不会写代码?DeepSeek轻松实现爬虫功能
 发布于2025-11-17 阅读(0)
发布于2025-11-17 阅读(0)
扫一扫,手机访问
我们以抓取博客内容为例,为大家展示如何操作。
#抓取标题与链接#
使用Python获取我的博客中所有文章的标题及其对应链接。(需翻页处理,各页面URL规律如下:第二页为https://blog.bbskali.cn/page/2/,第三页为 https://blog.bbskali.cn/page/3/,第四页为 https://blog.bbskali.cn/page/4/,依此类推。)博客主地址:https://blog.bbskali.cn 将最终结果导出为csv文件。文章标题的HTML结构示例如下:
<h2 class="m-t-xs text-ellipsis index-post-title text-title"><a href="https://blog.bbskali.cn/4234.html">Homeassistant界面美化</a></h2>
HAPPY TEACHER'S DAY
 可以看到,讲解非常详细。
可以看到,讲解非常详细。
运行生成的代码,效果如下:
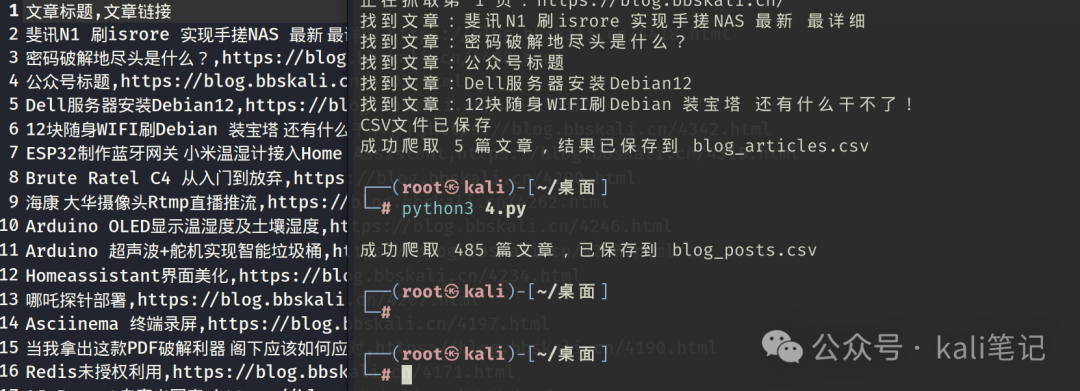 接下来,我们尝试更复杂一点的任务:提取每篇文章的阅读次数、评论数量以及发布时间。
接下来,我们尝试更复杂一点的任务:提取每篇文章的阅读次数、评论数量以及发布时间。
 新建对话内容如下:
新建对话内容如下:
#抓取文章阅读量、评论数、发布日期#
很好,之前的代码已经成功获取了博客的所有标题和链接。现在我需要你进入每一篇文章的具体页面,提取其阅读量、评论数和发布时间。相关HTML代码结构如下:
HAPPY TEACHER'S DAY

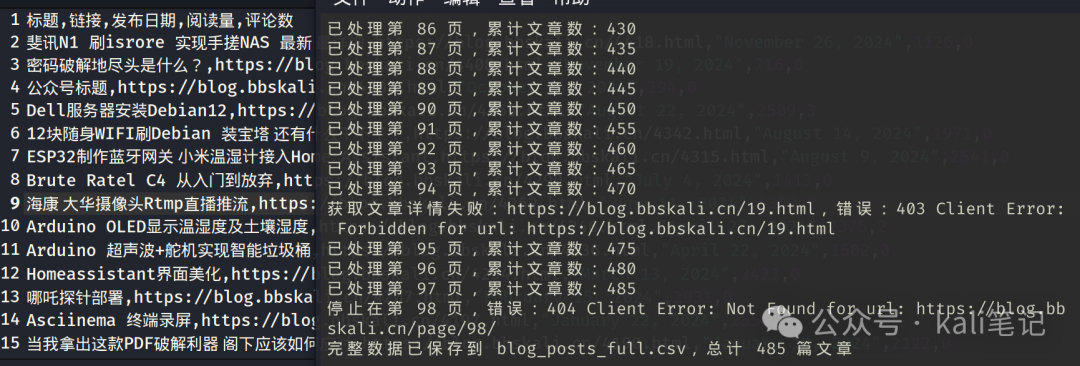 实际运行效果
实际运行效果
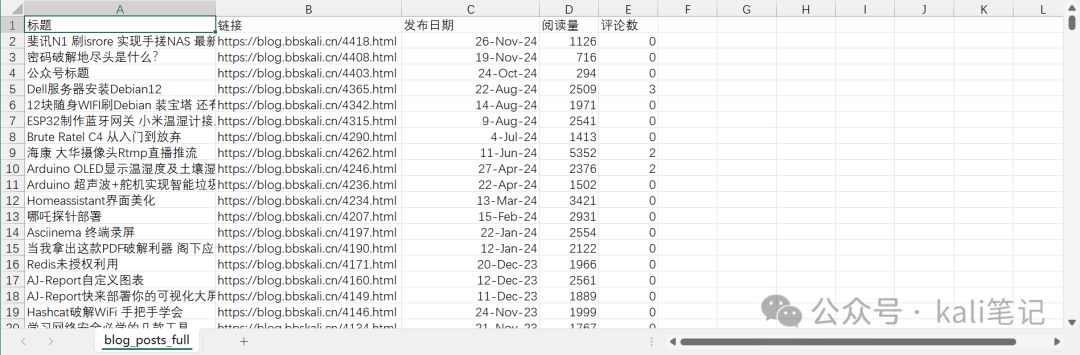 完整代码如下
完整代码如下
import requests from bs4 import BeautifulSoup import csv import re import timedef get_post_details(url, headers): try: response = requests.get(url, headers=headers) response.raise_for_status() except Exception as e: print(f"获取文章详情失败:{url},错误:{str(e)}") return None, None, None
soup = BeautifulSoup(response.text, 'html.parser')
提取发布时间
dateli = soup.find('li', class='meta-date') post_date = date_li.find('time').text.strip() if date_li else ''
提取阅读量
viewsli = soup.find('li', class='meta-views') views = 0 if views_li: views_text = viewsli.find('span', class='meta-value').text match = re.search(r'(\d+)', views_text.replace(' ', ' ')) views = match.group(1) if match else 0
提取评论数
commentsli = soup.find('li', class='meta-comments') comments = 0 if comments_li: comments_tag = commentsli.find('a', class='meta-value') or commentsli.find('span', class='meta-value') if comments_tag: match = re.search(r'(\d+)', comments_tag.text) comments = match.group(1) if match else 0
return post_date, views, comments
def get_all_posts(): base_url = "https://blog.bbskali.cn" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3' }
all_data = [] page_num = 1
while True:
构造分页链接
url = f"{base_url}/page/{page_num}/" if page_num > 1 else base_url try: response = requests.get(url, headers=headers) response.raise_for_status() except Exception as e: print(f"停止在第 {page_num} 页,错误:{str(e)}") break soup = BeautifulSoup(response.text, 'html.parser') posts = soup.find_all('div', class_='post_title_wrapper') if not posts: break for post in posts: h2_tag = post.find('h2', class_='index-post-title') if not h2_tag: continue a_tag = h2_tag.find('a') if a_tag and a_tag.has_attr('href'): title = a_tag.text.strip() link = a_tag['href'] # 获取文章详细信息 post_date, views, comments = get_post_details(link, headers) # 汇总数据 all_data.append([ title, link, post_date, views, comments ]) # 添加请求间隔,避免对服务器造成压力 time.sleep(0.5) print(f"已处理第 {page_num} 页,累计文章数:{len(all_data)}") page_num += 1写入CSV文件
with open('blog_posts_full.csv', 'w', newline='', encoding='utf-8-sig') as f: writer = csv.writer(f) writer.writerow(['标题', '链接', '发布日期', '阅读量', '评论数']) writer.writerows(all_data)
return len(all_data)
if name == "main": count = get_all_posts() print(f"完整数据已保存到 blog_posts_full.csv,总计 {count} 篇文章")
示例输出
""" 已处理第 1 页,累计文章数:10 已处理第 2 页,累计文章数:20 ... 完整数据已保存到 blog_posts_full.csv,总计 56 篇文章 """
总结:
借助DeepSeek,我们可以轻松生成所需的爬虫代码。当然,前提是我们必须清晰准确地描述需求!
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:PHP实现文件下载教程
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Win8图片打开提示注册类错误解决方法
- 首先重置照片应用并修改默认打开方式,若无效则运行sfc/scannow修复系统文件,最后通过创建新用户账户判断是否为配置文件损坏所致。
- 8小时前 22:03 0
-
 正版软件
正版软件
- 学习通app官网正版下载安装
- 可通过官网PWA、认证应用商店或微信扫码三种方式安全使用超星学习通:一、浏览器访问app.chaoxing.com并添加到主屏幕;二、在华为等官方商店搜索确认开发者为“北京世纪超星信息技术发展有限责任公司”后安装;三、微信扫码直启H5页面。
- 8小时前 21:53 0
-
 正版软件
正版软件
- LinuxUbuntu键盘语言设置教程
- 配置Ubuntu多语言输入需先通过系统设置添加键盘布局,再用快捷键或命令行切换;可通过修改配置文件实现开机默认布局,并安装Fcitx框架及中文引擎如搜狗拼音完成中文输入支持。
- 8小时前 21:38 键盘设置 0
-
 正版软件
正版软件
- 同城旅行app怎么找附近景点
- 1、打开同程旅行App,点击【去旅行】进入后选择【逛景点】,系统自动推荐附近景点;2、在首页搜索框输入“附近景点”,按距离、评分筛选结果;3、确保定位权限开启,刷新页面获取精准推荐。
- 8小时前 21:31 同城旅行app 0
-
 正版软件
正版软件
- 植物大战僵尸入口在哪 中文免费版在线玩
- 4399小游戏《植物大战僵尸》中文免费版在线入口为https://www.4399.com/flash/2751_1.htm,无需注册即可点击“开始游戏”启动H5版本,支持多浏览器及手机触控,含阳光机制、植物战术、关卡演进、本地与云端存档、操作优化等功能。
- 9小时前 21:22 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 241天前
-
 2
2
- 高德地图是哪个国家开发的?
- 297天前
-
 3
3
- 51漫画高清入口及最新章节更新
- 90天前
-
 4
4
- 拷贝漫画最新官网入口2025
- 130天前
-
 5
5
- 如何找到192.168.0.1登录入口
- 350天前
-
 6
6
- yy漫画下拉式免费阅读官网入口
- 220天前
-
 7
7
- 动漫共和国官网入口在线看
- 222天前
-
 8
8
- 2020美团外卖账单报告入口详解
- 239天前
-
 9
9
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 258天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00