让AI模型成为GTA五星玩家,基于视觉的可编程智能体Octopus来了
 发布于2023-11-11 阅读(0)
发布于2023-11-11 阅读(0)
扫一扫,手机访问
电子游戏已经成为现实世界的模拟舞台,展现出无限的可能性。以《侠盗猎车手》(GTA)为例,在游戏中,玩家可以以第一人称视角,在虚拟城市洛圣都中体验丰富多彩的生活。然而,既然人类玩家能够在洛圣都中尽情畅游并完成任务,我们是否也能有一个AI视觉模型来控制GTA中的角色,成为执行任务的“玩家”呢?GTA中的AI玩家是否能够扮演一个遵守交通规则的五星好市民,帮助警方抓捕罪犯,甚至做一个乐于助人的路人,帮助流浪汉找到适合的住所呢?
当前的视觉-语言模型(VLMs)在多模态感知和推理方面已经取得了实质性的进步,但它们通常基于较为简单的视觉问答(VQA)或者视觉标注(Caption)任务。然而,这些任务设定明显无法使VLM真正完成现实世界中的任务。因为实际任务不仅需要对视觉信息的理解,更需要模型具备规划推理和根据实时更新的环境信息做出反馈的能力。同时,生成的规划还需要能够操纵环境中的实体来真实地完成任务
尽管目前已有的语言模型(LLMs)能够根据提供的信息进行任务规划,但其无法理解视觉输入,这大大限制了语言模型在执行具体现实任务时的应用范围,特别是针对一些具身体智能的任务,基于文本输入往往过于复杂或难以详尽,这使得语言模型无法高效地从中提取信息以完成任务。目前,语言模型在程序生成方面已经进行了若干探索,但根据视觉输入生成结构化、可执行、稳健的代码的探索仍未深入
为了解决如何使大模型具身智能化的问题,创建能够准确制定计划并执行命令的自主和情境感知系统,来自新加坡南洋理工大学,清华大学等的学者提出了 Octopus。Octopus 是一种基于视觉的可编程智能体,它的目的是通过视觉输入学习,理解真实世界,并以生成可执行代码的方式完成各种实际任务。通过在大量视觉输入和可执行代码的数据对的训练,Octopus学会了如何操控电子游戏的角色完成游戏任务,或者完成复杂的家务活动。

论文链接:https://arxiv.org/abs/2310.08588
项目网页:https://choiszt.github.io/Octopus/
开源代码链接:https://github.com/dongyh20/Octopus
需要重写的内容是:数据采集与训练 重写后的内容:数据收集和训练
为了训练能够完成具身智能化任务的视觉 - 语言模型,研究者们还开发了 OctoVerse,其包含两个仿真系统用于为 Octopus 的训练提供训练数据以及测试环境。这两个仿真环境为 VLM 的具身智能化提供了可用 的训练以及测试场景,对模型的推理和任务规划能力都提出了更高的要求。具体如下:
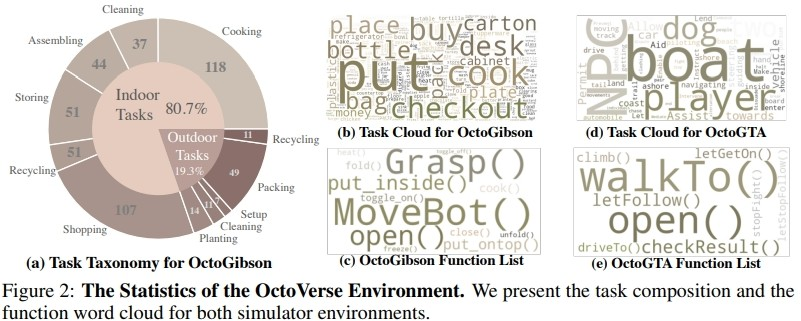
1.OctoGibson:基于斯坦福大学开发的 OmniGibson 进行开发,一共包括了 476 个符合现实生活的家 务活动。整个仿真环境中包括 16 种不同类别的家庭场景,涵盖 155 个实际的家庭环境实例。模型可 以操作其中存在的大量可交互物体来完成最终的任务。
2.OctoGTA:基于《侠盗猎车手》(GTA)游戏进行开发,一共构建了 20 个任务并将其泛化到五个不 同的场景当中。通过预先设定好的程序将玩家设定在固定的位置,提供完成任务必须的物品和 NPC,以保证任务能够顺利进行。
下图展示了 OctoGibson 的任务分类以及 OctoGibson 和 OctoGTA 的一些统计结果。
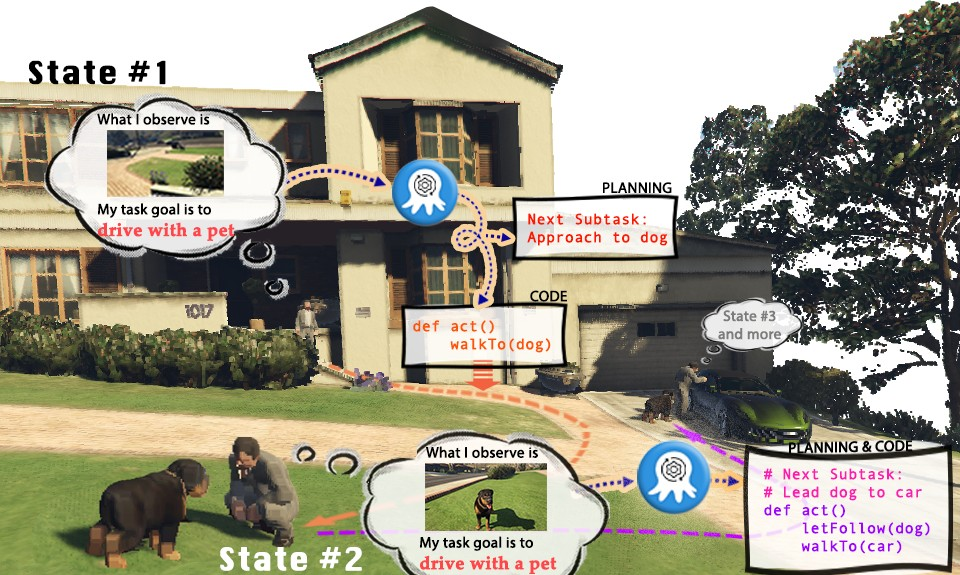
为了在两个构建的仿真环境中高效收集训练数据,研究人员建立了一个完整的数据收集系统。通过引入GPT-4作为任务执行者,研究人员利用预先实现的函数将从仿真环境中获取的视觉输入转化为文本信息,并提供给GPT-4。在GPT-4返回当前一步的任务规划和可执行代码后,再在仿真环境中执行代码,并判断当前一步的任务是否完成。如果成功,继续收集下一步的视觉输入;如果失败,则返回到上一步的起始位置,重新收集数据
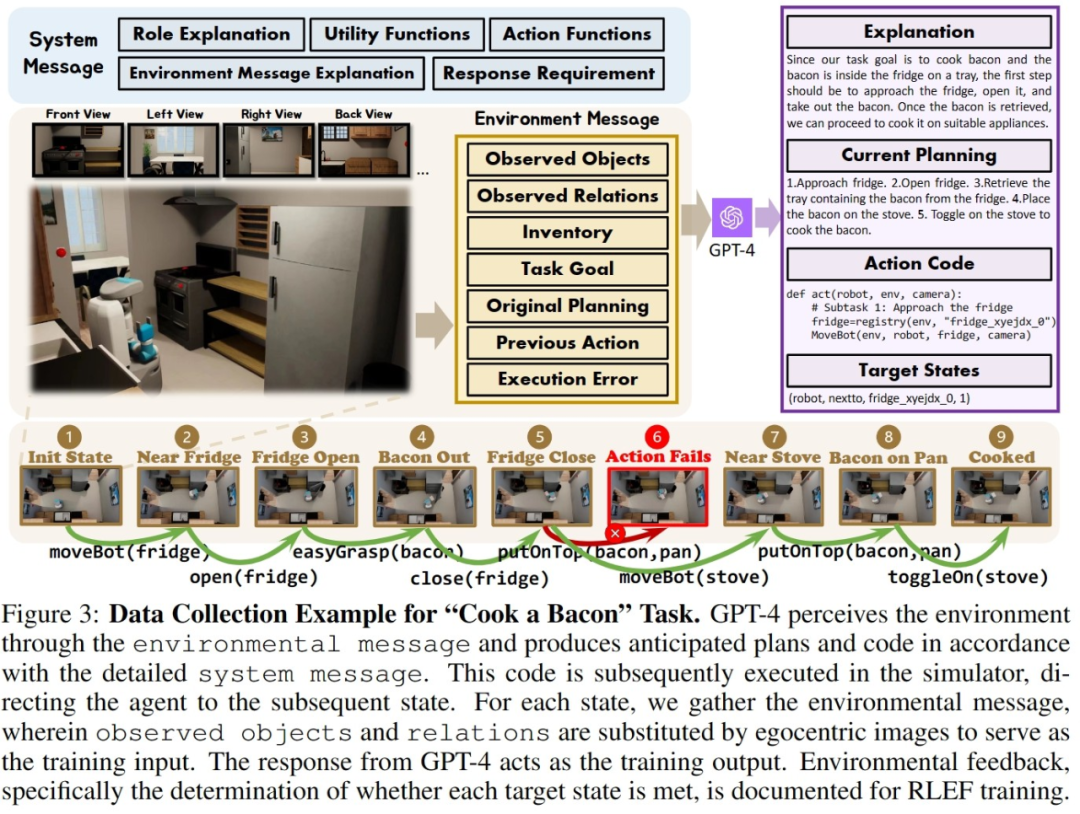
上图以 OctoGibson 环境当中的 Cook a Bacon 任务为例,展示了收集数据的完整流程。需要指出的是,在收集数据的过程中,研究者不仅记录了任务执行过程中的视觉信息,GPT-4 返回的可执行代码等,还记录了每一个子任务的成功情况,这些将作为后续引入强化学习来构建更高效的 VLM 的基础。GPT-4 的功能虽然强大,但并非无懈可击。错误可以以多种方式显现,包括语法错误和模拟器中的物理挑战。例如,如图 3 所示,在状态 #5 和 #6 之间,由于 agent 拿着的培根与平底锅之间的距离过远,导致 “把培根放到平底锅” 的行动失败。此类挫折会将任务重置到之前的状态。如果一个任务在 10 步之后仍未完成,则被认定为不成功,我们会因预算问题而终止这个任务,而这个任务的所有子任务的数据对都会认为执行失败。
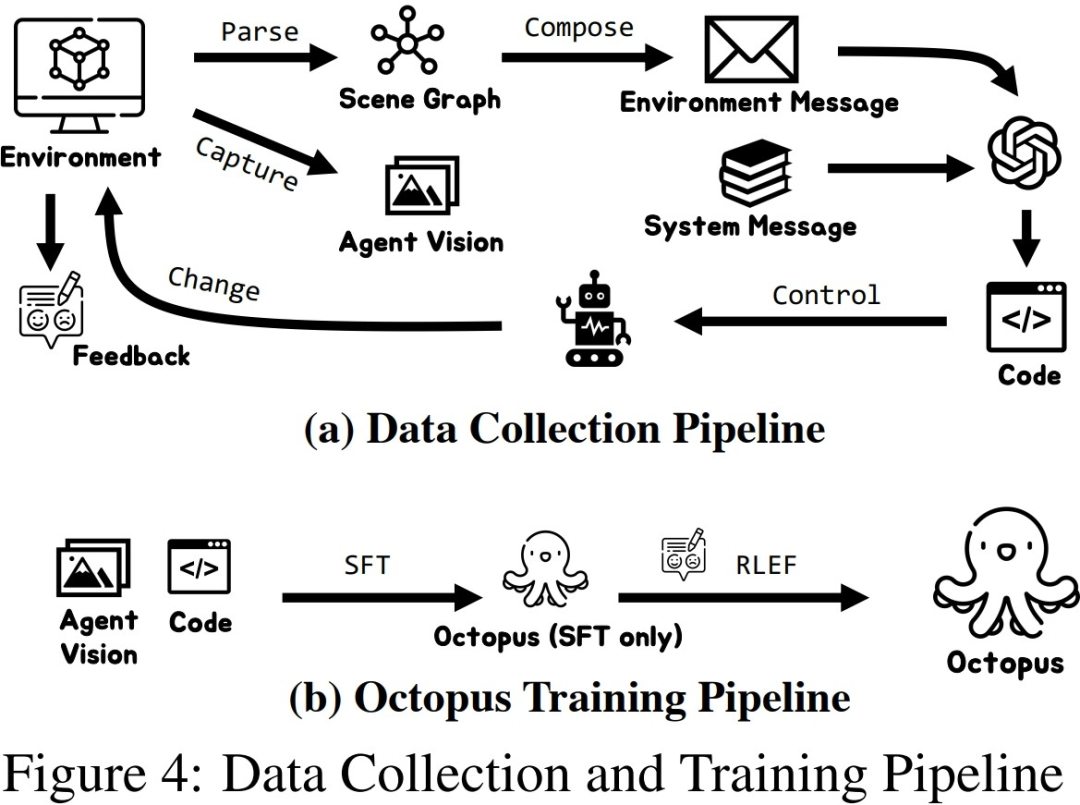
研究者在收集了一定规模的训练数据后,利用这些数据训练出了一个具备智能化的视觉-语言模型Octopus。下图展示了完整的数据采集和训练过程。在第一阶段,通过使用采集的数据进行监督式微调,研究者构建出了一个能够接收视觉信息作为输入,并按照固定格式进行输出的VLM模型。在这个阶段,模型能够将视觉输入信息映射为任务计划和可执行代码。在第二阶段,研究者引入了RLEF
利用环境反馈的强化学习,通过先前采集的子任务的成功情况作为奖励信号,进一步提升 VLM 的任务规划能力,以提高整体任务的成功率
实验结果
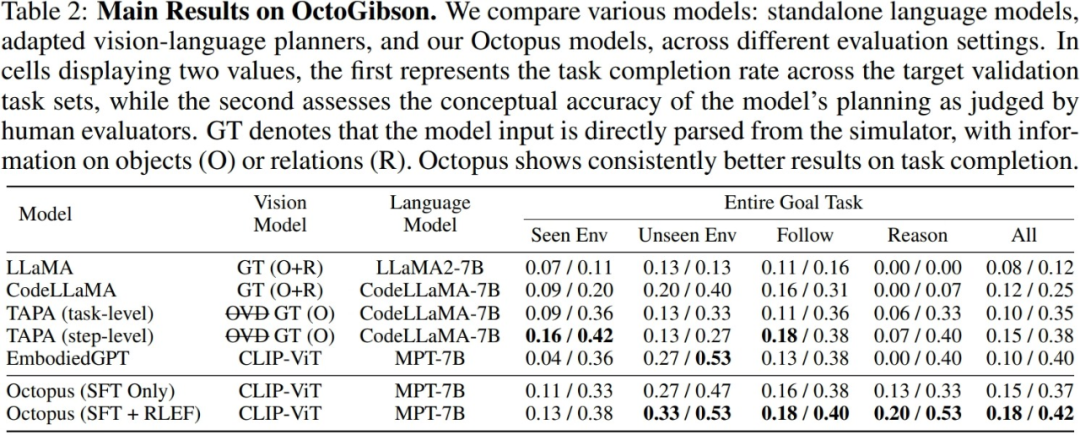
研究者在构建的 OctoGibson 环境中,对于当前主流的 VLM 和 LLM 进行了测试,下表展示了主要实验结 果。对于不同的测试模型,Vision Model 列举了不同模型所使用的视觉模型,对于 LLM 来说,研究者将视觉信息处理为文本作为 LLM 的输入。其中 O 代表提供了场景中可交互物体的信息,R 代表提供了场景中 物体相对关系的信息,GT 代表使用真实准确的信息,而不引入额外的视觉模型来进行检测。
对于所有的测试任务,研究者报告了完整的测试集成功率,并进一步将其分为四个类别,分别记录在训 练集中存在的场景中完成新任务,在训练集中不存在的场景中完成新任务的泛化能力,以及对于简单的 跟随任务以及复杂的推理任务的泛化能力。对于每一种类别的统计,研究者报告了两种评价指标,其中 第一个为任务的完成率,以衡量模型完成具身智能任务的成功率;第二个为任务规划准确率,用于体现 模型进行任务规划的能力。
此外,研究人员还展示了对于 OctoGibson 仿真环境中采集的视觉数据,不同模型的响应实例。下图展示了使用 TAPA+CodeLLaMA、Octopus以及GPT-4V三种模型在OctoGibson中生成视觉输入后的回应。可以看出,相较于只进行了监督式微调的Octopus模型和TAPA+CodeLLaMA,经过RLEF训练的Octopus模型的任务规划更加合理。即使对于较为模糊的任务指令“寻找一个大瓶”,也能提供更加完善的计划。这些表现进一步说明了RLEF训练策略对于提升模型的任务规划能力和推理能力的有效性

总体来说,现有的模型在仿真环境中表现出的实际任务完成度和任务规划能力依旧有很大的提升空间。研究者们总结了一些较为关键的发现:
1.CodeLLaMA 能够提升模型的代码生成能力,但不能提升任务规划能力。
研究者指出,实验结果表明,CodeLLaMA能够显著提高模型的代码生成能力。相比传统的LLM,使用CodeLLaMA能够获得更好、更高可执行性的代码。然而,尽管一些模型使用CodeLLaMA生成代码,但整体任务的成功率仍然受到任务规划能力的限制。任务规划能力较弱的模型,尽管生成的代码可执行性较高,但最终任务成功率仍然较低。反观Octopus,尽管没有使用CodeLLaMA,代码可执行性略有下降,但由于其强大的任务规划能力,整体任务成功率仍然优于其他模型
当面对大量的文本信息输入时,LLM 的处理变得相对困难
在实际的测试过程中,研究者通过对比 TAPA 和 CodeLLaMA 的实验结果得出了一个结论,即语言模型很难较好地处理长文本输入。研究者们遵从 TAPA 的方法,使用真实的物体信息来进行任务规划,而 CodeLLaMA 使用物体和物体之间的相对位置关系,以期提供较为完整的信息。但在实验过程中,研究者 发现由于环境当中存在大量的冗余信息,因此当环境较为复杂时,文本输入显著增加,LLM 难以从大量 的冗余信息当中提取有价值的线索,从而降低了任务的成功率。这也体现了 LLM 的局限性,即如果使用 文本信息来表示复杂的场景,将会产生大量冗余且无价值的输入信息。
3.Octopus 表现出了较好的任务泛化能力。
Octopus具有很強的任務泛化能力,通過實驗結果可以得知。在未出現在訓練集中的新場景中,Octopus完成任務的成功率和任務規劃的成功率均優於現有模型。這也展現了視覺-語言模型在同一類別的任務中具有內在優勢,其泛化性能優於傳統的LLM
4.RLEF 能够增强模型的任务规划能力。
研究人员在实验结果中提供了两个模型的性能比较:一个是经过第一阶段监督式微调的模型,另一个是经过RLEF训练的模型。从结果中可以看出,经过RLEF训练后,模型在需要强大的推理和任务规划能力的任务上,整体成功率和规划能力都有显著提高。相比已有的VLM训练策略,RLEF更加高效。示例图表明,经过RLEF训练的模型在任务规划方面有所提高。在面对复杂任务时,模型能够学会在环境中探索;此外,模型在任务规划方面更加符合仿真环境的实际要求(例如,模型需要先移动到要交互的物体,才能开始交互),从而降低任务规划失败的风险
讨论
需要重写的内容是:融化试验
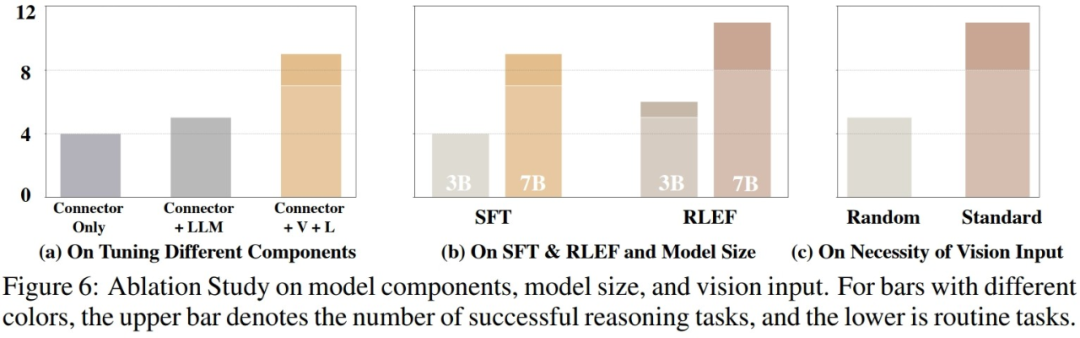
在对模型实际能力进行评估后,研究人员进一步探究了影响模型性能的可能因素。如下图所示,研究人员从三个方面进行了实验
需要重写的内容是:1. 訓練參數的比重
研究者进行了对比实验,比较了仅训练视觉模型和语言模型的连接层、训练连接层和语言模型,以及完整训练模型的性能。结果显示,随着训练参数的增加,模型的性能逐渐提升。这表明,训练参数的数量对于模型在一些固定场景中能否完成任务至关重要
2. 模型的大小
研究人员对比了较小的3B参数模型和基线7B模型在两个训练阶段的性能差异。比较结果表明,当模型整体参数量较大时,模型的性能也会明显提升。未来在VLM领域的研究中,如何选择适当的模型训练参数,以确保模型具备完成对应任务的能力,同时也保证模型的轻量化和快速推理速度,将是一个非常关键的问题
需要重写的内容是:3. 视觉输入的连续性。 重写后的内容:3. 视觉输入的连贯性
为了研究不同的视觉输入对实际VLM性能的影响,研究人员进行了实验。在测试过程中,模型在仿真环境中按顺序转动,并采集第一视角图像和两张鸟瞰图,然后按顺序将这些视觉图像输入VLM。在实验中,当研究人员随机打乱视觉图像的顺序再输入VLM时,VLM的性能受到较大的损失。这一方面说明了完整且结构化的视觉信息对VLM的重要性,另一方面也反映了VLM在响应视觉输入时需要依赖视觉图像之间的内在联系,一旦这种联系被破坏,将极大地影响VLM的表现
GPT-4
此外,研究者还对 GPT-4 以及 GPT-4V 在仿真环境当中的性能进行了测试和统计。
需要进行改写的是:1. GPT-4
针对 GPT-4,在测试过程中研究者提供与使用其采集训练数据时完全相同的文本信息作为输入。在测试任务上,GPT-4 能够完成一半的任务,这一方面说明现有的 VLM 相对于 GPT-4 这样的语言模型,从性能上还 有很大的提升空间;另一方面也说明,即使是 GPT-4 这样性能较强的语言模型,在面对具身智能任务时, 其任务规划能力和任务执行能力依然需要更进一步的提升。
需要重新书写的内容是:2. GPT-4V
由于 GPT-4V 刚刚发布可以直接调用的 API,研究者还没来得及尝试,但是研究者们之前也手动测试了一些实例来展现 GPT-4V 的性能。通过一些示例,研究者认为 GPT-4V 对于仿真环境当中的任务具有较强的零样本泛化能力,也能够根据视觉输入生成对应的可执行的代码,但其在一些任务规划上稍逊色于在仿真环境采集的数据上微调之后的模型。
总结
研究人员指出了当前工作的一些限制:
当前的Octopus模型在处理复杂任务时表现不佳。面对复杂任务时,Octopus经常会做出错误的规划,并且严重依赖环境的反馈信息,导致难以完成整个任务
2.Octopus 模型仅在仿真环境当中进行训练,而如何将其迁移到真实世界当中将会面临一系列的问题。例如,真实环境当中模型将难以得到较为准确的物体相对位置信息,如何构建起物体对于场景 的理解将变得更加困难。
3. 目前,章鱼的视觉输入是离散的静态图片,将其能够处理连续的视频成为未来的挑战。连续的视频可以进一步提高模型完成任务的性能,但如何高效地处理和理解连续视觉输入将成为提升 VLM 性能的关键
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 智能家居的私人生活彻底改变:人工智能的影响
- 自动化、控制和易用性是智能家居众所周知的功能,但是各位有没有想过这些技术能走多远?智能家居的功能是否存在任何限制?如果存在,那么限制在哪里?人工智能的表面几乎没有被触及,人工智能是最新的事物,正在彻底改变日常生活。通过将人工智能融入智能家居技术,我们可以实现很多目标。一旦学会利用现代科技带来的所有好处,将改善日常生活并享受居住的便利和舒适。人工智能驱动的家庭自动化随着时间的推移,虚拟助手经过训练,可以识别声音并听取命令,从而执行任务,也可以轻松简化日常任务。一旦将人工智能助理与家庭设备集成,可以在座位上完
- 48分钟前 人工智能 AI 智能家居 0
-
 正版软件
正版软件
- 首款AI超轻薄本图赏:1.19kg、酷睿Ultra 7,灵耀14 2024已开售
- 2024年轻薄笔记本行业的发展趋势是轻量化和AI智能。随着今年AIGC的热潮,AIGC创作开始流行,所以AI智能也将成为一大发展趋势。在12月15日,华硕发布了灵耀142024新品,这是首款酷睿Ultra新品AIPC轻薄本。让我们结合开箱体验来聊一聊它的亮点首先是外观设计方面,华硕灵耀142024延续了灵耀系列一贯的设计语言,A面通过采用几何线条勾勒出了品牌LOGO,简洁、辨识度兼具。而且实际上手后能发现,质感还是相当在线的,毕竟是全金属机身,而且机身比较轻薄,要比当前主流的轻薄本更轻、更薄,实测后发现,
- 13小时前 04:05 0
-
 正版软件
正版软件
- DeepMind论文登上Nature:困扰数学家几十年的难题,大模型发现全新解
- 作为今年人工智能领域的顶尖技术,大型语言模型(LLM)擅长于将概念进行组合,并通过阅读、理解、写作和编码来帮助人们解决问题。但是,它们是否能够发现全新的知识呢?鉴于LLM已被证明存在"幻觉"问题,即生成与事实不符的信息,因此利用LLM进行可验证的正确发现是一项具有挑战性的任务现在,来自GoogleDeepMind的研究团队提出了一种为数学和计算机科学问题搜索解决方案的新方法——FunSearch。FunSearch的工作原理是将预训练的LLM(以计算机代码的形式提供创造性解决方案)与自动「评估器」配对,以
- 昨天 05-17 04:00 模型 数据 0
-
 正版软件
正版软件
- 联想王传东:AI PC将成为个人信息的安全保险箱
- 12月15日消息,联想集团副总裁、中国区首席市场官王传东近日在公开活动中分享了他对于AI的洞察。王传东表示,AI时代,数据是最宝贵的资源,AIPC以其设备级个人数据和隐私安全保护的核心特征,成为AI时代个人的“数字保险箱”。王传东在分享中表示,2024年将会是人工智能个人电脑的元年,它将对每个人的工作、学习和生活产生深远的影响。人工智能个人电脑不仅仅是一个生产力工具,它还将成为每个人的个人AI助手,为用户提供四大价值,包括:在通用场景下提供个性化服务、即时可靠的智能服务、更低的大型模型使用成本、以及可信安
- 前天 05-16 03:55 0
-
 正版软件
正版软件
- 真实、可控、可拓展,自动驾驶光照仿真平台LightSim上新了
- 最近,WaabiAI、多伦多大学、滑铁卢大学和麻省理工的研究者们在NeurIPS2023上提出了一个全新的自动驾驶光照仿真平台LightSim。研究者们提出了一种从真实数据中生成配对光照训练数据的方法,解决了数据缺失和模型迁移损失的问题。LightSim利用神经辐射场(NeRF)和基于物理的深度网络渲染车辆驾驶视频,首次在大规模真实数据上实现了动态场景的光照仿真项目网站:https://waabi.ai/lightsim论文链接:https://openreview.net/pdf?id=mcx8IGne
- 4天前 模型 训练 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1620天前
-
 2
2
- Overture设置踏板标记的方法
- 1457天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1447天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1645天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1611天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1607天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1622天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1643天前
-
 9
9
相关推荐
- 首款AI超轻薄本图赏:1.19kg、酷睿Ultra 7,灵耀14 2024已开售
- DeepMind论文登上Nature:困扰数学家几十年的难题,大模型发现全新解
- 联想王传东:AI PC将成为个人信息的安全保险箱
- 真实、可控、可拓展,自动驾驶光照仿真平台LightSim上新了
- 新的标题为:荣耀 90 GT 发布会日期确认:性能强悍的霸主即将亮相
- 荣耀90 GT规格首曝:搭载第二代骁龙8芯片 100W快充来势汹汹
- 联想小新Pro 14/16 2024系列的独特之处:IdeaPad Pro 5i
- 领克汽车全新09 EM-P车型即将预售,定位“超电SUV旗舰”
- 韩国:计划2030年向机器人产业投资3万亿韩元,机器人产业规模将超20万亿韩元【附机器人行业发展现状分析】
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00