简单实例:使用强化学习在Gym Anytrading中进行交易
 发布于2023-10-01 阅读(0)
发布于2023-10-01 阅读(0)
扫一扫,手机访问
近年来,算法交易领域对强化学习(RL)表现出了极大的兴趣。强化学习算法通过从经验中学习,并根据奖励来优化行动,非常适合用于交易机器人。在本文中,我们将简要介绍如何利用Gym Anytrading环境和GME(GameStop Corp.)交易数据集构建一个基于强化学习的交易机器人

强化学习是机器学习的一个分支,其核心是代理与环境之间的交互,以达到特定的目标。代理在环境中采取行动,并通过接收奖励的反馈来学习,以最大化累积奖励。代理的目标是找到一种最优策略,将状态映射到行动,以获得最佳的结果
Gym Anytrading
Gym Anytrading是一个基于OpenAI Gym的开源库,用于创建金融交易环境。它允许模拟不同的交易场景,并使用强化学习算法测试各种交易策略
安装依赖
要安装所需的依赖项,请运行以下代码,其中包括TensorFlow、stable-baselines3和Gym Anytrading这些主要库
!pip install tensorflow !pip install stable_baselines3 !pip install gym !pip install gym-anytrading !pip install tensorflow-gpu
导入库
导入必要的库和设置环境开始:
# Gym stuff import gym import gym_anytrading # Stable baselines - RL stuff from stable_baselines3.common.vec_env import DummyVecEnv from stable_baselines3 import A2C # Processing libraries import numpy as np import pandas as pd from matplotlib import pyplot as plt
加载GME交易数据
将使用GameStop Corp. (GME)的历史交易数据作为示例。我们假设您拥有CSV格式的GME交易数据,没有的话可以通过搜索引擎找到下载地址。
准备Gym Anytrading环境,以便加载GME交易数据
# Load GME trading data df = pd.read_csv('gmedata.csv') # Convert data to datetime type df['Date'] = pd.to_datetime(df['Date']) df.dtypes # Set Date as the index df.set_index('Date', inplace=True) df.head()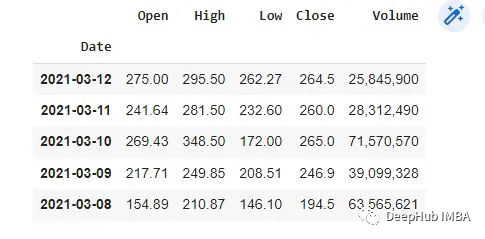
通过Gym创建交易环境
我们将使用Gym Anytrading创建一个交易环境,该环境将模拟GME交易数据,并让我们的代理通过购买、出售和持有股票等行为与环境互动
# Create the environment env = gym.make('stocks-v0', df=df, frame_bound=(5, 100), window_size=5) # View environment features env.signal_features # View environment prices env.prices探索环境
在继续构建RL模型之前,可以先对环境可视化了解其特征。
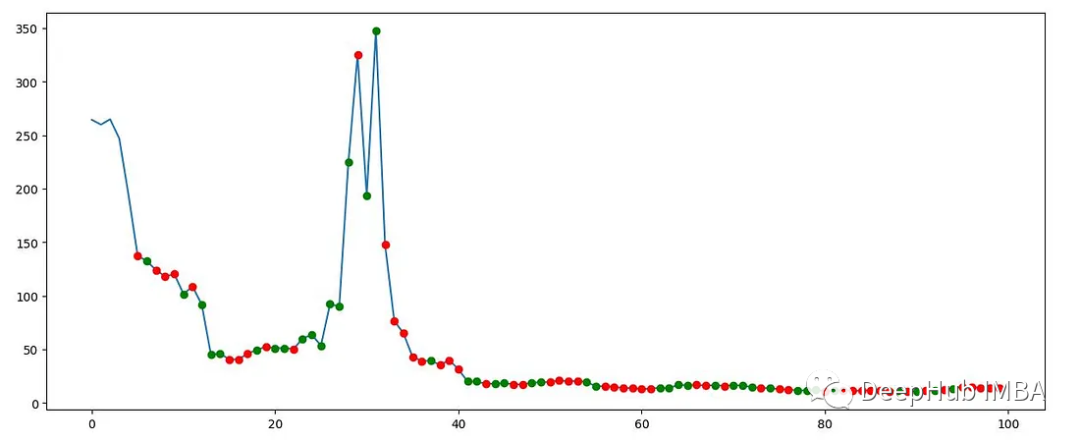
# Explore the environment env.action_space state = env.reset() while True:action = env.action_space.sample()n_state, reward, done, info = env.step(action)if done:print("info", info)break plt.figure(figsize=(15, 6)) plt.cla() env.render_all() plt.show()该图显示了GME交易数据的一部分,以及Gym Anytrading环境生成的买入和卖出信号。
构建强化学习模型
我们将采用stable-baselines3库来实现RL模型,并使用A2C(Advantage Actor-Critic)算法
# Creating our dummy vectorizing environment env_maker = lambda: gym.make('stocks-v0', df=df, frame_bound=(5, 100), window_size=5) env = DummyVecEnv([env_maker]) # Initializing and training the A2C model model = A2C('MlpPolicy', env, verbose=1) model.learn(total_timesteps=1000000)评估模型
在训练模型之后,可以评估它在GME交易数据的不同部分上的表现。
# Create a new environment for evaluation env = gym.make('stocks-v0', df=df, frame_bound=(90, 110), window_size=5) obs = env.reset() while True:obs = obs[np.newaxis, ...]action, _states = model.predict(obs)obs, rewards, done, info = env.step(action)if done:print("info", info)break plt.figure(figsize=(15, 6)) plt.cla() env.render_all() plt.show()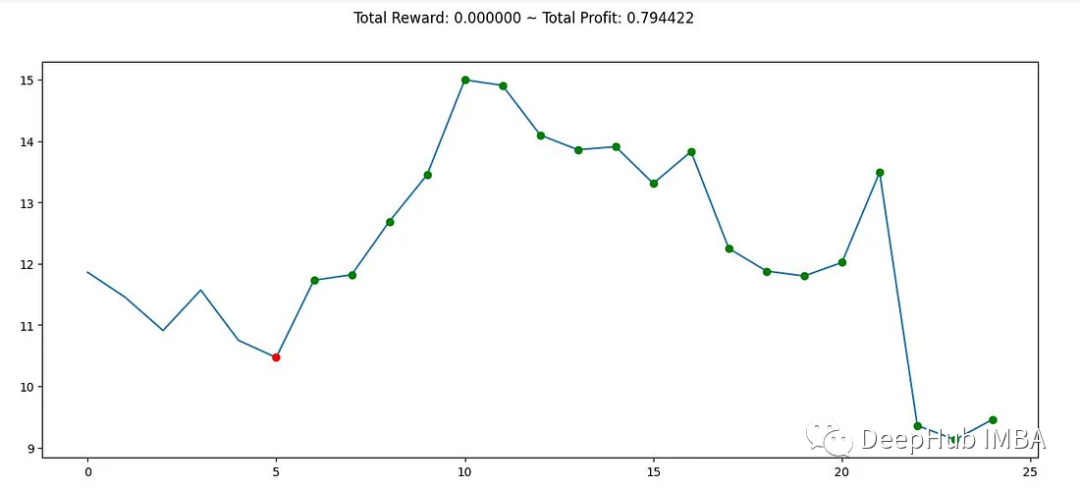
总结
本文提供了使用Gym Anytrading环境和stable-baselines3库构建强化学习交易机器人的指南,但要构建一个成功的交易机器人,需要综合考虑各种因素并进行持续改进
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 山寨币市场即将迎来“爆炸性反弹”吗?关注这三个指标就够了
- 密切关注三个技术指标的加密货币交易员表示,山寨币市场目前正处于“难以置信的阶段”,如果历史重演,可能很快就会进入“爆炸性反弹阶段”。加密货币分析师MikybullCrypto在5月11日的一篇帖子中对他们的66,600X粉丝表示:“山寨币市值目前正处于令人难以置信的阶段,从历史上看,随后会出现爆炸性反弹。”怀疑阶段是指尽管市场迹象积极,但投资者仍然持怀疑态度,过去30天加密货币恐惧和贪婪指数大幅下跌24个点就反映了这一点。目前&ldq
- 9分钟前 指标 山寨币 山寨币反弹指标 0
-
 正版软件
正版软件
- 数字货币交易平台app平台软件有哪些
- 数字货币交易平台App:探索平台软件的多样性随着区块链技术的不断发展,数字货币交易平台App成为了越来越多人参与虚拟货币交易的工具。这些平台软件的多样性不仅提供了便捷的交易环境,也为用户带来了更多选择。本文将深度分析数字货币交易平台App的不同软件类型,以及它们所提供的功能和优势。1.常用交易所App常用交易所App是常见的数字货币交易平台软件。这些平台提供了各种虚拟货币的交易对,并支持多种交易方式,如市价单、限价单等。用户可以随时查看行情、买卖数字货币,以及监控自己的交易记录。同时,这些平台往往提供安全
- 29分钟前 0
-
 正版软件
正版软件
- 如何寻找百倍币?寻找百倍币的五个关键步骤
- 不要把所有鸡蛋放同个篮子,分散投资增加命中机会!再强调一次百倍币可遇不可求,没有100%确保找到百倍币的方法,只能提高命中机率。在这点上会有一点类似创投的投资策略,投资很多间初创公司,其中多数都会失败会倒闭,投资以赔钱收场;但其中少数会成功,创投会得到数十倍、数百倍的报酬,足以承担所有其他失败的损失,最终整体为正报酬。以买到百倍币为投资目标,就不会只投资一两种币,命中机会过低,而会投资更多潜力项目来增加命中机会。五个步骤找出下个百倍币1.找出有发展潜力的赛道参考文章下一段2024重点赛道;2.在赛道中找出
- 49分钟前 百倍币 寻找百倍币技巧 0
-
 正版软件
正版软件
- inj币是交易所代币吗
- INJ币既是交易所代币,用于支付交易费用、质押获得收益和治理,也是实用型代币,用于链上衍生品交易、去中心化金融和治理。这使其成为一个多用途的加密资产,既能促进平台运营,又能为用户提供功能和价值。
- 1小时前 00:24 0
-
 正版软件
正版软件
- 怎么生成比特币钱包地址码
- 生成比特币钱包地址码只需几个步骤:选择比特币钱包(移动/台式机/硬件);安装钱包并创建新钱包;公钥会生成比特币钱包地址码;安全保管私钥,用于访问比特币。
- 1小时前 00:04 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1985天前
-
 2
2
- Overture设置踏板标记的方法
- 1822天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1812天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 2011天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1976天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1972天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1987天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 2009天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00