汉王PDF OCR使用方法详解
 发布于2025-09-05 阅读(50)
发布于2025-09-05 阅读(50)
扫一扫,手机访问
在日常生活中,我们经常会遇到PDF格式的文档资料。从网络上下载的PDF文件中,有些可以正常复制内容,但有些由于经过转曲处理(文字被转换成图片形式),导致无法直接复制,或者复制后只能得到图片。对于文字较多的PDF文档,手动重新输入非常耗时。此时,我们需要借助识别工具来解决问题。以下将详细介绍汉王PDF OCR的具体使用方法。
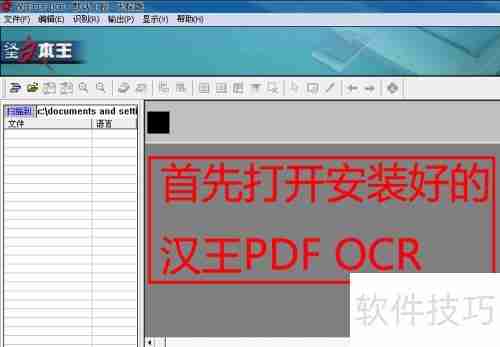
1、首先,启动已安装的汉王PDF OCR软件,如图所示。
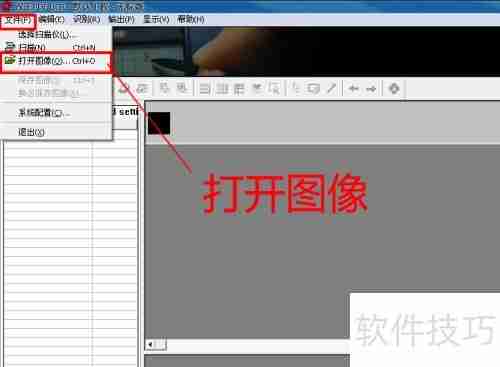
2、依次点击文件菜单中的图像选项(或使用快捷键Ctrl+O),操作如图所示。
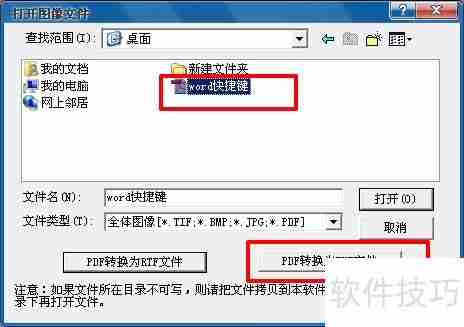
3、在弹出的打开图像文件窗口中,直接选择PDF文件,此时下方的pdf转换为TXT文件选项会从灰色变为可用的黑色。点击此选项即可导出txt文件。请注意,此方法适用于高质量的PDF文件,若文件质量较差,直接使用可能会导致较高的识别误差。
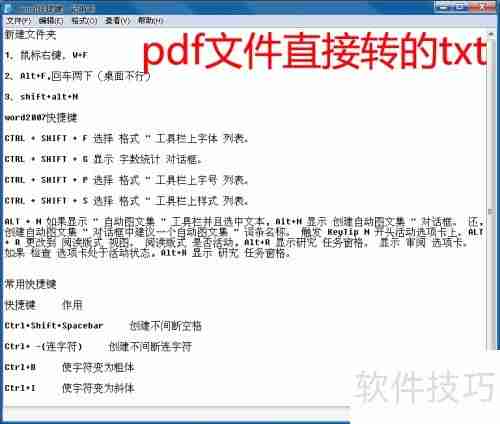
4、如果PDF文件质量较差,直接选中文件后点击打开,按照下图操作:
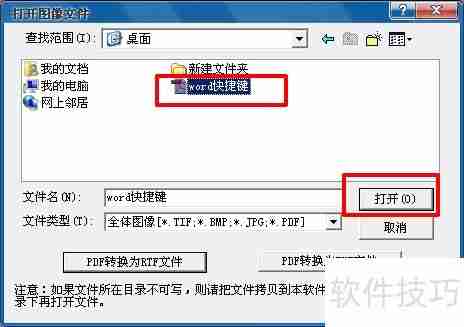
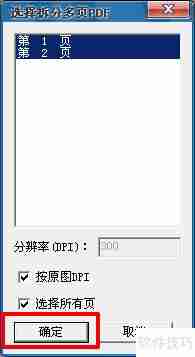
5、若PDF为多页,会弹出选择拆分多页PDF的窗口,选取需要复制文字的页码(也可以全选),点击确定。
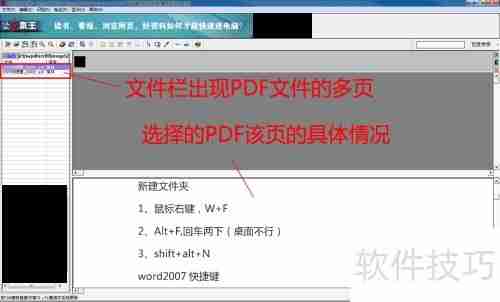
6、打开后,文件栏会显示该文件,下方框内呈现PDF页面详情,如图所示。
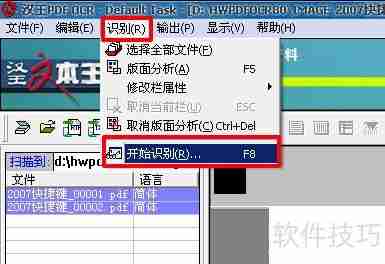
7、选中需要转换的PDF文件页(或全选),点击工具栏中的识别选项,然后选择开始识别(或按F8)。
8、当前,界面上方会显示正在识别的提示,识别结束后,结果将显示在相同位置。如果PDF文件的清晰度不足,可能会出现部分错误,可以手动进行修改,如图所示:
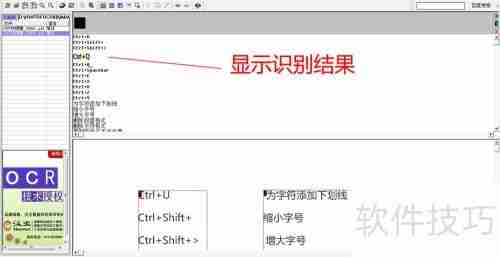
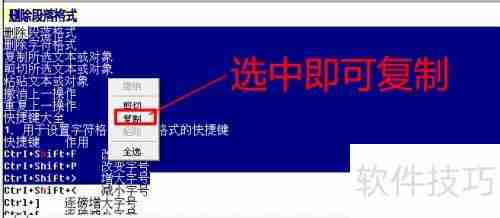
9、在界面顶部的识别结果框中,选中所需文字,右击鼠标选择复制,即可粘贴使用,如图所示。
本文转载于:https://soft.zol.com.cn/979/9792027.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Chrome浏览器下载加速与网络优化操作创新方法解析
- Chrome浏览器下载可加速优化。教程解析创新操作方法,包括网络设置、任务管理和下载优化技巧,帮助用户实现高速稳定下载,提高使用效率。
- 3小时前 13:31 0
-
 正版软件
正版软件
- Chrome浏览器下载安装包下载渠道安全性分析
- 分析Chrome浏览器下载安装包的不同下载渠道安全性,比较官方与第三方渠道优缺点,帮助用户选择安全可靠的下载来源。
- 3小时前 13:22 0
-
 正版软件
正版软件
- google浏览器下载安装及浏览器插件批量安装快速操作教程
- google浏览器提供插件批量安装快速操作教程,用户可一次性启用或卸载多个插件,实现高效扩展管理和操作便捷性。
- 3小时前 13:13 0
-
 正版软件
正版软件
- google浏览器高级操作隐藏方法
- google浏览器高级操作隐藏方法持续优化,本文章详细解析功能操作技巧、应用场景及使用方法,帮助用户高效操作浏览器并提升效率。
- 3小时前 13:04 0
-
 正版软件
正版软件
- google Chrome浏览器启动优化方法实际有效吗
- google Chrome浏览器的启动优化方法是否真的有效,一直是用户关注的问题。文章通过实测分析不同优化方式的效果,帮助用户判断操作是否能带来明显提升。
- 3小时前 12:54 0
最新发布
-
 1
1
- 《抖音》充值抖币官网入口
- 478天前
-
 2
2
- 大麦网官网订票入口
- 373天前
-
 3
3
- 直接点击打开漫蛙网页版
- 488天前
-
 4
4
- 天堂漫画免费入口及最新观看链接
- 160天前
-
 5
5
- 喵趣漫画官网
- 480天前
-
 6
6
- B站免费入口长期可用指南
- 221天前
-
 7
7
- 中国裁判文书网官网入口查询
- 148天前
-
 8
8
- 次元城动漫官网入口
- 440天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00