ABBYY Recognition Server处理文档的详细解析
 Ari 发布于2020-05-06 阅读(1792)
Ari 发布于2020-05-06 阅读(1792)
扫一扫,手机访问
ABBYY Recognition Server如何处理文档?ABBYY Recognition Server作为一种功能强大的自动识别系统,可以自动转换纸质文档、图像和电子文档,并将它们保存为压缩的归档文件,如PDF或PDF/A。ABBYY Recognition Server的自动化文档处理过程包括六个阶段,这些阶段可以在单独的工作流程中进行配置,每个工作流有其特定的设置和优先级,且彼此独立运行,本文中正软小编将具体讲讲ABBYY Recognition Server自动化处理文档的流程。
ABBYY Recognition Server处理文档的操作步骤

ABBYY Recognition Server自动化处理文档的六个阶段
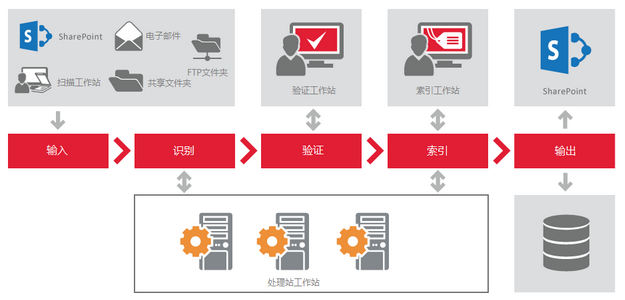
1、图像扫描/导入
图像可以由操作者在扫描站扫描后发送到Recognition Server或者通过Recognition Server从输入文件夹(网络文件夹、FTP文件夹、SharePoint库或邮箱)自动导入,该应用程序根据优先级和可用计算资源自动处理在队列中的图像文件。
作为批次扫描的图片, ABBYY Recognition Server提供几种内置文档分割方式可选:空白页、条码或者页面上的粘贴以及打印条码,同时还支持脚本方式书写以外的客户规则。
2、识别
ABBYY Recognition Server的OCR识别是在处理站自动运行的。如果同时安装多个处理站在系统中,这些文件将这些处理站之间均匀分布,以获得高性能,安装多个处理站能够加快OCR识别速度。
ABBYY Recognition Server的OCR和条码识别技术提供了无与伦比的精确性,支持多种类型文本,以及流行的1D/2D条码。Recognition Server支持198多种语言,包括拉丁文、西里尔文、希腊和其他脚本,中文、日语、韩语、越南语、希伯来语、意第绪语和泰国等,欧洲的古体语言也支持。
为保留文档版面, ABBYY Recognition Server使用Adaptive Document Recognition Technology (ADRT)技术,在保存成DOC和RTF时很好地保留文档的原始版面,包括页眉、页脚、表格内容等。
3、验证(可选)
在某些情况下,例如书籍数字化时,验证识别结果可能是必要的。验证站能够让操作者检查所有的文件或者只检查低于一定精确度的文件。
4、文件分离(可选)
执行批量扫描或导入的时候,将涉及到文件分离。文件可以用空白分隔页,条形码或每个文档页面固定数目分开的,分离也可以根据脚本规则进行。
5、分类和索引(可选)
ABBYY Recognition Server是一个强大的索引软件。文件索引可以通过脚本自动完成或者由操作员在索引站手动选择文件类型并指定文件属性,操作员也可以检验由脚本自动导出的数据。文档类型的探测、分类和索引可以通过Java或者VB自动实现。
6、发布
文件处理的最后阶段,ABBYY Recognition Server将文件输出到其最终储存处(网络文件夹、SharePoint文件库或电子邮件)。此外,输出的文件还可以应用于智能路由或发送至基于文档属性和特性的ECM系统。
识别服务器可以将图片转换成不同的可搜索的文件格式:PDF、PDF/A、RTF、TXT、DOC(X)、XLS(X)、XML。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【标准版 + Win】
-
¥1058.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Mac】
-
¥899.00
office旗舰店
-

售后无忧
立即购买>- ABBYY FineReader 14 简体中文【企业版 + Win】
-
¥1858.00
office旗舰店
-
售后无忧
立即购买>- ABBYY FineReader 12 简体中文【专业版 + Win】
-
¥508.00
office旗舰店
-
 正版软件
正版软件
- 中国万方数据库官网入口 万方数据库在线平台登录地址
- 万方数据库官网为https://www.wanfangdata.com.cn,提供期刊、外文文献、地方志视频及行业知识等资源。平台支持多维检索、双格式全文阅读与知识图谱构建,并具备七种参考文献导出功能。注册用户享有每日下载额度,机构用户可通过IP认证获取更多权限。其专题库在民俗文化、科学数据等领域资源深入,助力学术研究。
- 13小时前 16:20 0
-
 正版软件
正版软件
- XYplorer怎么显示文件大小_XYplorer文件夹大小统计教程【实用】
- XYplorer可通过多种方式显示文件夹大小。在列表视图中全局启用显示功能,可使每个文件夹旁实时显示容量与项目数。通过工具栏砝码按钮可快速扫描当前目录。右键点击Size列标题可直接启用动态显示功能。选中文件夹后,状态栏会即时显示其递归统计的总大小与项目数。
- 13小时前 16:20 0
-
 正版软件
正版软件
- 前程无忧招聘网行业招聘查询入口 前程无忧招聘网分类岗位检索入口
- 前程无忧招聘网提供行业与岗位检索功能,支持按大类与标签筛选、查看岗位热力图与成长路径。智能检索可通过自然语言或分类导航进行,高级搜索可排除非意向标签。招聘地图展示地域岗位及通勤建议,企业看板呈现资质与运营指标。移动端支持岗位订阅与静默推送,便于高效获取机会。
- 13小时前 16:20 0
-
 正版软件
正版软件
- 微信文件传输助手如何发送原图_图片不被压缩的方法【画质】
- 微信传输图片时默认压缩画质,可通过五种方法发送原图。勾选“原图”开关直接上传;使用“文件”入口跳过图像处理;电脑端拖拽文件实现无损传输;利用“收藏”功能作为高清中转站;或将图片打包为ZIP压缩包发送,彻底避免压缩。这些方法能保留原始分辨率、格式及元数据。
- 13小时前 16:19 0
-
 正版软件
正版软件
- 面向对象:classdef如何构建简单的类与对象实现代码模块化
- classdef是MATLAB中定义类的关键字,用于封装属性和方法。通过定义类、实例化对象、设置私有属性与访问控制,以及定义静态方法,可以实现代码的模块化,有效提升程序的复用性、可读性和可维护性。
- 14小时前 16:18 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 260天前
-
 2
2
- 动漫共和国官网入口在线看
- 241天前
-
 3
3
- 高德地图是哪个国家开发的?
- 316天前
-
 4
4
- 51漫画高清入口及最新章节更新
- 109天前
-
 5
5
- 拷贝漫画最新官网入口2025
- 149天前
-
 6
6
- 如何找到192.168.0.1登录入口
- 369天前
-
 7
7
- yy漫画下拉式免费阅读官网入口
- 239天前
-
 8
8
- 2020美团外卖账单报告入口详解
- 258天前
-
 9
9
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 277天前
相关推荐
热门关注
-
- ABBYY FineReader 12 简体中文
- ¥508.00-¥1008.00
-
- ABBYY FineReader 12 简体中文
- ¥899.00-¥1199.00
-
- ABBYY FineReader 14 简体中文
- ¥1058.00-¥1299.00
-
- ABBYY FineReader 14 简体中文
- ¥1858.00-¥2415.00