统计字典中值列表的唯一组合及其出现频次,可以通过以下步骤实现:方法一:使用 collections.defaultdict 和 tuple将每个值列表转换为元组
 发布于2026-04-21 阅读(0)
发布于2026-04-21 阅读(0)
扫一扫,手机访问

本文介绍如何准确统计字典中所有值列表(如 ['x', 'y'])的标准化组合(排序后去重)及其出现次数,并按频次降序输出形如 n=5: ('x', 'y') 的结果,避免因字典键重复导致的覆盖问题。
本文介绍如何准确统计字典中所有值列表(如 `['x', 'y']`)的标准化组合(排序后去重)及其出现次数,并按频次降序输出形如 `n=5: ('x', 'y')` 的结果,避免因字典键重复导致的覆盖问题。
在处理类似 {'HH1': ['x'], 'HH2': ['y', 'x'], 'HH3': ['x', 'z'], ...} 这样的数据时,核心目标是:将每个值列表标准化为有序元组(如 ['y', 'x'] → ('x', 'y')),然后统计每种标准化组合在整个字典中出现的精确次数。常见错误包括:
- 对子集组合(如 combinations(..., r))进行计数 → 导致统计的是“子集出现频次”,而非“原始列表匹配频次”;
- 用 n=count 作为字典键 → 因多个不同组合可能具有相同频次(如两个组合都出现 1 次),造成后写入覆盖前写入;
- 未对列表排序即转元组 → ['x','y'] 和 ['y','x'] 被视为不同键,无法合并。
✅ 正确解法的关键在于:以标准化元组为字典键,频次为值。以下是推荐实现(简洁、高效、语义清晰):
from collections import defaultdict
HH_dict = {
'HH1': ['x'], 'HH2': ['y', 'x'], 'HH3': ['x', 'z'], 'HH4': ['x'], 'HH5': ['x'],
'HH6': ['x'], 'HH7': ['x'], 'HH8': ['x', 'y', 'z'], 'HH9': ['x'], 'HH10': ['x', 'y'],
'HH11': ['x'], 'HH12': ['x'], 'HH13': ['x'], 'HH14': ['x'], 'HH15': ['x', 'y'],
'HH16': ['x', 'y'], 'HH17': ['x', 'y'], 'HH18': ['x']
}
# 步骤1:统计每种标准化组合(排序后转tuple)的出现次数
combination_count = defaultdict(int)
for lst in HH_dict.values():
# 标准化:去重 + 排序 + 转元组(确保 ['y','x'] 和 ['x','y'] 视为同一组合)
key = tuple(sorted(set(lst)))
combination_count[key] += 1
# 步骤2:按频次降序输出(频次相同时可选按元组字典序升序,增强可读性)
for combo, count in sorted(combination_count.items(), key=lambda x: (-x[1], x[0])):
print(f"n={count}: {combo}")输出结果:
n=11: ('x',)
n=5: ('x', 'y')
n=1: ('x', 'z')
n=1: ('x', 'y', 'z')? 关键说明:
- set(lst) 消除列表内重复元素(虽本例无重复,但属健壮性保障);
- sorted(...) 确保顺序一致,使等价组合映射到同一键;
- 使用 defaultdict(int) 或原生 dict 手动判断(如答案中所示)均可,避免 Counter 在此处的误用;
- sorted(..., key=lambda x: (-x[1], x[0])) 实现主序按频次降序、次序按组合升序,使输出稳定且易读。
⚠️ 注意事项:
- 不要使用 n=count 作为输出字典的键(如 renamed_lists[f"n={count}"]),这会丢失信息;
- 避免遍历 combinations(..., r)——本题要求的是完整列表的匹配,而非其幂集;
- 若原始数据中存在空列表 [],需单独处理(tuple(sorted(set([]))) 得 ()),根据业务决定是否纳入统计。
该方法时间复杂度为 O(N×M log M),其中 N 为字典长度,M 为单个列表平均长度,兼顾效率与可维护性,适用于中等规模数据场景。
本文转载于:互联网 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
下一篇:古文岛版本号查看方法详解
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 使用PHP和PhpSpreadsheet在Excel中插入图片的完整代码
- 用PHP和PhpSpreadsheet给Excel报表插上“图片”的翅膀 在后端开发中,生成带数据的Excel报表是家常便饭,但若想让报表图文并茂,直观地展示产品、课程或人员信息,就需要在单元格里精准地插入图片。今天,我们就来聊聊如何借助强大的PhpSpreadsheet库,让PHP轻松搞定这个需求
- 3分钟前 0
-
 正版软件
正版软件
- 使用JavaScript匹配URL中的查询参数的实现方法
- 引言 说起 Web 开发,处理 URL 里的查询参数(也有人习惯叫它“搜索内容”)几乎是家常便饭。你看网址里跟在 ? 后面的那串东西,比如 ?name=zhangsan&page=1,就是由一个个键值对组成的查询参数。能不能干净利落地把它们“拆解”出来,直接关系到动态页面渲染、表单数据传递乃至路由跳
- 4分钟前 0
-
 正版软件
正版软件
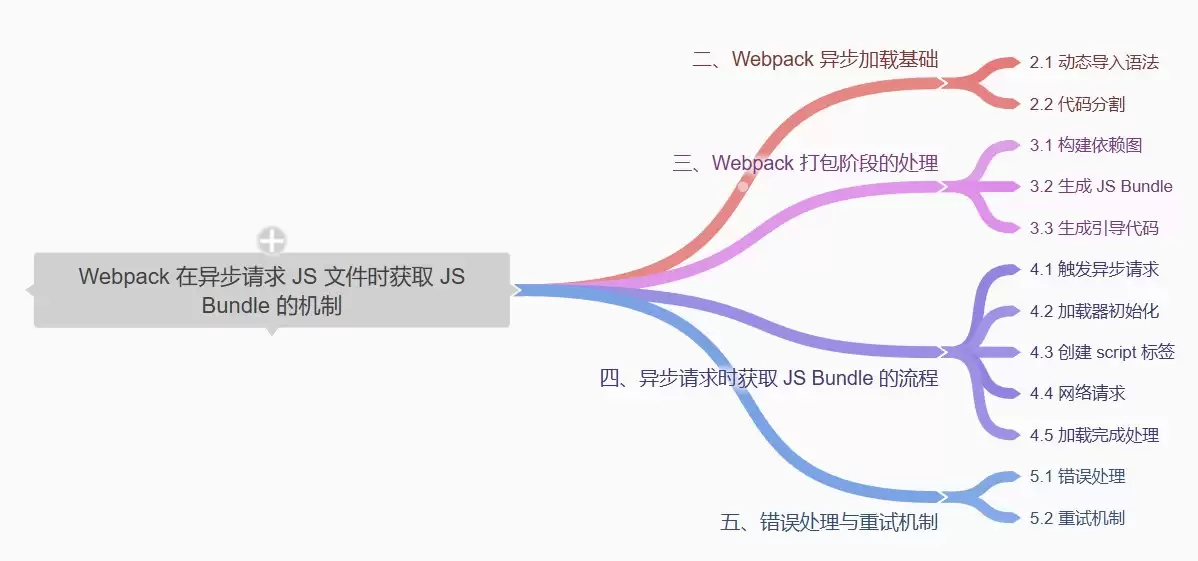
- Webpack在异步请求JS文件时如何获取JS Bundle的机制
- 一、引言 在前端开发的世界里,Webpack早已从一个可选项,成长为现代项目构建的基石。它像个熟练的打包工匠,把散落的模块整理成规整的JS Bundle,高效管理着项目的依赖与资源。要实现更流畅的用户体验,异步加载JS文件几乎是必由之路——毕竟,谁也不想首屏加载就背上所有代码的包袱。那么,当代码执行
- 5分钟前 0
-
 正版软件
正版软件
- cpustat怎样显示CPU温度和频率
- cpustat怎样显示CPU温度和频率 很多朋友在监控系统性能时,会用到 cpustat 这个工具。它确实能清晰地展示CPU的使用率情况,但这里有个常见的误解需要先澄清一下:cpustat 本身并不直接提供CPU温度和频率的读数。它主要隶属于 sysstat 软件包,职责在于统计CPU时间片的消耗。
- 6分钟前 0
-
 正版软件
正版软件
- Python函数返回新列表的正确方法
- Python函数不会自动修改原始变量;若函数返回新列表,必须显式赋值给变量才能获取结果,否则返回值会被丢弃。
- 7分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 225天前
-
4
- 探析Spring Boot框架的优点和特色
- 541天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 479天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 455天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1087天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 915天前
-
 9
9
- 解决Python安装失败的问题
- 465天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00