字节跳动Doris湖仓分析实践分享
 发布于2025-06-27 阅读(0)
发布于2025-06-27 阅读(0)
扫一扫,手机访问
 分享嘉宾:杜军令 字节跳动 大数据工程师
分享嘉宾:杜军令 字节跳动 大数据工程师
出品平台:DataFunTalk
导读:Doris是一种基于MPP架构的分析型数据库,主要用于多维分析、数据报表和用户画像分析等场景。它自带分析引擎和存储引擎,支持向量化执行引擎,无需依赖其他组件,并兼容MySQL协议。
01
Doris概述
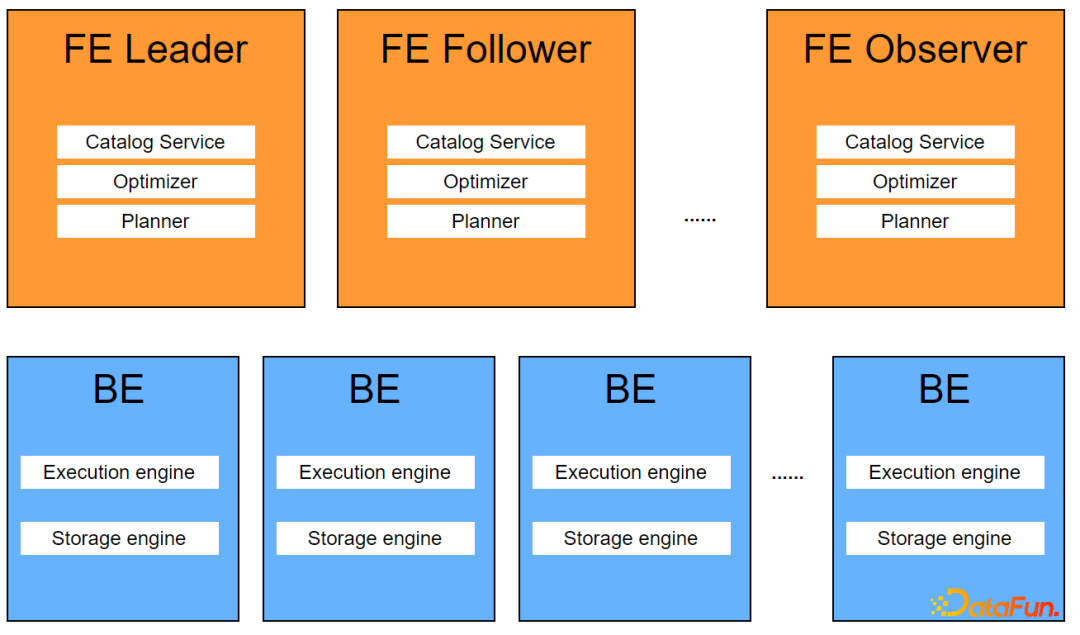
Apache Doris具有以下特点:
优化的架构设计,支持高并发和低延迟的查询服务,适合高吞吐量的交互式分析。多FE节点均可对外提供服务,随着并发需求增加,通过线性扩展FE和BE节点即可满足高并发查询需求。支持批量和流式数据加载,支持数据更新。支持Update/Delete语法,unique/aggregate数据模型,支持动态更新数据,实时更新聚合指标。提供高可用性、容错处理和高扩展性的企业级功能。FE Leader出现异常时,FE Follower可在几秒内切换为新Leader,继续对外提供服务。支持聚合表和物化视图。多种数据模型,支持aggregate, replace等多种数据模型,支持创建rollup表和物化视图。rollup表和物化视图支持动态更新,无需用户手动处理。兼容MySQL协议,支持直接使用MySQL客户端连接,数据应用对接非常便捷。Doris由Frontend(简称FE)和Backend(简称BE)组成,FE负责接受用户请求、编译、优化、分发执行计划、元数据管理以及BE节点的管理等功能,BE则负责执行FE下发的执行计划,存储和管理用户数据。
 02
02
数据湖格式Hudi简介
Hudi是下一代流式数据湖平台,为数据湖提供了表格式管理能力,支持事务、ACID、MVCC、数据更新删除和增量数据读取等功能。支持Spark, Flink, Presto, Trino等多种计算引擎。
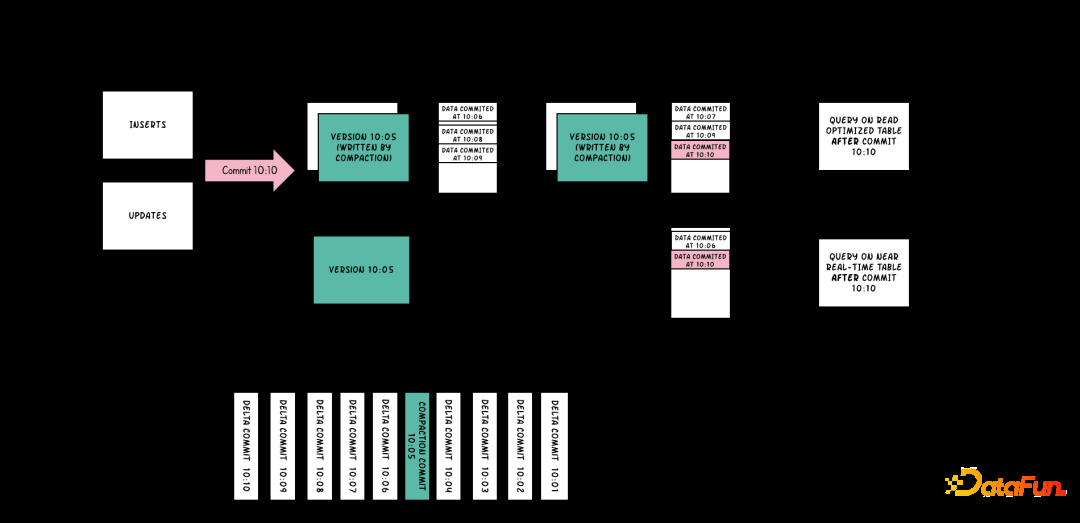 Hudi根据数据更新行为分为两种表类型:
Hudi根据数据更新行为分为两种表类型:
 针对Hudi的两种表格式,有三种不同的查询类型:
针对Hudi的两种表格式,有三种不同的查询类型:
 03
03
Doris分析Hudi数据的技术背景
随着业务对数据实时性要求的提高,数仓业务从T+1逐渐演变为小时级、分钟级,甚至秒级。实时数仓的应用范围也在扩大,并经历了多个发展阶段。目前有多种解决方案。
1. Lambda架构
Lambda架构将数据处理流分为在线分析和离线分析两条路径,两条路径相互独立,互不影响。
离线分析处理T+1数据,使用Hive/Spark处理大数据量,不可变数据,数据通常存储在HDFS等系统上。如果需要更新数据,必须overwrite整张表或整个分区,成本较高。
在线分析处理实时数据,使用Flink/Spark Streaming处理流式数据,分析处理秒级或分钟级流式数据,数据保存在Kafka或定期(分钟级)保存到HDFS中。
该方案存在以下缺点:
同一套指标可能需要开发两套代码分别进行在线和离线分析,维护复杂。数据应用查询指标时可能需要同时查询离线和在线数据,开发复杂。需要同时部署批处理和流式计算两套引擎,运维复杂。数据更新需要overwrite整张表或分区,成本高。2. Kappa架构
随着在线分析业务的增加,Lambda架构的缺点愈发明显,增加一个指标需要分别开发在线和离线版本,维护困难,离线指标可能与在线指标不一致,部署复杂,组件繁多。因此,Kappa架构应运而生。
Kappa架构使用一套架构处理在线和离线数据,使用同一套引擎同时处理在线和离线数据,数据存储在消息队列上。
Kappa架构也存在一些限制:
流式计算引擎的批处理能力较弱,处理大数据量性能较差。数据存储使用消息队列,消息队列对数据存储有有效性限制,无法回溯历史数据。数据时序可能乱序,可能对时序要求严格的应用造成数据错误。数据应用需要从消息队列中取数,开发复杂,需要开发适配接口。3. 基于数据湖的实时数仓
针对Lambda架构和Kappa架构的缺陷,业界基于数据湖开发了Iceberg, Hudi, DeltaLake等数据湖技术,使得数仓支持ACID, Update/Delete,数据Time Travel, Schema Evolution等特性,数仓的时效性从小时级提升到分钟级,数据更新也支持部分更新,大大提高了数据更新的性能。兼具流式计算的实时性和批计算的吞吐量,支持近实时场景。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:Kimi制作PPT教程及技巧分享
下一篇:御龙在天装备签名怎么签
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 次元城app下载的文件在哪-下载文件位置
- 次元城app下载的文件在哪,在软件首页选择想观看的动漫,如《我推的孩子第二季》,进入播放页面,点击简介下方“下载”标识(如图片圈注处)。自由勾选单集或选择“全部下载”,点击“下载队列”进入“我的下载”
- 2小时前 21:12 0
-
 正版软件
正版软件
- samhelper怎么测气密性-samhelper测气密性最简单方法
- 使用 SamHelper 检测手机气密性,需打开软件进入测试页面,启动后双指按压屏幕观察气压数值变化。正常状态下,气压基准值约为 1010 左右,按压时数值应有 3-10 左右的波动 。
- 2小时前 21:09 0
-
 正版软件
正版软件
- 白羊影视app怎么使用-使用指南
- 白羊影视app怎么使用,用户在本站下载安装好软件,点击手机桌面图标,打开app,在首页中点击格式转换的功能,选择你想要转换的格式视频导入软件中,选择要转换的格式,然后点击开始转换。
- 2小时前 21:06 0
-
 正版软件
正版软件
- 白羊影视app怎么投屏-投屏教程
- 白羊影视app怎么投屏,首先用手机打开app,然后找到自己想要观看的视频,然后点击屏幕上面的tv功能,然后就会出现搜索投屏机器的蓝牙地址,点击配对,然后成功以后,即可进行投屏操作。
- 2小时前 21:03 0
-
 正版软件
正版软件
- 叮当魔盒app有什么功能-使用指南
- 叮当魔盒app有什么功能,使用手机号码登陆叮当魔盒app,在APP首页滑动盲盒款式,点击“查看宝贝”可详细查看商品明细和抽取概率,选中一款心仪的盲盒,点击“立即开盒”即可进行抽取。
- 2小时前 21:00 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 216天前
-
 2
2
- 高德地图是哪个国家开发的?
- 273天前
-
 3
3
- 如何找到192.168.0.1登录入口
- 326天前
-
 4
4
- 拷贝漫画最新官网入口2025
- 106天前
-
 5
5
- yy漫画下拉式免费阅读官网入口
- 196天前
-
 6
6
- 51漫画高清入口及最新章节更新
- 65天前
-
 7
7
- 2020美团外卖账单报告入口详解
- 214天前
-
 8
8
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 233天前
-
 9
9
- 动漫共和国官网入口在线看
- 197天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00