榕树集AlphaFold更新详解
 发布于2025-06-25 阅读(0)
发布于2025-06-25 阅读(0)
扫一扫,手机访问
 前言首先,AlphaFold在单体蛋白质预测领域取得了突破性的进展。接着,AlphaFold-Multimer将这一技术扩展到了蛋白质复合物的预测。现在,AlphaFold再次更新,推出了被称为AlphaFold-latest的新版本。
前言首先,AlphaFold在单体蛋白质预测领域取得了突破性的进展。接着,AlphaFold-Multimer将这一技术扩展到了蛋白质复合物的预测。现在,AlphaFold再次更新,推出了被称为AlphaFold-latest的新版本。
AF模型的更新主要集中在以下两个方面:
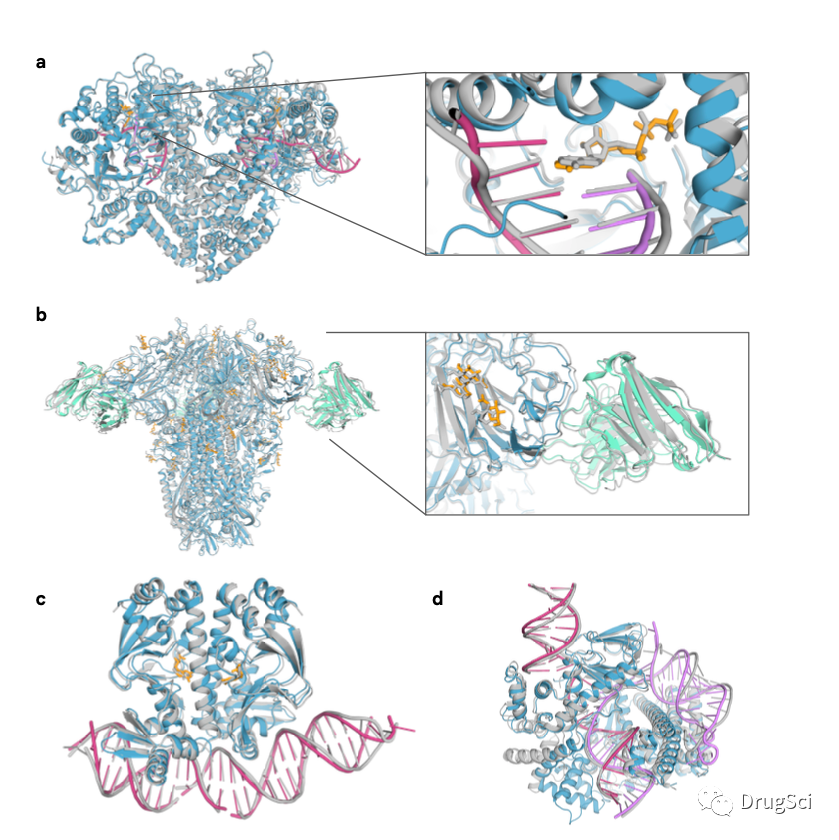
在准确度上取得了显著提升:最新版本的模型能够实现原子级别的预测,涵盖了所有的PDB结构。预测范围的扩大:AF对多种关键生物分子的理解有了新的进展,包括小分子配体、蛋白质、核酸(DNA和RNA)以及翻译后修饰(PTMs)的分子。这意味着AF不仅限于预测蛋白质本身,还可以用于预测其他生物分子复合物。AlphaFold-latest的结构预测与实验结构的比较:蛋白质链以蓝色显示(抗体以绿色显示),橙色表示预测的配体和糖,粉色表示预测的DNA,紫色表示预测的RNA,灰色表示实际结构。
a. RNA聚合酶QDE-1与RNA引物和非水解核苷酸AMPNPP结合(PDB ID 7Y7S,LDDT:87.9)。
b. 人类冠状病毒OC43刺突蛋白,4665个残基,糖基化并与中和抗体结合(PDB ID 7PNM,LDDT:83.3)。
c. 细菌CRP/FNR家族转录调节蛋白与DNA和cGMP结合(PDB ID 7PZB,LDDT:82.4)。
d. CRISPR-Casλ蛋白与CRISPR-RNA和DNA复合物(PDB ID 8DC2,LDDT:76.7)。
 一些性能测试数据从四个方向展示了AF-latest的表现:
一些性能测试数据从四个方向展示了AF-latest的表现:
蛋白质-小分子复合物预测:在PoseBusters基准测试集中,AlphaFold-latest的表现超过了AutoDock Vina等传统对接模型。尽管基准数据集提供了实际的蛋白复合物三维结构信息,AF-latest的出发点却是从一维序列开始。蛋白质-蛋白质结构预测方面:AF-latest在某些类别中,如抗体结合结构,表现出显著提升。蛋白质-核酸复合物预测方面:AlphaFold-latest优于竞争系统,但在RNA结构预测方面,略逊于使用专家手动调优干预的CAS15 Top(AIchemy_RNA2)。AlphaFold-latest能够预测一些额外的实体类型,如化合配体、糖基化和修饰过的残基或核苷酸。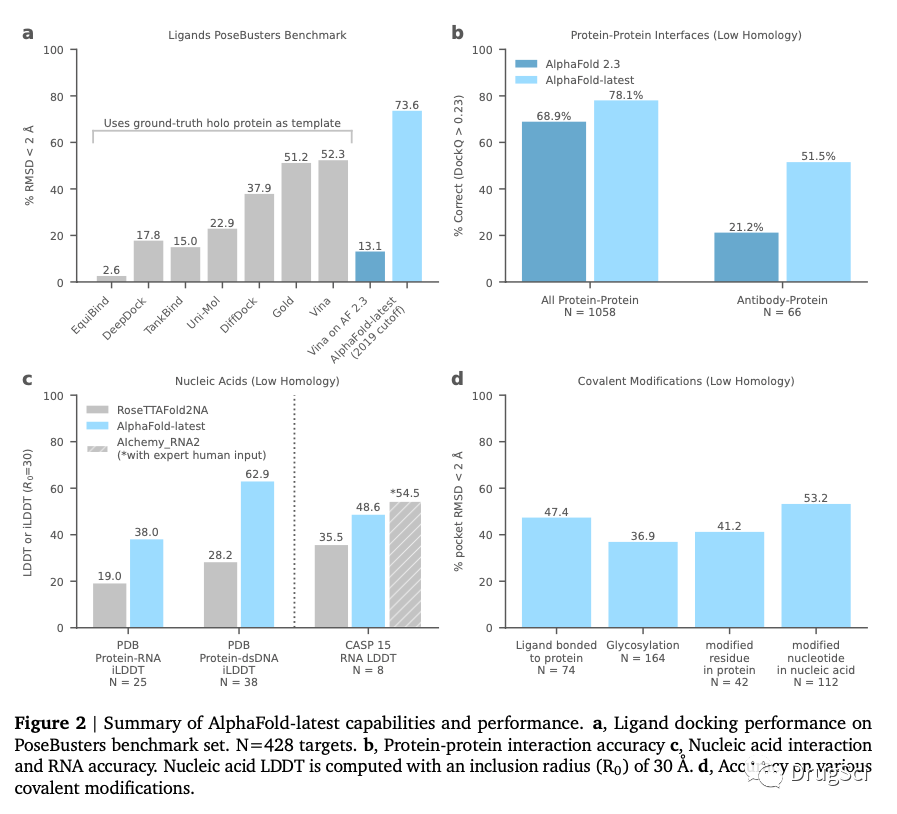 模型输入和输出AlphaFold-latest接受生物组装的描述作为输入,包括序列和配体的SMILES,以及共价配体的序列位置(可选),并输出每个重原子的3D位置预测。水分子和氢原子不包括在内。用于训练模型的实验结构均来自PDB。
模型输入和输出AlphaFold-latest接受生物组装的描述作为输入,包括序列和配体的SMILES,以及共价配体的序列位置(可选),并输出每个重原子的3D位置预测。水分子和氢原子不包括在内。用于训练模型的实验结构均来自PDB。
输入被“tokenized”以获取模型输入,每个氨基酸残基使用一个token表示,配体和非标准氨基酸残基的每个重原子采用一个token表示。token数量是影响计算时间的主要因素,当然也是在不同硬件上预测复合物大小的主要因素。为了计算方便,系统最多评估过带有5120个标记的复合物的性能。当然,如果你的硬件内存足够大,也可以预测更大的复合物。
与DiffDock这一个机器学习方法相比,AlphaFold-latest在PoseBusters测试结果中表现出极大的优势。
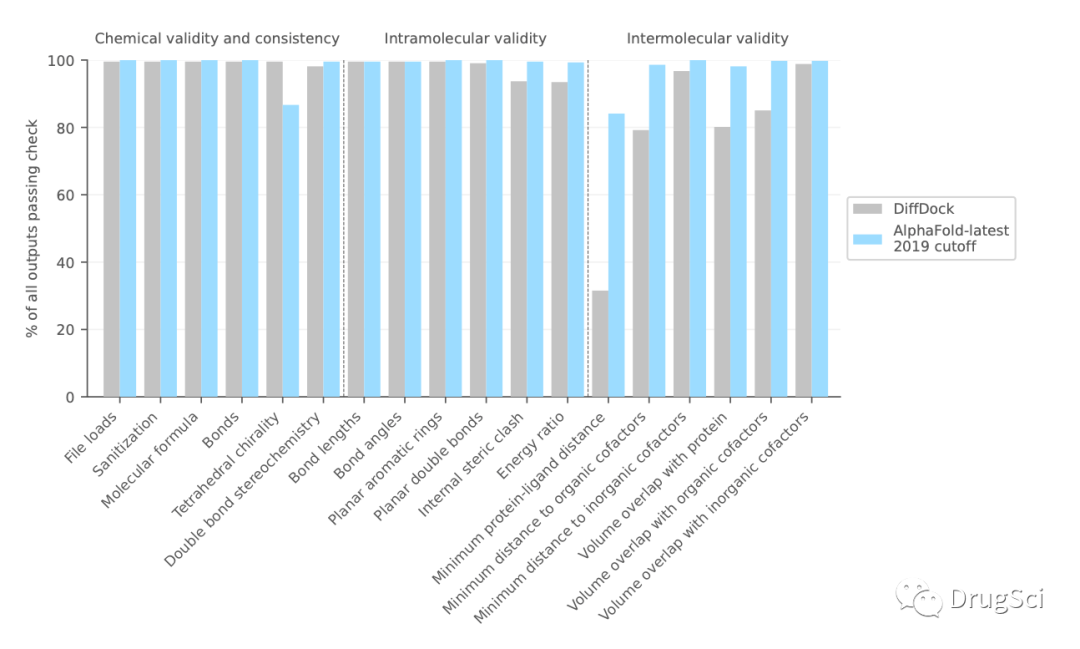 LigandAF-latest的优势主要体现在以下几个方面:
LigandAF-latest的优势主要体现在以下几个方面:
成功率高(RMSD < 2Å)。总的来看,基于传统算法的分子对接程序可能会逐渐进入一个沉寂期。AF-latest使用的是预测方法,而不是对接。共价,离子,诱导契合,膜蛋白等需要构建特殊力场/函数/算法的领域,将迎来AF以及相关AI模型的冲击。
然而,截至目前,我在Google上尚未找到此版本的更新:https://github.com/google-deepmind/alphafold
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
下一篇:读写锁特点及适用场景分析
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 4999 元起!AI影像、半固态锂电上车,雅迪冠能普及「车规级」体验
- 真正的智能骑行必须化繁为简。
- 6小时前 16:27 0
-
 正版软件
正版软件
- 突破16万辆!问界M8以硬核实力书写春季出游“全能答卷”
- 突破16万辆!问界M8以硬核实力书写春季出游“全能答卷”
- 前天 03-21 12:47 0
-
 正版软件
正版软件
- 岚图泰山黑武士太敢测!胡军坐副驾惊出15个表情包
- 岚图泰山黑武士太敢测!胡军坐副驾惊出15个表情包
- 3天前 0
-
 正版软件
正版软件
- 新豪华智慧旗舰轿车昊铂A800上市,补贴后16.48万元起
- 一款诚意之作。
- 5天前 0
-
 正版软件
正版软件
- 鸿蒙智行问界M6活力橙官图公布:高饱和度纳米色浆搭配高亮铝粉
- 问界M6推全新活力橙配色,提供7种车色,搭载激光雷达等配置,增程版纯电续航达180-272km,今春发布。
- 5天前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 485天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 492天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 503天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 795天前
-
 6
6
-
 7
7
- 骁龙芯片的型号与天玑9400相当?
- 511天前
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2289天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00