QTNet:全新时序融合方案解决方案,适用于点云、图像和多模态检测器(NeurIPS 2023)
 发布于2024-04-21 阅读(0)
发布于2024-04-21 阅读(0)
扫一扫,手机访问
写在前面 & 个人理解
时序融合是提升自动驾驶3D目标检测感知能力的有效途径,但目前的方法在实际自动驾驶场景中应用存在成本开销等问题。最新研究文章《基于查询的显式运动时序融合用于3D目标检测》在NeurIPS 2023中提出了一种新的时序融合方法,将稀疏查询作为时序融合的对象,并利用显式运动信息来生成时序注意力矩阵,以适应大规模点云的特性。该方法由华中科技大学和百度的研究者提出,被称为QTNet:基于查询和显式运动的3D目标检测时序融合方法。实验证明,QTNet能够在几乎没有成本开销的情况下为点云、图像和多模态检测器带来一致的性能提升

- 论文链接:https://openreview.net/pdf?id=gySmwdmVDF
- 代码链接:https://github.com/AlmoonYsl/QTNet
问题背景
得益于现实世界的时间连续性,时间维度上的信息可以使得感知信息更加完备,进而提高目标检测的精度和鲁棒性,例如时序信息可以帮助解决目标检测中的遮挡问题、提供目标的运动状态和速度信息、提供目标的持续性和一致性信息。因此如何高效地利用时序信息是自动驾驶感知的一个重要问题。现有的时序融合方法主要分为两类。一类是基于稠密的BEV特征进行时序融合(点云/图像时序融合都适用),另一类则是基于3D Proposal特征进行时序融合 (主要针对点云时序融合方法)。对于基于BEV特征的时序融合,由于BEV上超过90%的点都是背景,而该类方法没有更多地关注前景对象,这导致了大量没有必要的计算开销和次优的性能。对于基于3D Proposal的时序融合算法,其通过耗时的3D RoI Pooling来生成3D Proposal特征,尤其是在目标物较多,点云数量较多的情况下,3D RoI Pooling所带来的开销在实际应用中往往是难以接受的。此外,3D Proposal 特征严重依赖于Proposal的质量,这在复杂场景中往往是受限的。因此,目前的方法都难以以极低开销的方式高效地引入时序融合来增强3D目标检测的性能。
如何实现高效的时序融合?
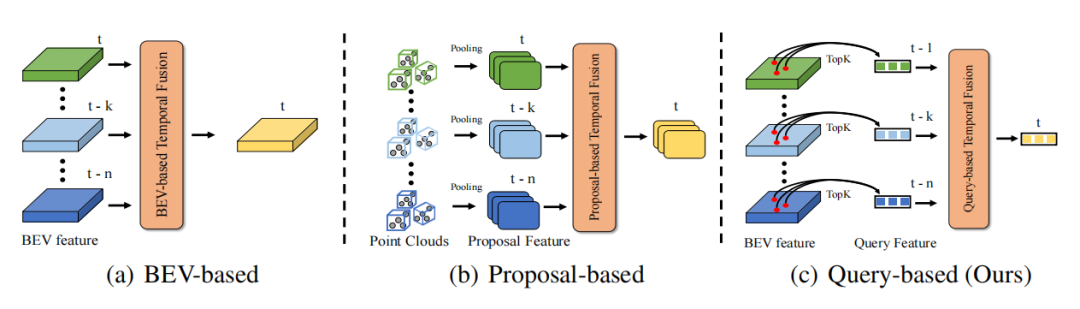
DETR是一种十分优秀的目标检测范式,其提出的Query设计和Set Prediction思想有效地实现了无需任何后处理的优雅检测范式。在DETR中,每个Query代表一个物体,并且Query相对于稠密的特征来说十分稀疏(一般Query的数目会被设置为一个相对较少的固定数目)。如果以Quey作为时序融合的对象,那计算开销的问题自然下降一个层次。因此DETR的Query范式是一种天然适合于时序融合的范式。时序融合需要构建多帧之间的物体关联,以此实现时序上下文信息的综合。那么主要问题在于如何构建基于Query的时序融合pipeline和两帧间的Query建立关联。
- 由于在实际场景中自车往往存在的运动,因此两帧的点云/图像往往是坐标系不对齐的,并且实际应用中不可能在当前帧对所有历史帧重新forward一次网络来提取对齐后点云/图像的特征。因此本文采用Memory Bank的方式来只存储历史帧得到的Query特征及其对应的检测结果,以此来避免重复计算。
- 由于点云和图像在描述目标特征上存在很大差异,通过特征层面来构建统一时序融合方法是不太可行的。然而,在三维空间下,无论点云还是图像模态都能通过目标的几何位置/运动信息关系来刻画相邻帧之间的关联关系。因此,本文采用物体的几何位置和对应的运动信息来引导两帧间物体的注意力矩阵。
方法介绍
QTNet的核心思想是利用Memory Bank存储在历史帧中获得的Query特征及其对应的检测结果,以避免重复计算历史帧的开销。在两帧Query之间,使用运动引导的注意力矩阵进行关系建模
总体框架
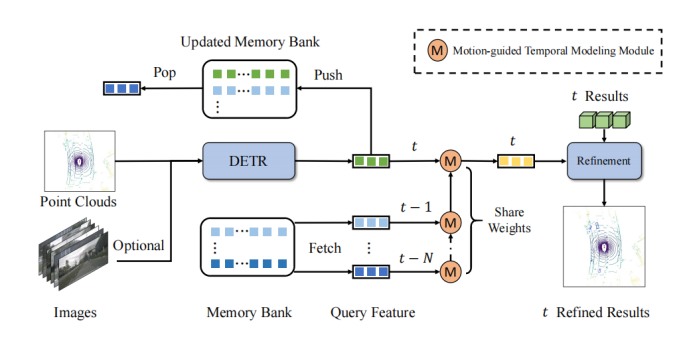
如框架图所示,QTNet包含3D DETR结构的3D目标检测器(LiDAR、Camera和多模态均可),Memory Bank和用于时序融合的Motion-guided Temporal Modeling Module (MTM)。QTNet通过DETR结构的3D目标检测器获取对应帧的Query特征及其检测结果,并将得到的Query特征及其检测结果以先进先出队列(FIFO)的方式送入Memory Bank中。Memory Bank的数目设置为时序融合所需的帧数。对于时序融合,QTNet从Memory Bank中从最远时刻开始读取数据,通过MTM模块以迭代的方式从 帧到 帧融合MemoryBank中的所有特征以用来增强当前帧的Query特征,并根据增强后的Query特征来Refine对应的当前帧的检测结果。
具体而言,QTNet在 帧融合 和 帧的Query特征 和 ,并得到增强后的 帧的Query特征 。接着,QTNet再将 与 帧的Query特征进行融合。以此通过迭代的方式不断融合至 帧。注意,这里从 帧到 帧所使用的MTM全部是共享参数的。
运动引导注意力模块
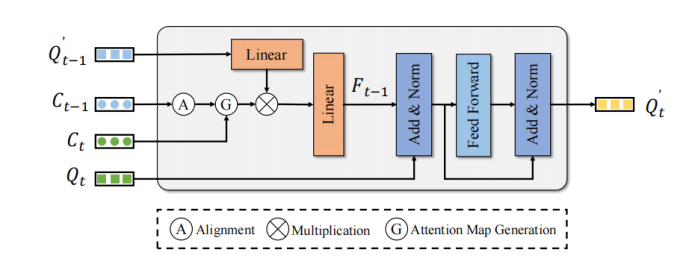
MTM使用物体的中心点位置来显式生成 帧Query和 帧Query的注意力矩阵。给定ego pose矩阵 和 、物体中心点、速度。首先,MTM使用ego pose和物体预测的速度信息将上一帧的物体移动到下一帧并对齐两帧的坐标系:
接着通过 帧物体中心点和 帧经过矫正的中心点构建欧式代价矩阵 。此外,为了避免可能发生的错误匹配,本文使用类别 和距离阈值 构造注意力掩码 :
将代价矩阵转换成注意力矩阵是最终目标
将注意力矩阵 作用在 帧的增强后的Query特征 来聚合时序特征以增强 帧的Query特征:
最终增强后的 帧的Query特征 经过简单的FFN来Refine对应的检测结果,以实现增强检测性能的作用。
解耦时序融合结构

观察到时序融合的分类和回归学习存在不平衡问题,一种解决办法是分别为分类和回归设计时序融合分支。然而,这种解耦方式会增加更多的计算成本和延迟,对于大多数方法而言不可接受。相比之下,QTNet利用高效的时序融合设计,其计算成本和延迟可以忽略不计,与整个3D检测网络相比表现更优。因此,本文采取了分类和回归分支在时序融合上的解耦方式,以在可忽略不计的成本情况下取得更好的检测性能,如图所示
实验效果
QTNet在点云/图像/多模态上实现一致涨点
在nuScenes数据集上进行验证后发现,QTNet在不使用未来信息、TTA和模型集成的情况下,取得了68.4的mAP和72.2的NDS,达到了SOTA性能。与使用了未来信息的MGTANet相比,在3帧时序融合的情况下,QTNet的性能优于MGTANet,分别提高了3.0的mAP和1.0的NDS
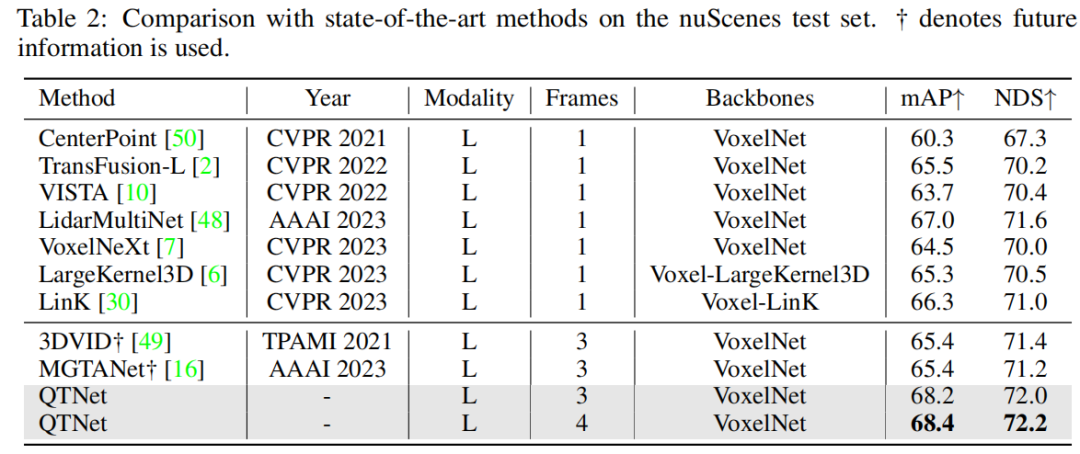
此外,本文也在多模态和基于环视图的方法上进行了验证,在nuScenes验证集上的实验结果证明了QTNet在不同模态上的有效性。
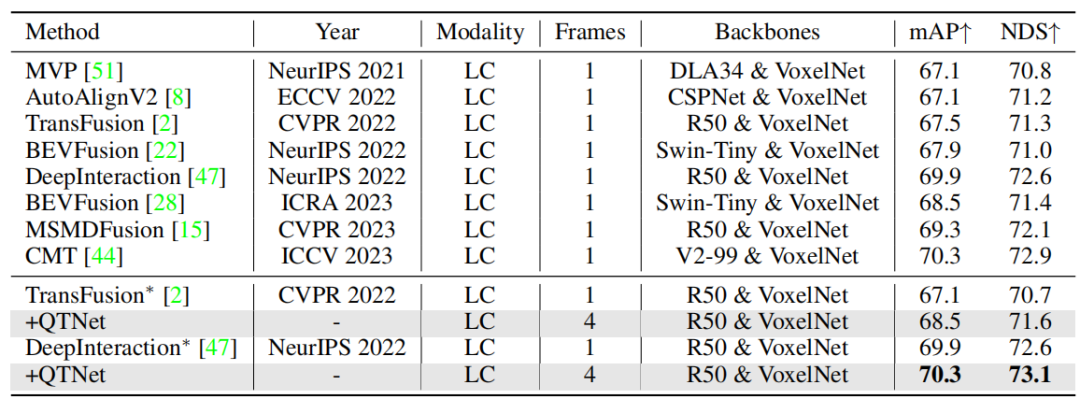

对于实际应用来说,时序融合的成本开销非常重要。本文对QTNet在计算量、时延和参数量三个方面进行了分析实验。结果表明,与整个网络相比,QTNet对于不同基准线所带来的计算开销、时间延迟和参数量都可以忽略不计,尤其是计算量仅仅使用了0.1G FLOPs(LiDAR基准线)
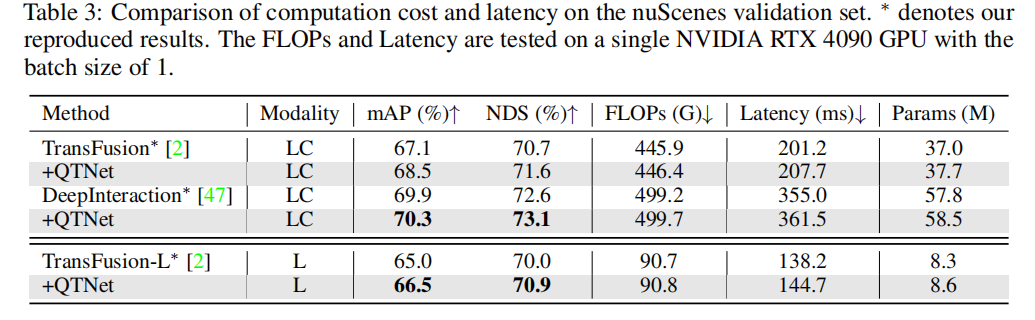
不同时序融合范式比较
为了验证基于Query的时序融合范式的优越性,我们选择了具有代表性的不同前沿时序融合方法进行比较。通过实验结果发现,基于Query范式的时序融合算法相较于基于BEV和基于Proposal范式更加高效。在仅使用0.1G FLOPs和4.5ms的开销下,QTNet表现出更加优秀的性能,同时整体参数量仅为0.3M
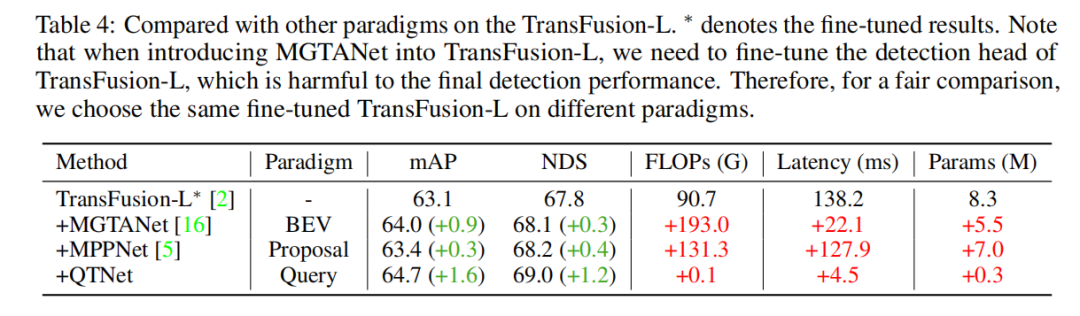
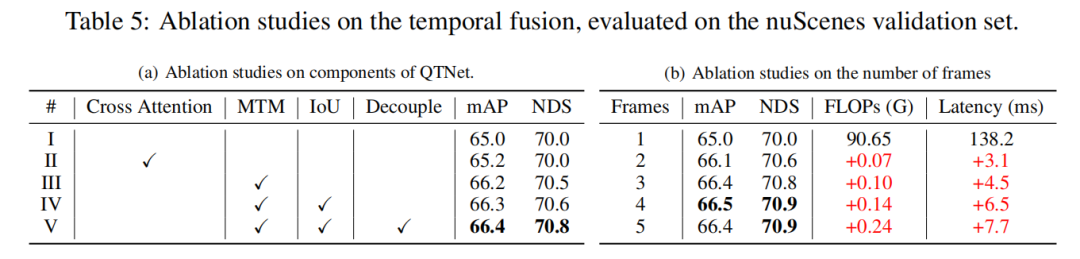
消融实验
本研究在nuScenes验证集上进行了基于LiDAR baseline的消融实验,通过3帧时序融合的方式。实验结果表明,简单地使用Cross Attention来建模时序关系并没有明显的效果。然而,当使用MTM后,检测性能显著提升,这说明在大规模点云下显式运动引导的重要性。此外,通过消融实验还发现,QTNet的整体设计非常轻量且高效。在使用4帧数据进行时序融合时,QTNet的计算量仅为0.24G FLOPs,延迟也只有6.5毫秒
MTM的可视化
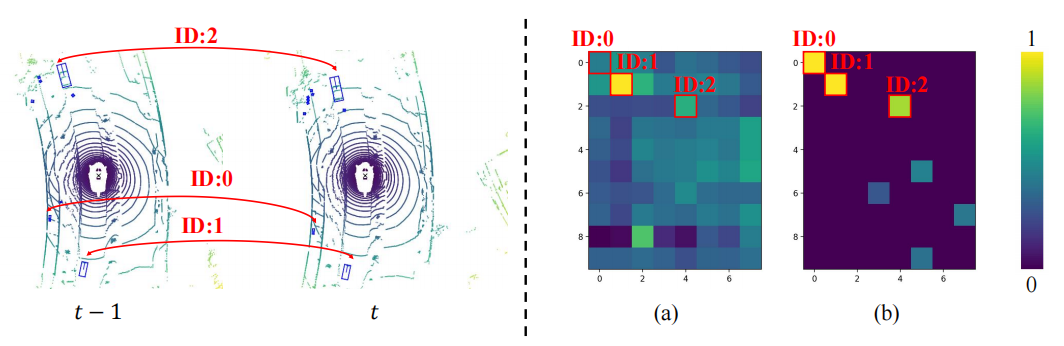
为了探究MTM优于Cross Attention的原因,本文将两帧间物体的注意力矩阵进行可视化,其中相同的ID代表两帧间同一个物体。可以发现由MTM生成的注意力矩阵(b)比Cross Attention生成的注意力矩阵(a)更加具有区分度,尤其是小物体之间的注意力矩阵。这表明由显式运动引导的注意力矩阵通过物理建模的方式使得模型更加容易地建立起两帧间物体的关联。本文仅仅只是初步探索了在时序融合中以物理方式建立时序关联问题,对于如何更好构建时序关联仍然是值得探索的。
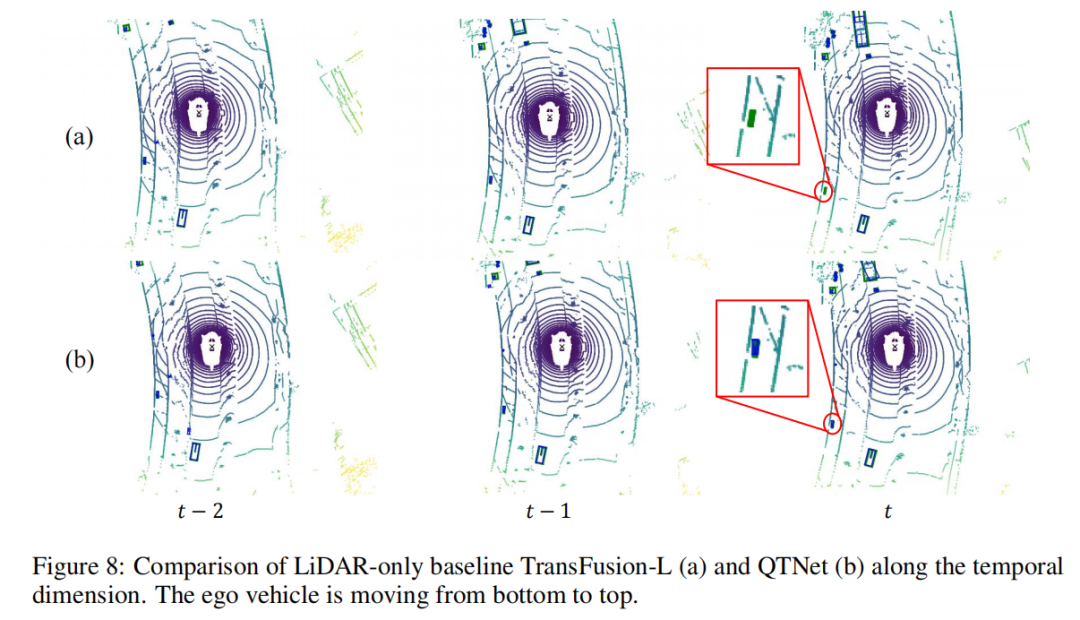
检测结果的可视化
本文以场景序列为对象进行了检测结果的可视化分析。可以发现左下角的小物体从 帧开始快速远离自车,这导致baseline在 帧漏检了该物体,然而QTNet在 帧仍然可以检测到该物体,这证明了QTNet在时序融合上的有效性。
本文总结
本文针对目前3D目标检测任务提出了更加高效的基于Query的时序融合方法QTNet。其主要核心有两点:一是使用稀疏Query作为时序融合的对象并通过Memory Bank存储历史信息以避免重复的计算,二是使用显式的运动建模来引导时序Query间的注意力矩阵的生成,以此实现时序关系建模。通过这两个关键思路,QTNet能够高效地实现可应用于LiDAR、Camera、多模态的时序融合,并以可忽略不计的成本开销一致性地增强3D目标检测的性能。

需要重新改写的内容是:原文链接:https://mp.weixin.qq.com/s/s9tkF_rAP2yUEkn6tp9eUQ
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 联想发布英特尔酷睿Ultra加持的多款商用和消费级AI PC产品
- 【CNMO新闻】12月15日,据CNMO了解,联想集团推出了多款商用和消费级笔记本电脑,旨在开启全新的人工智能体验。据悉,新款ThinkPadX1Carbon、ThinkPadX二合一以及小新Pro162024和IdeaPadPro5i均搭载了最新的英特尔酷睿Ultra处理器和Windows11系统。搭载英特尔酷睿Ultra处理器的联想笔记本电脑集成了三个计算引擎:CPU、GPU和NPU,能够高效且智能地处理AIPC任务。通过将计算任务分流至NPU和/或GPU,可提升效率和性能,还能实现更优的电源管理。联
- 9小时前 16:45 0
-
 正版软件
正版软件
- 领克汽车宣布全新领克09 E-MP即将开始预售,新车将增添双腔空悬和副驾屏幕功能
- 12月15日消息,领克汽车今日宣布,旗下的全新领克09E-MP将于12月20日正式开始预售。这款新车将带来一系列升级,包括副驾驶屏幕的增加、全新座椅系统的升级,以及双腔空气悬架的加入,以提供更出色的驾驶体验。根据小编了解,领克汽车总经理陆昕在媒体采访中透露,新款领克09E-MP的研发投入相当巨大,总计达到约3亿人民币,其中双腔空气悬架的研发投资已超过6000万元。新款车型被定位为“超电SUV旗舰”这款新车将引入全新外观设计,前脸经过重新调整,包括进气格栅造型和进气口的装饰等方面的变化。车内方面,第二排座椅
- 23小时前 02:50 领克 0
-
正版软件
- 真我GT5 Pro手机备件价格发布,全国统一维修指导价曝光
- 12月15日消息,realme官网近日发布了真我GT5Pro手机的维修备件价格列表。以下是价格清单:主板(12GB+256GB)价格为2249元主板(16GB+1TB)的价格为2649元-主板(16GB+512GB):2449元-电池:159元-电池盖组件:359元重写内容为:长焦后置摄像头售价为459元广角后置摄像头:95元主摄像头后置:329元-屏幕:829元-前置摄像头:159元改写后的内容:适配器售价为149元重写内容:-数据线售价为39元-指纹模组:99元维修费用说明:维修费用是指维修服务所需的
- 昨天 05-01 02:45 Realme 0
-
 正版软件
正版软件
- 奔驰E级轿车全新登场:科技奢华与尊崇舒适完美融合
- 12月15日的消息是,昨晚国内市场上举行了盛大的发布会,正式推出了全新一代奔驰E级轿车。这款车型共推出了6种不同的车型,价格区间在44.9万元至52.98万元之间这款全新的奔驰E级经历了一次彻底的外观和内饰升级,旨在为消费者带来更多豪华与科技感。车辆搭载了高通8295芯片,提供了出色的智能化体验,并引入了11项专为中国市场打造的后排舒适配置。动力方面,车型依然采用2.0T发动机,提供高、低功率两种不同的调校版本。全新E级的前脸设计发生了重大变化,采用了奔驰车标与前格栅相融合的设计,整体造型更加现代科技感十
- 前天 04-30 02:40 奔驰 0
-
 正版软件
正版软件
- 智能时代的引领者:vivo S18系列手机发布,AI蓝心大模型助力
- 12月15日消息,vivo公司最新发布的S18系列手机已经正式面世,包括S18e、S18和S18Pro三款机型,其起售价从2099元起。据vivo披露的数据显示,在S18系列开启预售仅1小时后,全网的预订数量较上一代同期猛增了2.6倍。S18系列的一大亮点是首次搭载vivo自家研发的AI蓝心大模型。该模型具备多项智能功能,包括文件检索、诗词创作、文创图片生成、背景人物消除、内容总结、难题解答以及材料框架整理等。而S18Pro则更加独具特色,内置了vivo数字影棚功能。用户可一键生成个人写真照片,适用于简历
- 4天前 vivo 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1604天前
-
 2
2
- Overture设置踏板标记的方法
- 1442天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1431天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 1630天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1595天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1591天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1606天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 1628天前
-
 9
9
相关推荐
- 联想发布英特尔酷睿Ultra加持的多款商用和消费级AI PC产品
- 领克汽车宣布全新领克09 E-MP即将开始预售,新车将增添双腔空悬和副驾屏幕功能
- 真我GT5 Pro手机备件价格发布,全国统一维修指导价曝光
- 奔驰E级轿车全新登场:科技奢华与尊崇舒适完美融合
- 智能时代的引领者:vivo S18系列手机发布,AI蓝心大模型助力
- 努比亚Z60 Ultra发布预告:首次亮相硅碳负极电池技术!
- 第一步:在 Windows 上安装 Linux,使用微软 Windows AI Studio 工具
- 大疆发布全新8K电影机 Ronin 4D-8K,专为专业创作者打造
- 新的标题:联想 AI PC 将率先搭载个人大模型,猿辅导推出非教辅图书
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00