一文总结特征增强&个性化在CTR预估中的经典方法和效果对比
 发布于2024-03-19 阅读(0)
发布于2024-03-19 阅读(0)
扫一扫,手机访问
在CTR预估中,主流都采用特征embedding+MLP的方式,其中特征非常关键。然而对于相同的特征,在不同的样本中,表征是相同的,这种方式输入到下游模型,会限制模型的表达能力。
为了解决这个问题,CTR预估领域提出了一系列相关工作,被称为特征增强模块。特征增强模块根据不同的样本,对embedding层的输出结果进行一次矫正,以适应不同样本的特征表示,提升模型的表达能力。
最近,复旦大学和微软亚洲研究院合作发布了一篇关于特征增强工作的综述,对比了不同特征增强模块的实现方法及其效果。现在,我们来介绍一下几种特征增强模块的实现方法,以及本文所进行的相关对比实验
 论文标题:A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
论文标题:A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
下载地址:https://arxiv.org/pdf/2311.04625v1.pdf
1、特征增强建模思路
特征增强模块,旨在提升CTR预估模型中Embedding层的表达能力,实现相同特征在不同样本下的表征差异化。特征增强模块可以用下面这个统一公式表达,输入原始的Embedding,经过一个函数后,生成这个样本个性化的Embedding。
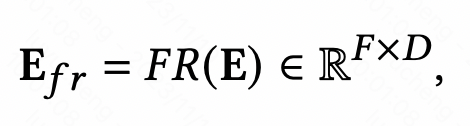 图片
图片
这类方法的大致思路为,在得到初始的每个特征的embedding后,使用样本本身的表征,对特征embedding做一个变换,得到当前样本的个性化embedding。下面给大家介绍一些经典的特征增强模块建模方法。
2、特征增强经典方法
An Input-aware Factorization Machine for Sparse Prediction(IJCAI 2019)这篇文章在embedding层之后增加了一个reweight层,将样本初始embedding输入到一个MLP中得到一个表征样本的向量,使用softmax进行归一化。Softmax后的每个元素对应一个特征,代表这个特征的重要程度,使用这个softmax结果和每个对应特征的初始embedding相乘,实现样本粒度的特征embedding加权。
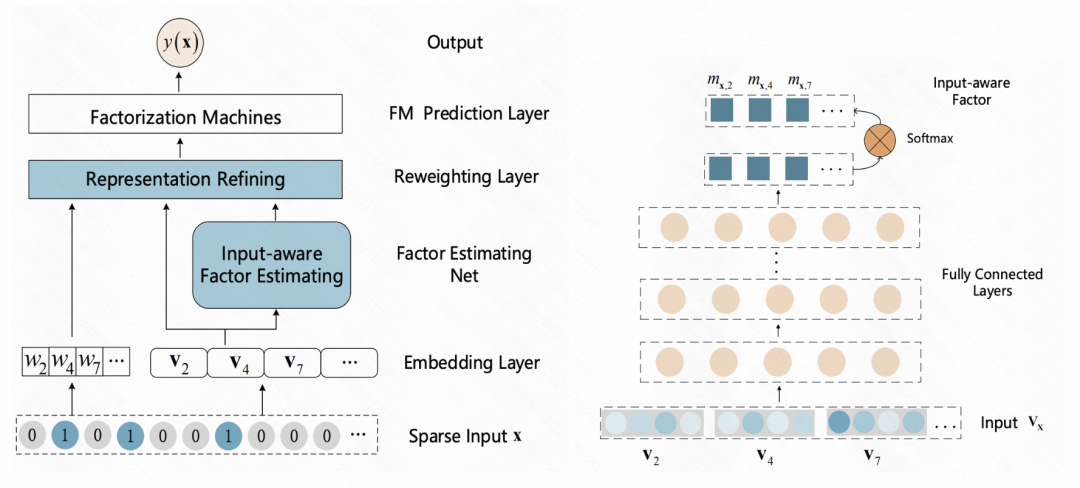 图片
图片
FiBiNET: 结合特征重要性和二阶特征交互的点击率预测模型(RecSys 2019)也采用了类似的思路。该模型为每个样本学习了一个特征的个性化权重。整个过程分为挤压(squeeze)、提取(extraction)和重新加权(reweight)三个步骤。在挤压阶段,通过池化方法将每个特征的嵌入向量得到一个统计标量。在提取阶段,将这些标量输入到多层感知机(MLP)中,得到每个特征的权重。最后,将这些权重与每个特征的嵌入向量相乘,得到加权后的嵌入结果,相当于在样本级别上进行特征重要性的筛选
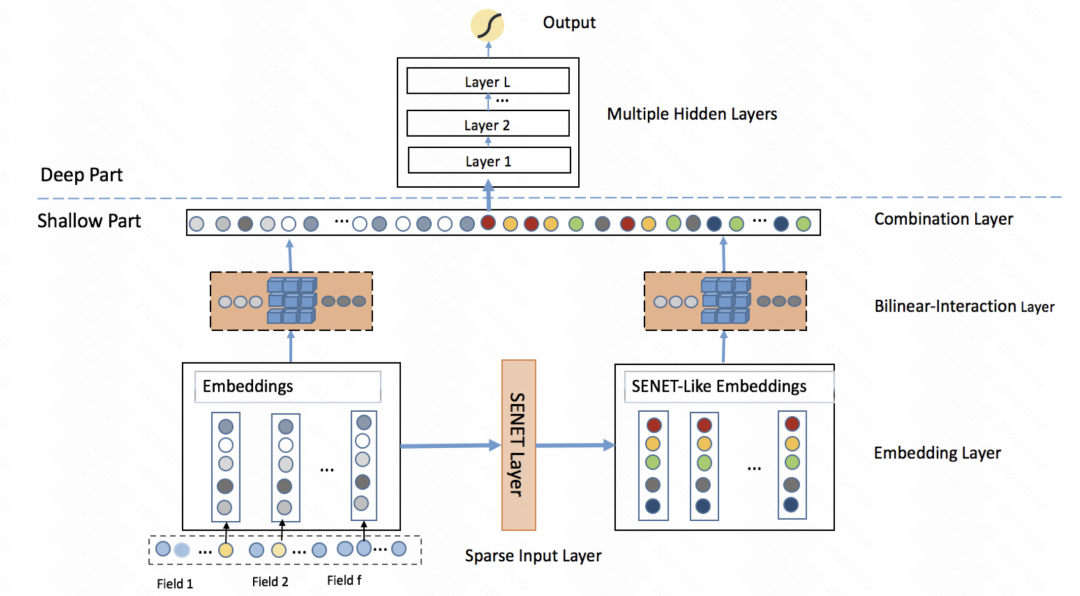 图片
图片
A Dual Input-aware Factorization Machine for CTR Prediction(IJCAI 2020)和上一篇文章类似,也是利用self-attention对特征进行一层增强。整体分为vector-wise和bit-wise两个模块。Vector-wise将每个特征的embedding当成序列中的一个元素,输入到Transformer中得到融合后的特征表示;bit-wise部分使用多层MLP对原始特征进行映射。两部分的输入结果相加后,得到每个特征元素的权重,乘到对应的原始特征的每一位上,得到增强后的特征。
 图片
图片
GateNet:增强门控深度网络用于点击率预测(2020)利用每个特征的初始嵌入向量通过一个MLP和sigmoid函数生成其独立的特征权重分数,同时使用MLP将所有特征映射为按位的权重分数,将两者结合起来对输入特征进行加权。除了特征层外,在MLP的隐藏层中,也利用类似的方法对每个隐藏层的输入进行加权
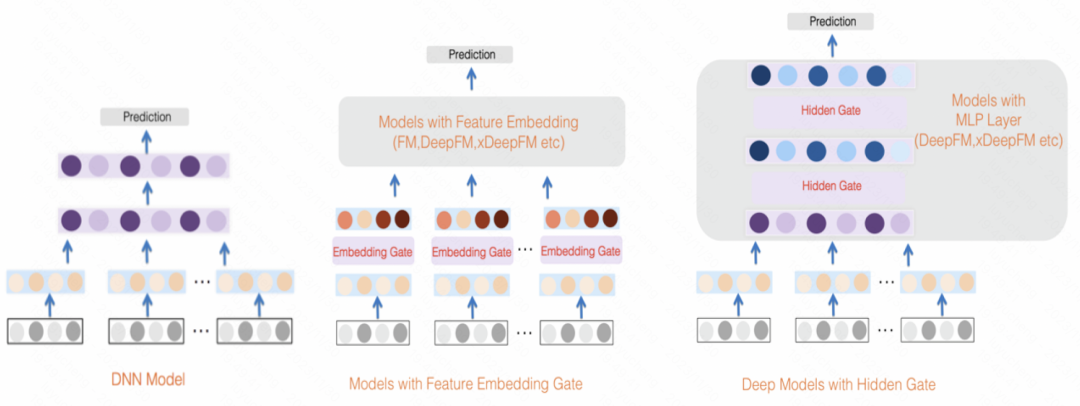 图片
图片
Interpretable Click-Through Rate Prediction through Hierarchical Attention(WSDM 2020)也是利用self-attention实现特征的转换,但是增加了高阶特征的生成。这里面使用层次self-attention,每一层的self-attention以上一层sefl-attention的输出作为输入,每一层增加了一阶高阶特征组合,实现层次多阶特征提取。具体来说,每一层进行self-attention后,将生成的新特征矩阵经过softmax得到每个特征的权重,根据权重对原始特征加权新的特征,再和原始特征进行一次点积,实现增加一阶的特征交叉。
 图片
图片
ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding(2021)也是类似的做法,使用一个MLP将所有特征映射成一个每个特征embedding尺寸的维度,对原始特征做一个缩放,文中针对每个特征使用了个性化的MLP参数。通过这种方式,利用样本中的其他特征作为上下位增强每个特征。
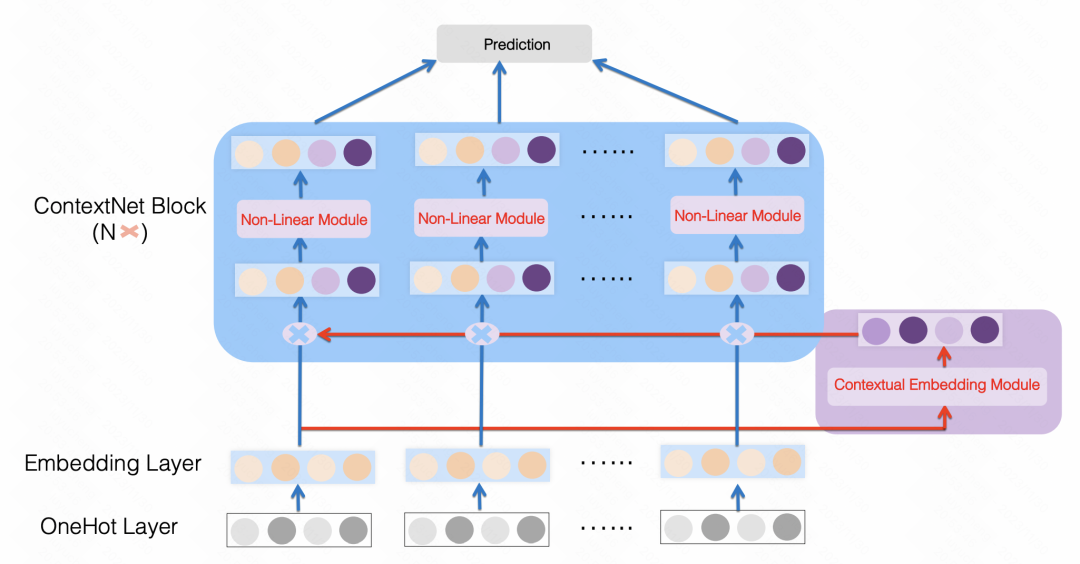 图片
图片
Enhancing CTR Prediction with Context-Aware Feature Representation Learning(SIGIR 2022)采用了self-attention进行特征增强,对于一组输入特征,每个特征对于其他特征的影响程度是不同的,通过self-attention,对每个特征的embedding进行一次self-attention,实现样本内特征间的信息交互。除了特征间的交互,文中也利用MLP进行bit级别的信息交互。上述生成的新embedding,会通过一个gate网络,和原始的embedding进行融合,得到最终refine后的特征表示。
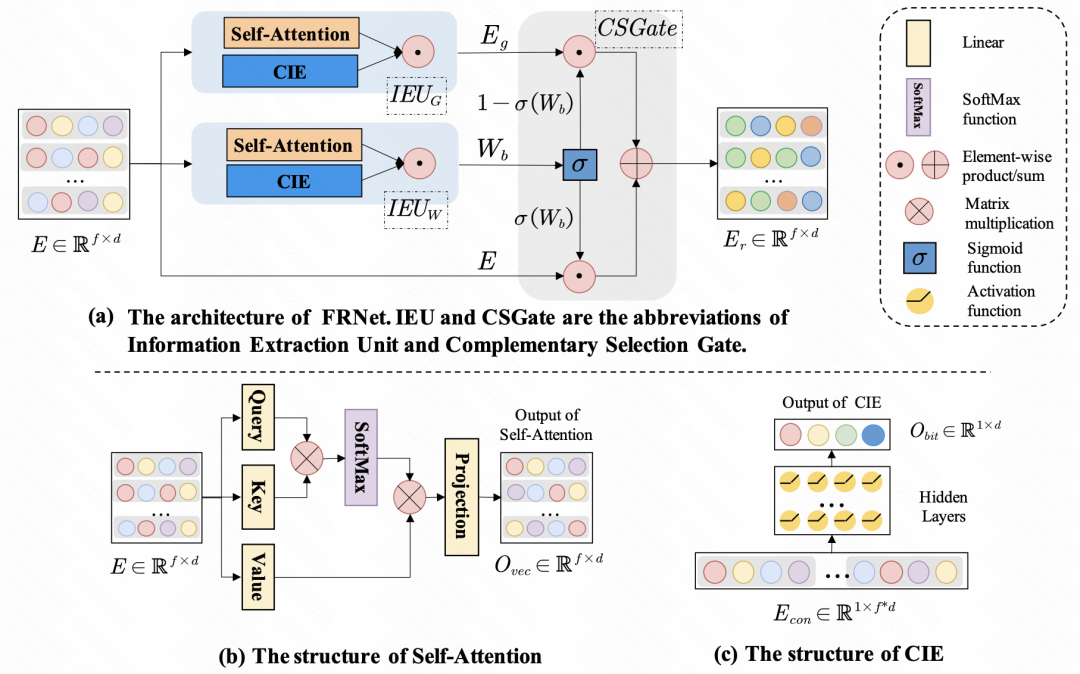 图片
图片
3、实验效果
进行了各类特征增强方法的效果对比后,得出整体结论:在众多特征增强模块中,GFRL、FRNet-V、FRNetB表现最优,且效果优于其他特征增强方法
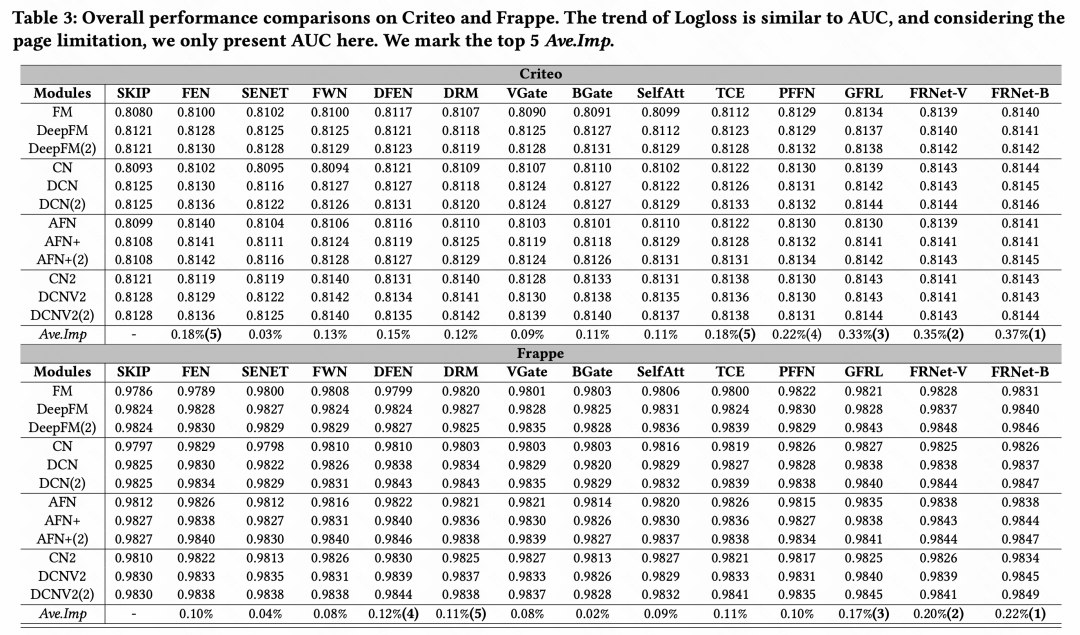 图片
图片
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 领克汽车全新09 EM-P车型即将预售,定位“超电SUV旗舰”
- 12月15日消息,领克汽车近日宣布,即将在12月20日19:30开始预售其全新车型,命名为09EM-P,被官方定位为“超电SUV旗舰”。在外观方面,新车进行了一系列的外观调整,包括重新设计的进气格栅和两侧进气口的装饰,与此前发布的远航版车型相似。根据消息,现款远航版车型的尺寸为5042/1977/1780毫米,轴距为2981毫米,新车将在此基础上进行进一步的改进。据小编了解,领克汽车总经理陆昕表示,新车的研发投入相当巨大,总额接近3亿,其中双腔空气悬架投资超过6000万。第二排座椅将提供加热、通风和按摩功
- 22小时前 16:50 领克 0
-
 正版软件
正版软件
- 韩国:计划2030年向机器人产业投资3万亿韩元,机器人产业规模将超20万亿韩元【附机器人行业发展现状分析】
- 图片来源:摄图网韩国产业通商资源部周四表示,计划到2030年向私营部门投资3万亿韩元(合23亿美元),以提高机器人产业的竞争力。通过这笔投资,韩国计划确保机器人产业的八项关键技术,包括自动化技术。全面的研究路线图预计将于2024年上半年发布。预计到2030年,年销售额超过1000亿韩元的机器人企业预计将从2021年的5家增加到30家。韩国政府还计划到2030年将服务机器人的数量从目前的6.3万台增加到70万台。韩国产业通商资源部表示,预计到2030年,韩国机器人产业规模将从目前的5.6万亿韩元大幅增加到2
- 昨天 05-10 03:30 0
-
 正版软件
正版软件
- 荣耀90 GT确认发布日期:12月21日惊艳亮相
- 12月15日消息,荣耀将于12月21日正式发布其最新产品荣耀90GT。荣耀官方表示,这款手机旨在提供卓越的性能,并将全面融入游戏体验的基因,被定位为“性能灭霸”根据官方透露的信息,荣耀90GT的背面采用了素皮材质,后置摄像头呈矩形DECO设计,并在摄像头模组上印有醒目的GT标识。此外,两条线条从手机的上部穿过,既保持了简洁的外观风格,又增加了一定的辨识度。手机的中框采用直角边设计,正面则搭载了中置挖孔直屏,非常适合游戏爱好者使用。在核心配置方面,荣耀90GT采用了高通骁龙8Gen2移动平台,这款芯片是使用
- 前天 05-09 03:25 荣耀 0
-
 正版软件
正版软件
- 联想率先推出搭载个人大模型AI的PC
- 12月15日消息,联想集团的副总裁兼中国区首席市场官王传东表示,随着AI时代的到来,AIPC将成为广泛普及的首选计算终端。他指出,明年,联想的AIPC将首次搭载个人大模型,这将为未来的计算体验带来巨大变革。他还强调,AI与PC的结合将形成一种全新的混合体,包括算力平台、个人大模型以及各种AI应用。根据我的了解,王传东认为,公共大模型在AI领域已经有了重要的进展,但它们仍然不能完全满足个性化的AI需求,并且无法保障个人数据和隐私的安全。相比之下,个人电脑作为一个多功能的生产力平台,以及其强大的个人计算和存储
- 4天前 联想 0
-
 正版软件
正版软件
- 宏碁推出Predator Triton Neo 16笔记本,搭载酷睿Ultra和RTX 40,性能大幅提升
- 12月15日消息,宏碁昨日发布了全新的PredatorTritonNeo16笔记本电脑,它配备了先进的硬件配置,包括酷睿Ultra处理器和RTX40独立显卡,并且还拥有一块出色的16英寸3.2K165Hz屏幕据小编了解,PredatorTritonNeo16笔记本内置了先进的散热技术,结合了第5代AeroBlade风扇和CPU的液态金属散热膏,确保了高性能运行时的出色散热效果。这款笔记本搭载全新的酷睿UltraH系列处理器,可选配支持NVIDIADLSS3.5技术的RTX4070GPU,获得了NVIDIA
- 5天前 宏碁 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1613天前
-
 2
2
- Overture设置踏板标记的方法
- 1450天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1440天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1638天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1604天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1600天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1615天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1636天前
-
 9
9
相关推荐
- 领克汽车全新09 EM-P车型即将预售,定位“超电SUV旗舰”
- 韩国:计划2030年向机器人产业投资3万亿韩元,机器人产业规模将超20万亿韩元【附机器人行业发展现状分析】
- 荣耀90 GT确认发布日期:12月21日惊艳亮相
- 联想率先推出搭载个人大模型AI的PC
- 宏碁推出Predator Triton Neo 16笔记本,搭载酷睿Ultra和RTX 40,性能大幅提升
- 全新凯迪拉克VISTIQ即将亮相!纯电动驱动,令人期待其卓越性能参数!
- 荣耀保时捷设计版手机曝光:充满保时捷灵魂的时尚之选
- 努比亚Z60 Ultra手机预热:结合骁龙8 Gen 3+和80W快充,带来双重强劲动力
- 联想发布英特尔酷睿Ultra加持的多款商用和消费级AI PC产品
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00