街坊位于徐汇区斜土街道南部,黄浦江南延伸段WS3单元内。东至先丰路,西至大木桥路
- 57分钟前 小米 上海 0
-
 正版软件
正版软件
- okex怎么开通合约
- 在OKX开通合约交易的步骤:注册并验证账户激活合约交易填写申请表完成风险评估等待审核开通合约交易
- 1小时前 05:54 0
-
 正版软件
正版软件
- 揭开大型语言模型(LLM)的力量:初创企业如何通过精简集成彻底改变运营方式
- 大型语言模型(LLM)已成为各种规模企业的游戏规则改变者,但它们对初创企业的影响尤为显著。为了理解其中的原因,让我们来看看初创企业相对于老牌企业有哪些优势,以及为什么AI是它们的重要推动力。首先,与传统企业相比,初创企业有更大的灵活性。它们通常没有过多的层级和繁琐的决策程序,可以更迅速地适应市场变化和顾客需求。这种敏捷性使得初创企业能够更快地推出新产品和服务,并灵活调整战略。其次,初创企业通常更加创初创企业往往面临预算有限、时间紧迫的局面,即便是规模更大的行业参与者也可能争夺的是规模更大的行业参与者可能争
- 1小时前 05:34 人工智能 大型语言模型 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1985天前
-
 2
2
- Overture设置踏板标记的方法
- 1822天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1812天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 2010天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1976天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1972天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1987天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 2008天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00