CentOS HDFS与其他大数据平台比较
 发布于2026-04-21 阅读(0)
发布于2026-04-21 阅读(0)
扫一扫,手机访问
定位与总体结论
在CentOS上部署HDFS,本质上是为海量数据搭建一个分布式的文件“地基”。这个系统天生为高吞吐量和横向扩展而生,遵循“一次写入、多次读取”的批处理逻辑,与MapReduce、Spark、Flink这些计算框架堪称黄金搭档。不过,咱们得先明确一点:HDFS并非“万能”存储。它和Ceph、MinIO这类统一存储或对象存储定位不同,与S3、OSS这类云上对象存储在数据访问语义和性能特征上,也存在显著差异。
那么,如何抉择?如果你的核心目标是构建数据湖或数据仓库,并且希望与Hadoop生态无缝集成,享受计算与存储紧密耦合带来的性能红利,那么以HDFS为中心是明智之选。反之,如果你的需求更偏向云原生、要求S3兼容性,或者希望一个平台统一管理块、文件和对象数据,那么就需要考虑其他方案来替代或补充HDFS了。
与主流平台对比
| 平台 | 类型与定位 | 关键特性 | 典型场景 | 与HDFS关系/差异 |
|---|---|---|---|---|
| HDFS | 分布式文件系统 | 高容错(多副本,默认3)、高吞吐、顺序I/O、数据局部性、NameNode HA | 大数据批处理、数据湖底层存储 | 作为大数据生态的“数据底座”,与计算框架深度耦合 |
| Ceph | 统一存储(对象/块/文件) | CRUSH算法、去中心化、副本/纠删码、强一致(块/对象)、可线性扩展 | 私有云/容器平台、块存储与对象存储统一供给 | 非HDFS语义;可与Hadoop生态集成,但元数据/一致性模型不同 |
| MinIO | 对象存储(S3兼容) | 高性能、轻量、云原生、纠删码、无单点 | 云原生应用、备份归档、数据湖“热层” | 与HDFS接口/语义不同;常作HDFS的替代或旁路层 |
| GlusterFS | 分布式文件系统 | 灵活卷管理、可扩展、高可用 | 跨节点共享文件、传统NAS替代 | 与HDFS同为文件系统,但架构与HDFS差异较大 |
| Amazon S3 / Aliyun OSS | 公有云对象存储 | 海量非结构化数据、REST API、最终一致(常见) | 云上数据湖、静态内容、备份 | 非POSIX/HDFS语义;需适配(如S3A/Hadoop S3 connector) |
| JuiceFS | 元数据服务 + 对象存储 | 高性能元数据(社区压测优于HDFS/OSS)、HDFS兼容、云原生 | 云上HDFS兼容、多租户元数据压力场景 | 可作为HDFS的云上替代或“缓存+对象存储”方案 |
| Swift | 对象存储(OpenStack) | 最终一致、REST API、可扩展 | OpenStack对象存储 | 与HDFS语义不同,定位对象存储 |
| GFS / GPFS | 分布式/并行文件系统 | 面向海量数据与高性能并行访问 | 大规模批处理、HPC/企业共享存储 | 架构理念与HDFS相近(GFS为HDFS蓝本),但多为专有/闭源或特定硬件生态 |
| Spark | 通用计算引擎 | 内存计算、DAG、迭代/交互式快 | 批处理、流处理、机器学习 | 常运行在HDFS之上;也可对接S3/对象存储等其他数据源 |
| Flink | 流批一体计算引擎 | 低延迟、状态容错、Exactly-once | 实时ETL、流式分析、状态计算 | 常将Checkpoint/Sa vepoint落HDFS;也可对接云存储 |
注:上表对比的核心在于存储语义、一致性模型、接口以及典型使用方式,旨在为技术选型提供清晰的取舍依据。
选型建议
- 场景一:批处理与数据湖核心。 如果你的业务以批处理为主,且高度依赖Hive、Spark、Flink、Impala等Hadoop生态工具,强调数据本地性带来的计算性能优势,那么HDFS(在成熟的CentOS/RHEL体系上部署)依然是首选。
- 场景二:云原生与对象存储。 如果需要云原生特性、S3兼容性、轻量易运维,或者面临多租户下元数据高并发访问的压力,那么MinIO或Ceph RGW(对象存储网关)是更合适的选择。如果已有业务强依赖HDFS但又想上云,可以引入JuiceFS作为兼容层或缓存加速层,实现平滑过渡。
- 场景三:统一存储平台。 对于追求在一个平台上同时提供对象、块和文件存储服务,并需要强一致性的企业私有云或容器平台,Ceph是强有力的竞争者。不过,需要留意CephFS在纯文件场景下的性能表现和运维复杂度。
- 场景四:公有云数据湖。 在公有云上构建数据湖或实施冷热数据分层,通常以S3/OSS这类原生对象存储为主存储。计算侧通过S3A Connector或JuiceFS进行对接。但必须警惕:对于低延迟随机访问敏感的业务,需谨慎评估直接用对象存储替代HDFS可能带来的性能影响。
- 场景五:高性能计算与企业共享。 传统的HPC环境或特定硬件生态下的企业共享文件系统,可以考虑GPFS等并行文件系统。如果追求开源和通用性,GlusterFS也是一个选项,但需要接受其与HDFS在语义和性能特征上的不同。
在CentOS上落地HDFS的关键要点
- 组件与高可用部署: 生产环境务必部署NameNode高可用(HA),通常搭配奇数个JournalNode(例如3台)以及ZooKeeper,并配置多个DataNode。网络方面,建议采用万兆以太网以消除瓶颈;为每个DataNode配置多块磁盘,能有效提升整体吞吐能力。
- 版本与兼容性考量: CentOS 7长期稳定,对Hadoop 2.x系列支持广泛;而CentOS 8或其后续的Stream版本更适合Hadoop 3.x及新特性,但需要注意Stream是滚动更新版本,部署前需进行充分测试。核心原则是:在部署前,必须明确Hadoop版本与CentOS版本、内核、glibc以及Ja va版本之间的兼容性矩阵。
- 容量与性能规划: 需要根据业务增长趋势来规划。NameNode的内存大小与元数据规模(文件数量和块数量)直接相关;DataNode的磁盘容量和副本数(默认3副本)决定了存储容量,虽然纠删码能降低容量开销,但会增加CPU消耗和恢复复杂度;块大小的设置(常见128MB或256MB)也会直接影响数据处理的效率。
本文转载于:https://www.yisu.com/ask/74378945.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 使用PHP和PhpSpreadsheet在Excel中插入图片的完整代码
- 用PHP和PhpSpreadsheet给Excel报表插上“图片”的翅膀 在后端开发中,生成带数据的Excel报表是家常便饭,但若想让报表图文并茂,直观地展示产品、课程或人员信息,就需要在单元格里精准地插入图片。今天,我们就来聊聊如何借助强大的PhpSpreadsheet库,让PHP轻松搞定这个需求
- 2分钟前 0
-
 正版软件
正版软件
- 使用JavaScript匹配URL中的查询参数的实现方法
- 引言 说起 Web 开发,处理 URL 里的查询参数(也有人习惯叫它“搜索内容”)几乎是家常便饭。你看网址里跟在 ? 后面的那串东西,比如 ?name=zhangsan&page=1,就是由一个个键值对组成的查询参数。能不能干净利落地把它们“拆解”出来,直接关系到动态页面渲染、表单数据传递乃至路由跳
- 3分钟前 0
-
 正版软件
正版软件
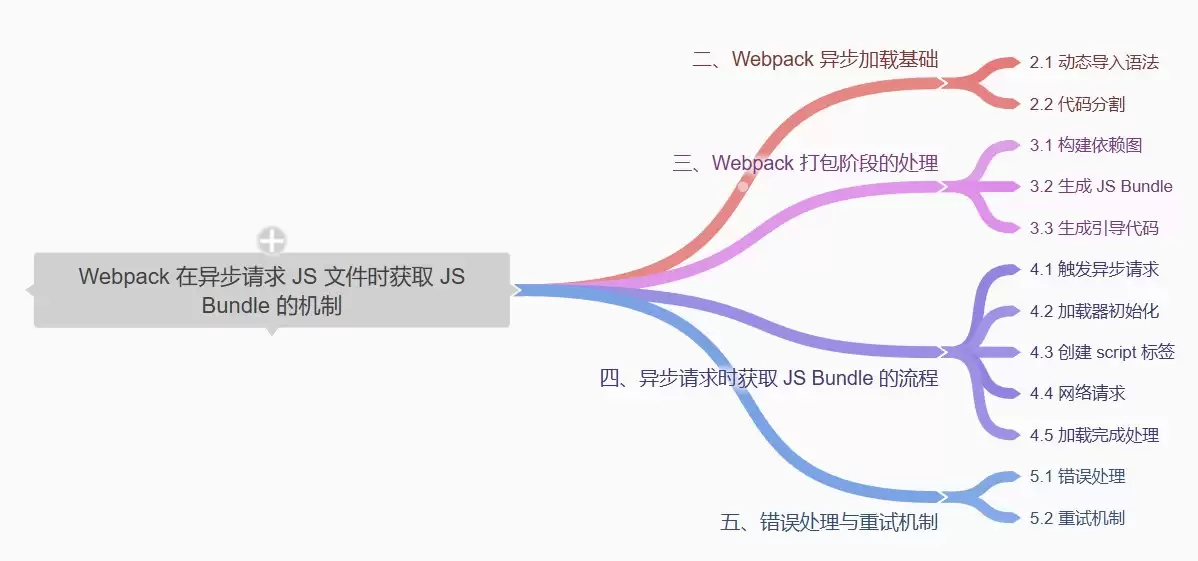
- Webpack在异步请求JS文件时如何获取JS Bundle的机制
- 一、引言 在前端开发的世界里,Webpack早已从一个可选项,成长为现代项目构建的基石。它像个熟练的打包工匠,把散落的模块整理成规整的JS Bundle,高效管理着项目的依赖与资源。要实现更流畅的用户体验,异步加载JS文件几乎是必由之路——毕竟,谁也不想首屏加载就背上所有代码的包袱。那么,当代码执行
- 4分钟前 0
-
 正版软件
正版软件
- cpustat怎样显示CPU温度和频率
- cpustat怎样显示CPU温度和频率 很多朋友在监控系统性能时,会用到 cpustat 这个工具。它确实能清晰地展示CPU的使用率情况,但这里有个常见的误解需要先澄清一下:cpustat 本身并不直接提供CPU温度和频率的读数。它主要隶属于 sysstat 软件包,职责在于统计CPU时间片的消耗。
- 5分钟前 0
-
 正版软件
正版软件
- Python函数返回新列表的正确方法
- Python函数不会自动修改原始变量;若函数返回新列表,必须显式赋值给变量才能获取结果,否则返回值会被丢弃。
- 5分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 225天前
-
4
- 探析Spring Boot框架的优点和特色
- 541天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 479天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 455天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1087天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 915天前
-
 9
9
- 解决Python安装失败的问题
- 465天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00