C++模板实现泛型工具函数方法
 发布于2025-10-19 阅读(0)
发布于2025-10-19 阅读(0)
扫一扫,手机访问
C++模板通过template<typename T>实现泛型工具函数,编译时生成特定类型版本,提升代码复用性、类型安全与性能;结合Concepts或SFINAE可进行类型约束与编译期检查,避免运行时错误,增强可维护性。

C++模板是实现泛型工具函数的关键机制,它允许我们编写与特定数据类型无关的代码,从而在编译时生成针对不同类型的特定函数版本,极大地提高了代码的复用性和灵活性。通过模板,我们能够构建出能够处理各种数据类型,同时又保持类型安全和高性能的通用功能模块。
解决方案
要使用C++模板实现泛型工具函数,核心在于定义一个函数模板。这通常涉及在函数声明前加上template <typename T> 或 template <class T>,其中T是一个类型参数,代表了函数将要操作的任意数据类型。编译器会在函数被调用时,根据传入的实际参数类型来推导出T的具体类型,并自动生成(实例化)一个针对该类型的函数版本。
举个最简单的例子,我们想写一个能比较任意两种相同类型值大小并返回较大值的函数:
#include <iostream>
#include <string> // 引入string以便测试
// 泛型最大值函数模板
template <typename T>
T myMax(T a, T b) {
// 这里使用了三元运算符,简单明了
return (a > b) ? a : b;
}
// 另一个泛型函数示例:交换两个变量的值
template <typename U>
void mySwap(U& a, U& b) {
U temp = a;
a = b;
b = temp;
}
int main() {
// 测试myMax
int i1 = 5, i2 = 10;
std::cout << "Max of " << i1 << " and " << i2 << " is: " << myMax(i1, i2) << std::endl; // 实例化为myMax<int>
double d1 = 3.14, d2 = 2.71;
std::cout << "Max of " << d1 << " and " << d2 << " is: " << myMax(d1, d2) << std::endl; // 实例化为myMax<double>
std::string s1 = "apple", s2 = "banana";
std::cout << "Max of \"" << s1 << "\" and \"" << s2 << "\" is: " << myMax(s1, s2) << std::endl; // 实例化为myMax<std::string>
std::cout << "--------------------" << std::endl;
// 测试mySwap
int x = 100, y = 200;
std::cout << "Before swap: x = " << x << ", y = " << y << std::endl;
mySwap(x, y); // 实例化为mySwap<int>
std::cout << "After swap: x = " << x << ", y = " << y << std::endl;
double p = 1.23, q = 4.56;
std::cout << "Before swap: p = " << p << ", q = " << q << std::endl;
mySwap(p, q); // 实例化为mySwap<double>
std::cout << "After swap: p = " << p << ", q = " << q << std::endl;
return 0;
}在这个例子中,myMax 和 mySwap 函数通过模板参数 T 或 U 实现了泛型。当你在 main 函数中用 int、double 或 std::string 调用它们时,编译器会根据传入的类型自动生成对应的具体函数。这个过程是编译期完成的,所以运行时没有任何性能损失,这正是C++模板的强大之处。有时候,你可能还会看到template <typename T, typename U> 这种形式,这意味着函数可以接受不同类型的参数,但通常需要额外逻辑来处理类型间的转换或比较。
为什么泛型工具函数是现代C++编程不可或缺的一部分?
我个人觉得,如果一个C++项目里没有模板,那简直是浪费了这门语言最强大的特性之一。泛型工具函数的重要性,不仅仅是口头上说说那么简单,它实实在在地解决了现代软件开发中的许多痛点。
首先,代码复用性是它最大的亮点。想想看,如果我们要写一个排序函数,针对int、double、std::string甚至自定义的Person对象,难道要为每种类型都写一个几乎一模一样的排序逻辑吗?那简直是噩梦。模板让我们“写一次,用N次”,极大地减少了重复代码,提高了开发效率。
其次,它提供了无与伦比的类型安全。与C语言中那种void*的通用指针相比,模板在编译时就确定了类型,任何类型不匹配或不支持的操作都会在编译阶段被发现,而不是等到运行时才爆出错误。这大大降低了程序的潜在风险,也让调试变得轻松很多。
再来就是性能。C++模板是一种“零开销抽象”(zero-cost abstraction)。这意味着,编译器在实例化模板时,会生成与手写特定类型代码几乎相同的机器码,运行时没有额外的开销。这与多态(虚函数)那种通过虚表查找带来的运行时开销是不同的。对于性能敏感的应用,这一点尤其重要。
还有,它增强了代码的灵活性和可维护性。当你的代码需要支持新的数据类型时,通常只需要确保新类型满足模板函数所要求的“概念”(比如支持operator<或拷贝构造),而不需要修改模板函数本身的实现。这意味着,一旦核心逻辑被验证正确,它就能可靠地应用于各种场景,维护起来也方便得多。
简而言之,泛型工具函数让C++代码更简洁、更安全、更高效,也更易于扩展和维护。这在处理复杂系统时,简直是救命稻草。
在设计泛型工具函数时,有哪些常见的陷阱和最佳实践?
设计泛型工具函数并非一帆风顺,它像一把双刃剑,用得好能事半功倍,用不好则可能陷入泥潭。
常见的陷阱:
- 编译错误信息复杂且晦涩: 这是模板最让人头疼的地方之一。当模板实例化失败时,编译器可能会输出一大堆SFINAE(Substitution Failure Is Not An Error)相关的错误信息,堆栈深得让人怀疑人生,新手往往无从下手。比如,你期望一个类型支持某个操作,但它没有,错误信息可能不会直接告诉你“
T没有operator<”,而是报一堆模板元编程的内部错误。 - 代码膨胀(Code Bloat): 每实例化一个模板,编译器就会生成一份新的代码。如果你的泛型函数被多种类型实例化,而且函数体很大,那么最终的可执行文件可能会变得非常庞大,这会增加程序加载时间,也可能影响缓存效率。
- 概念要求不明确: 你设计的泛型函数对类型
T到底有什么要求?是需要支持operator==吗?还是需要有默认构造函数?如果这些要求不明确,用户在使用你的模板时可能会遇到意想不到的编译错误。 - 模板参数推导失败或歧义: 有时候,编译器无法准确推导出模板参数,或者存在多种可能的推导路径导致歧义,这都会引发编译错误。
- 依赖名称问题: 在模板内部引用依赖于模板参数的类型或成员时,常常需要使用
typename或template关键字来帮助编译器解析,否则会报错。这对于初学者来说,是一个非常反直觉的语法点。
最佳实践:
- 明确类型概念和约束: 这是最重要的。在C++20之后,我们有了
Concepts,可以显式地声明模板参数需要满足哪些条件(例如,template <Printable T>)。这不仅让代码意图更清晰,还能在编译错误时提供更友好的信息。即使没有C++20,也要在文档中清晰说明类型要求。 - 最小化模板代码: 尽量将不依赖于模板参数的通用逻辑提取到非模板函数中。这样可以减少模板实例化产生的代码量,避免代码膨胀。模板函数只负责处理那些真正需要泛型化的部分。
- 使用
const T&作为参数: 除非你需要修改参数或需要拷贝,否则尽量使用const T&来传递参数。这可以避免不必要的拷贝构造,提高效率,并保证原始数据不被意外修改。 - 完美转发(Perfect Forwarding): 当泛型函数需要将参数转发给另一个函数时,使用
template <typename... Args> void foo(Args&&... args)和std::forward<Args>(args)...可以保持参数的值类别(左值或右值),避免不必要的拷贝或移动。 - 提供特化版本或重载: 对于某些特定类型,泛型实现可能不是最优的,或者根本不适用。这时可以提供模板特化(Template Specialization)或非模板重载来为这些特定类型提供更高效或正确的实现。
- 单元测试: 针对泛型工具函数,务必用多种类型进行充分的单元测试,包括内置类型、标准库类型和自定义类型,以确保其在各种场景下的正确性。
- 清晰的文档: 详细说明函数的功能、模板参数的预期、可能抛出的异常以及任何特定要求。这对于使用者来说至关重要。
如何处理泛型工具函数中的类型约束和编译期检查?
在泛型工具函数中,我们经常需要确保模板参数满足某些特定的条件,否则就应该拒绝编译。这不仅仅是为了防止运行时错误,更是为了提供更好的编译期诊断和更清晰的代码意图。
在C++20之前,处理类型约束和编译期检查主要依赖于SFINAE (Substitution Failure Is Not An Error) 机制和std::enable_if。SFINAE 的核心思想是,当编译器尝试实例化一个模板但发现某个模板参数的替换导致非法类型或表达式时,它不会立即报错,而是将这个模板从候选集中移除,并尝试其他重载或特化。std::enable_if就是利用这一特性来条件性地启用或禁用模板。
举个例子,我们想写一个函数,只允许整数类型进行某种操作:
#include <type_traits> // 包含类型特性库
// C++11/14/17 风格的 SFINAE 约束
template <typename T>
typename std::enable_if<std::is_integral<T>::value, void>::type // 只有当T是整数类型时,这个函数才有效
processIntegral(T value) {
std::cout << "Processing integral value: " << value << std::endl;
}
// 另一个SFINAE示例,限制只有可比较的类型
template <typename T>
typename std::enable_if<std::is_arithmetic<T>::value && std::is_scalar<T>::value, T>::type
getAbsolute(T value) {
return (value < 0) ? -value : value;
}
// C++14/17 可以使用 `_t` 后缀简化 `typename std::enable_if<...>::type`
template <typename T>
std::enable_if_t<std::is_floating_point<T>::value, void>
processFloatingPoint(T value) {
std::cout << "Processing floating point value: " << value << std::endl;
}老实说,在C++20 Concepts出来之前,SFINAE简直是模板元编程的噩梦,虽然强大,但调试起来真是让人头疼,错误信息往往让人摸不着头脑。
进入C++20,我们有了Concepts,它为类型约束提供了一种更优雅、更直观、错误信息更友好的方式。Concepts允许你定义一组类型必须满足的语义和句法要求。
#include <concepts> // 包含C++20 Concepts库
#include <iostream>
#include <string>
// 定义一个概念:要求类型是可打印的(这里简化为支持<<操作符)
template <typename T>
concept Printable = requires(T a) {
{ std::cout << a } -> std::ostream&; // 要求表达式 std::cout << a 是合法的,并且返回 std::ostream&
};
// 使用Concepts约束泛型函数
template <Printable T> // 只有满足Printable概念的类型才能调用这个函数
void printValue(T value) {
std::cout << "Value: " << value << std::endl;
}
// 另一个概念:要求类型是算术类型
template <typename T>
concept Arithmetic = std::is_arithmetic_v<T>;
template <Arithmetic T> // 只有算术类型才能调用
T multiplyByTwo(T value) {
return value * 2;
}
int main() {
printValue(123);
printValue(3.14);
printValue(std::string("Hello Concepts!"));
// printValue(std::vector<int>{1,2,3}); // 这会编译失败,因为std::vector<int>不满足Printable概念,编译器会给出清晰的错误
std::cout << "Multiplied by two: " << multiplyByTwo(5) << std::endl;
std::cout << "Multiplied by two: " << multiplyByTwo(2.5) << std::endl;
// multiplyByTwo(std::string("abc")); // 这也会编译失败
// 另外,对于一些简单的编译期检查,我们还可以使用 static_assert
static_assert(sizeof(int) >= 4, "int must be at least 4 bytes on this platform!");
static_assert(std::is_same_v<decltype(1+1), int>, "1+1 should be an int!");
return 0;
}现在有了Concepts,感觉世界都清爽了许多。它让模板代码的可读性和可维护性大幅提升,错误信息也变得非常友好,直接告诉你哪个概念没有满足。这对于大型项目和团队协作来说,简直是福音。
除了SFINAE和Concepts,我们还可以使用static_assert进行更通用的编译期检查。static_assert可以在编译时检查一个条件,如果条件不满足,就会导致编译失败,并输出一条自定义的错误消息。这对于检查类型大小、特性或任何其他编译期可确定的属性都非常有用。
总的来说,选择哪种方式取决于你的C++标准版本和具体需求。C++20 Concepts无疑是未来的方向,它让泛型编程的门槛大大降低,也让代码更加健壮和易于理解。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
下一篇:今日头条关闭广告推荐方法
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Java文件操作之创建常规文件与临时文件
- 1. 创建常规文件createFile() 在Ja va NIO.2的世界里,当你需要创建一个全新的空文件时,Files.createFile(Path, FileAttribute...) 就是你的首选工具。这个方法设计得相当周到,直接上图,咱们边看边聊。 核心特点: 防覆盖机制:如果目标文件已经
- 1小时前 10:53 0
-
 正版软件
正版软件
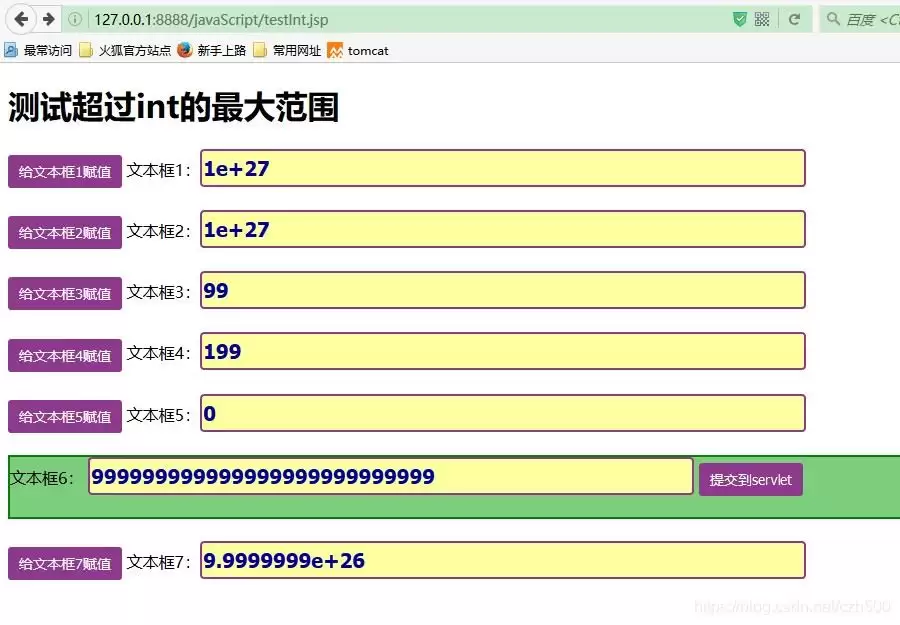
- java中超过int的最大范围问题
- Ja va中超过int的最大范围 直接来看图片和代码。 问题场景 在Ja va后端开发中,处理前端传来的数据是家常便饭。但你是否考虑过这样一个场景:当浏览器客户端传递过来的参数,其数值大小超过了Ja va中int类型的最大范围,我们该如何妥善处理? 现实情况是,我们很难完全预知或限制用户在文本框中输
- 2小时前 09:50 0
-
 正版软件
正版软件
- Java多语言切换实现方法(不用重启,不换代码,10秒搞定!)
- 5个关键点,让Ja va多语言切换“秒切” 1. 传统多语言切换:重启的“马拉松”,用户的“噩梦” 先来看看我们过去是怎么做的。传统做法非常直接:每次需要切换语言,整个应用服务都必须重启一次。结果呢?想象一下这个场景:用户正在下单,页面突然变成“Hello World”,紧接着系统重启,订单丢失,用
- 2小时前 09:50 0
-
 正版软件
正版软件
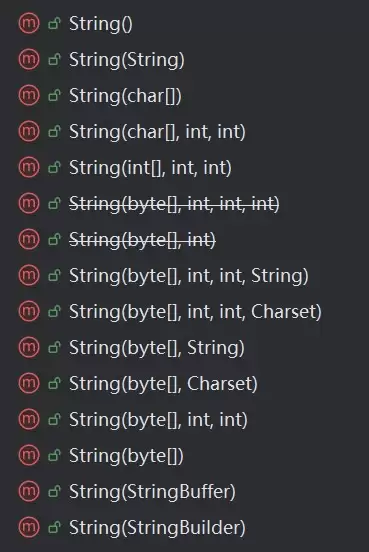
- JAVA中String类的使用方法示例讲解
- 1、前言 在Ja va编程的世界里,String类是我们打交道最频繁的伙伴之一,几乎每个项目都离不开它。今天,我们就来系统地梳理一下这个核心类的使用门道。 整个脉络可以清晰地分为三步:先从如何创建String对象讲起,然后深入探讨字符串之间如何正确比较,最后再盘点一批最实用的常用方法。跟着这个思路走
- 2小时前 09:50 0
-
 正版软件
正版软件
- Nginx如何限制ThinkPHP的并发连接数_Nginx限流保护ThinkPHP服务【教程】
- ThinkPHP应用Nginx并发限制需四层协同:一、IP级限流;二、路由级细粒度限流;三、全局+单IP双层防护;四、worker/FPM/ulimit底层容量匹配 部署ThinkPHP应用时,你是否遇到过服务响应迟缓、频繁出现504 Gateway Timeout,甚至服务器资源被瞬间耗尽的情况?
- 3小时前 08:47 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 239天前
-
4
- 探析Spring Boot框架的优点和特色
- 555天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 493天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 469天前
-
 7
7
-
 8
8
- Python实战教程:批量转换多种音乐格式
- 1101天前
-
9
- 如何在在线答题中实现试卷的自动批改和自动评分
- 929天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00