Windows 8配置Eclipse与Hadoop2.2.0环境指南
 发布于2025-07-27 阅读(0)
发布于2025-07-27 阅读(0)
扫一扫,手机访问
图文详解如何在Windows 8.0上的Eclipse 4.4.0中配置CentOS 6.5上的Hadoop 2.2.0开发环境,供有需要的朋友参考学习。
Eclipse的Hadoop插件下载地址:https://github.com/winghc/hadoop2x-eclipse-plugin
下载压缩包后,解压并将hadoop-eclipse-kepler-plugin-2.2.0.jar文件放置到Eclipse的dropins目录中,重启Eclipse即可。
进入Windows -> Preferences配置根目录。
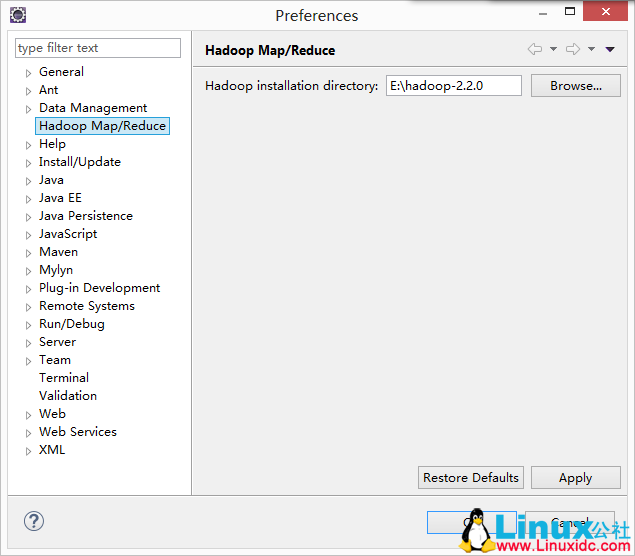 ,这里的hadoop installation directory不是指你在Windows上安装的Hadoop目录,而是你在CentOS上编译好的源码在Windows上的解压路径。这个路径仅用于创建MapReduce项目时自动引入所需的jar文件。
,这里的hadoop installation directory不是指你在Windows上安装的Hadoop目录,而是你在CentOS上编译好的源码在Windows上的解压路径。这个路径仅用于创建MapReduce项目时自动引入所需的jar文件。
进入Window -> Open Perspective -> Other -> Map/Reduce,打开Map/Reduce窗口。
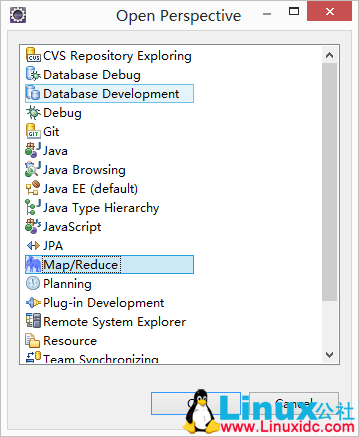 找到
找到
 ,右击选择New Hadoop location,这时会出现
,右击选择New Hadoop location,这时会出现
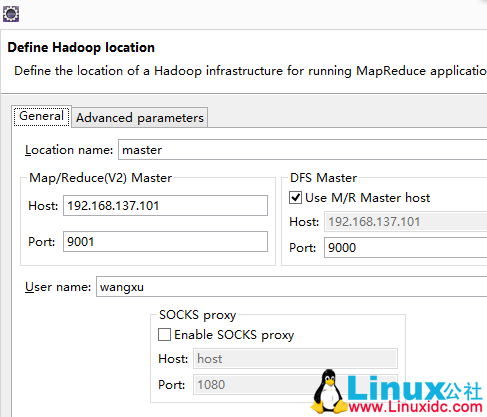 Map/Reduce(V2)中的配置对应于mapred-site.xml中的端口配置,DFS Master中的配置对应于core-site.xml中的端口配置,配置完成后点击finish即可。这时可以查看
Map/Reduce(V2)中的配置对应于mapred-site.xml中的端口配置,DFS Master中的配置对应于core-site.xml中的端口配置,配置完成后点击finish即可。这时可以查看
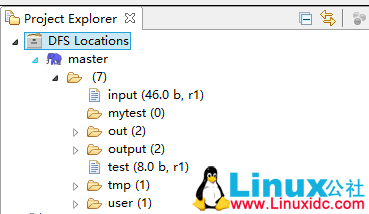 进行测试,创建一个新的MapReduce项目,
进行测试,创建一个新的MapReduce项目,
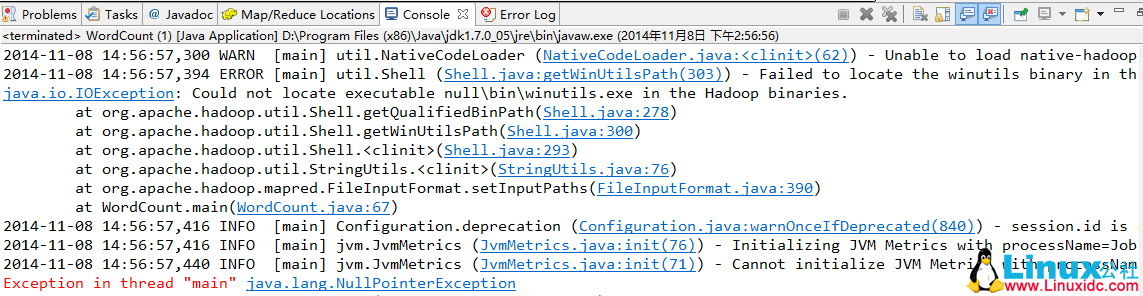 ,要解决这个问题,你需要在Windows上配置HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中。然后从https://github.com/srccodes/hadoop-common-2.2.0-bin下载文件,下载后将bin目录中的内容全部复制到你自己在Windows上的Hadoop bin目录中,覆盖即可。同时,将hadoop.dll添加到C盘的system32目录中。如果完成这些步骤后仍然遇到“Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z”,请检查你的JDK版本,可能是由于使用了32位JDK导致的,需要下载并安装64位JDK,并在Eclipse中将JRE环境配置为新安装的64位JRE。
,要解决这个问题,你需要在Windows上配置HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中。然后从https://github.com/srccodes/hadoop-common-2.2.0-bin下载文件,下载后将bin目录中的内容全部复制到你自己在Windows上的Hadoop bin目录中,覆盖即可。同时,将hadoop.dll添加到C盘的system32目录中。如果完成这些步骤后仍然遇到“Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z”,请检查你的JDK版本,可能是由于使用了32位JDK导致的,需要下载并安装64位JDK,并在Eclipse中将JRE环境配置为新安装的64位JRE。
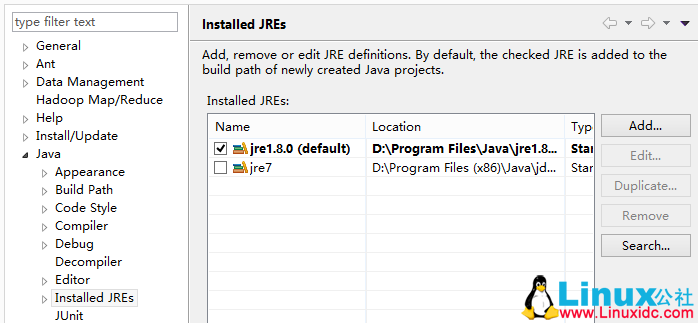 。比如我的jre1.8是64位,而jre7是32位,如果列表中没有你需要的JRE,直接点击add添加即可,选择你的64位JRE环境后,问题就会解决。
。比如我的jre1.8是64位,而jre7是32位,如果列表中没有你需要的JRE,直接点击add添加即可,选择你的64位JRE环境后,问题就会解决。
接下来编写一个wordcount程序进行测试,下面是我的代码,前提是你已经在HDFS上创建了input文件,并在其中放置了一些内容:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// System.setProperty("hadoop.home.dir", "E:\\\\hadoop2.2\\\\");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
// if (otherArgs.length != 2) {
// System.err.println("Usage: wordcount <in><out>");
// System.exit(2);
// }
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://master:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/output"));
boolean flag = job.waitForCompletion(true);
System.out.print("SUCCEED!" + flag);
System.exit(flag ? 0 : 1);
System.out.println();
}
}
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:PHP数据库备份恢复方法详解
下一篇:PHP商品推荐模块开发指南
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 幻世仙途境界怎么提高-境界提升途径
- 幻世仙途境界是游戏核心,元灵前期主要通过挖宝、主线、锁妖塔和元灵兽潮获取,兽潮建议每日买满并留到最后战力最高时打,收益最大化。彩色体质对元灵提升大,零氪可慢慢攒。灵池吃丹要升满等级再用加速,推荐购买灵
- 8分钟前 0
-
 正版软件
正版软件
- 球球旅行记纽约航空怎么过-纽约航空攻略
- 球球旅行记纽约航空怎么过,欢迎乘坐纽约航空,纽约有只两道主菜,面包和牛肉,非常友好。纽约和伦敦是游戏中相当重要的两张地图,因为通关后就可以实现金币自由了!《球球旅行记》纽约
- 11分钟前 0
-
 正版软件
正版软件
- 绿梦时空之声潘娜西娅怎么样-潘娜西娅介绍
- 绿梦时空之声潘娜西娅怎么样?侵蚀管理局对于人类而言,这其实就是存续的最后屏障,后勤部的负责人员潘纳西亚就成为了最坚定的存在。今天就为大家来分享一下绿梦时空之声潘娜西娅背景。看一下这到底是一个什么样的角
- 14分钟前 0
-
 正版软件
正版软件
- 球球旅行记伦敦航空怎么过-伦敦航空攻略
- 球球旅行记伦敦航空怎么过,欢迎乘坐伦敦航空,说实话,这玩意除了便宜一无是处,难死了(划掉)在这里,你将面临豆子和薯条的双重考验,还有可恶的面包。如果你还没有通过,那么不妨看看下文建议。
- 17分钟前 0
-
 正版软件
正版软件
- 球球旅行记新手怎么玩-平民及微氪萌新玩家攻略
- 球球旅行记新手怎么玩,作为烹饪游戏,这个游戏不是普通的给每个饿鬼吃饭,而是要赚钱,钱赚满了就通关了,所以喂了所有饿鬼都不一定通关。那怎么赚钱呢,就是让食物贵一点,下面就为大家带来一些个人的心得理解。
- 19分钟前 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 216天前
-
 2
2
- 高德地图是哪个国家开发的?
- 272天前
-
 3
3
- 如何找到192.168.0.1登录入口
- 326天前
-
 4
4
- 拷贝漫画最新官网入口2025
- 105天前
-
 5
5
- yy漫画下拉式免费阅读官网入口
- 195天前
-
 6
6
- 51漫画高清入口及最新章节更新
- 65天前
-
 7
7
- 2020美团外卖账单报告入口详解
- 214天前
-
 8
8
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 233天前
-
 9
9
- 动漫共和国官网入口在线看
- 197天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00