电脑浏览器User Agent查询方法
 发布于2026-01-24 阅读(0)
发布于2026-01-24 阅读(0)
扫一扫,手机访问
在使用Python编写网页爬虫时,若未在请求头中设置User-Agent字段,往往会导致无法成功抓取目标页面内容。这是因为许多网站会主动拦截或拒绝来自未知或无标识客户端的访问请求。解决方法是通过浏览器开发者工具获取当前浏览器真实的User-Agent字符串,并将其作为headers参数的一部分传递给HTTP请求,从而模拟真实用户行为。
1、 启动浏览器,在地址栏中直接输入 about:version 并回车,即可快速查看当前浏览器的详细版本及配置信息。该方式操作简单、响应迅速,如您掌握更高效或更通用的获取方式,欢迎留言探讨。
2、 执行上述操作后,浏览器将展示如下界面,其中红色方框标注区域即为当前环境所使用的User-Agent字符串。
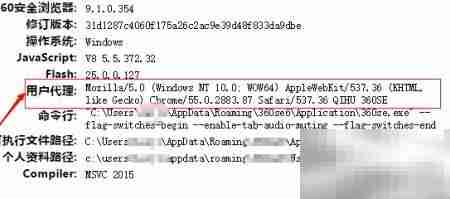
3、 在Python中发起网络请求前,需确保已正确构造包含User-Agent的请求头;同时可参考下图所示步骤,在浏览器中打开开发者工具(通常按F12),切换至Network标签页,刷新页面后点击任意请求项,即可在Headers面板中找到并复制User-Agent值。

本文转载于:https://soft.zol.com.cn/1090/10903922.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:Go语言高效字符串拼接技巧
下一篇:淘宝联系卖家方法及客服操作步骤
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- SPSS安装步骤详解与教程
- 学习SPSS软件的第一步是完成程序的安装,掌握正确的安装流程是本章的核心内容,为接下来的使用奠定基础。1、双击安装文件,并输入指定的解压密码,解压后开始安装过程。待解压和初始化完成后,便可进入后续步骤。2、第二步,安装程序正在运行中。由于计算机性能差异,若设备运行速度较慢,可能需要等待较长时间,请保持耐心,避免中断操作。3、第三,注意检查磁盘空间。根据SPSS的系统要求,安装路径所在驱动器必须有足够的可用空间,否则会因空间不足而造成安装失败。4、第四,在安装过程中若出现选项界面,应根据当前情况做出
- 1小时前 19:41 0
-
 正版软件
正版软件
- Excel提取括号内文字方法【教程】
- 可使用五种方法提取括号内文本:一、SUBSTITUTE与MID组合公式提取首对英文括号内容;二、FILTERXML函数提取所有括号内容并返回数组;三、TEXTBEFORE与TEXTAFTER链式提取最邻近右括号的括号内容;四、PowerQuery可视化分步拆分;五、VBA自定义函数支持嵌套及全角括号识别。
- 1小时前 19:29 0
-
 正版软件
正版软件
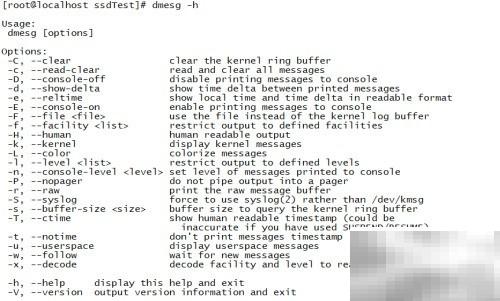
- CentOS7实时查看内核日志方法
- 系统运行状态的监控通常依赖于内核日志,这些日志信息保存在/var/log/dmesg文件中。为了及时发现并响应异常,部分日志需要持续跟踪后台的动态记录。1、使用dmesg命令可查看系统的后台日志信息,若输出内容较长,建议结合less工具进行分页浏览,便于查阅。2、查看dmesg命令的帮助文档,可通过-h参数获取详细的使用说明和选项列表。3、使用-w参数可以开启实时日志监听模式,持续输出新的内核消息;配合-H参数可启用更清晰的时间戳格式,提升日志可读性。4、方法二:结合
- 1小时前 19:17 0
-
 正版软件
正版软件
- 2026免费域名注册平台实测攻略
- 2026年仍可用的免费域名服务包括:一、DNSHe提供.tk/.ml等免费一级域名;二、ClouDNSFreeZone支持永久免费二级域名;三、register.us.kg允许Unicode字符二级域名;四、eu.org提供人工审核但长期稳定的二级域名;五、InfinityFree附赠永久子域名。
- 2小时前 19:05 0
-
 正版软件
正版软件
- Excel工作表公式不计算怎么解决
- 首先检查并启用自动计算模式,进入公式选项卡,将计算选项设置为自动;接着通过文件→选项→公式→自动重算,永久开启自动计算;最后按F9强制重算,验证公式是否正常更新。
- 2小时前 18:53 Excel 自动计算 0
最新发布
-
 1
1
- 《抖音》充值抖币官网入口
- 485天前
-
 2
2
- 大麦网官网订票入口
- 380天前
-
 3
3
- 直接点击打开漫蛙网页版
- 495天前
-
 4
4
- 天堂漫画免费入口及最新观看链接
- 167天前
-
 5
5
- 喵趣漫画官网
- 488天前
-
 6
6
- B站免费入口长期可用指南
- 228天前
-
 7
7
- 中国裁判文书网官网入口查询
- 156天前
-
 8
8
- 次元城动漫官网入口
- 448天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00