Debian Python数据分析怎样入门
 发布于2026-04-24 阅读(0)
发布于2026-04-24 阅读(0)
扫一扫,手机访问
Debian 上 Python 数据分析入门指南

一 环境准备与版本确认
万事开头先筑基。在Debian上开启数据分析之旅,第一步自然是把环境打理妥当。这个过程其实不复杂,但每一步都关乎后续的顺畅与否。
- 更新系统并安装基础工具:
- 打开终端,首先让系统保持最新状态:
sudo apt update && sudo apt upgrade。 - 接着,安装Python和包管理工具:
sudo apt install python3 python3-pip。这两个是后续所有操作的基石。
- 打开终端,首先让系统保持最新状态:
- 确认版本:
- 安装完成后,别忘了验证一下。分别运行
python3 --version和pip3 --version,确认版本信息无误。
- 安装完成后,别忘了验证一下。分别运行
- 建议做法: 强烈建议养成一个好习惯:为每个数据分析项目创建独立的虚拟环境(venv)。这能有效避免不同项目间的依赖包“打架”,是保持环境纯净的关键。以上这些步骤,是后续安装各种强大数据分析库的绝对前提。
二 两种常用环境方案
环境搭建好了,接下来怎么管理Python包?这里提供两条主流路径,各有千秋,你可以根据需求选择。
- 方案一 系统包 + venv(轻量、贴近系统)
- 创建环境:
python3 -m venv ~/venvs/data310(路径和名称可自定义)。 - 激活环境:
source ~/venvs/data310/bin/activate。激活后,终端提示符通常会变化,表示你已进入这个“隔离区”。 - 升级 pip:
pip install -U pip,确保包管理工具是最新的。 - 安装常用库:一口气装上核心全家桶:
pip install numpy pandas matplotlib seaborn jupyter scikit-learn。 - 退出环境:工作完成后,输入
deactivate即可退出。
- 创建环境:
- 方案二 Miniconda/Anaconda(跨平台、二进制包丰富)
- 下载安装脚本:例如,对于x86_64架构,使用
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh。 - 安装:运行下载的脚本并按提示操作(安装时可以选择不自动激活base环境,保持更清晰的控制)。
- 常用命令:
- 创建环境:
conda create -n datasci python=3.11 - 激活环境:
conda activate datasci - 安装库:
conda install numpy pandas matplotlib seaborn scikit-learn jupyter - 退出环境:
conda deactivate
- 创建环境:
- 下载安装脚本:例如,对于x86_64架构,使用
- 选择建议: 对于刚入门的初学者,从系统自带的venv开始更简单直接,能更好地理解Python环境本身。而当你需要处理大量科学计算包,或者追求跨操作系统(比如同时在Windows和Linux上工作)的环境一致性时,Miniconda或Anaconda会是更强大的选择。
三 入门流程与核心库
工具备齐,该了解下数据分析的“标准动作”和手中的“王牌武器”了。一个典型的数据分析流程,大致会遵循以下路径:
- 典型流程
- 数据收集与导入: 第一步,把数据“搬进来”,无论是CSV、Excel还是数据库。
- 数据清洗: 这是最耗时但也最关键的一步,处理缺失值、剔除重复、修正异常,让数据变得规整可用。
- 探索性数据分析(EDA): 开始与数据对话,进行统计描述、分组聚合、分析相关性,发现初步模式和洞察。
- 可视化: 一图胜千言,通过分布图、关系图、对比图等将数据直观呈现。
- 建模与分析: (可选但重要)运用机器学习方法进行分类、回归或聚类等深入分析。
- 结果评估与展示: 最后,用指标评估模型效果,并整理图表与报告,将分析结论清晰地展示出来。
- 核心库与作用
- NumPy: 高性能数值计算的基石,提供强大的多维数组对象。
- Pandas: 数据分析的“瑞士军刀”,擅长处理表格型数据,进行灵活的数据操作和分析。
- Matplotlib: 可视化库的“老大哥”,功能全面,可以绘制几乎任何类型的静态图。
- Seaborn: 基于Matplotlib,专攻统计可视化,默认样式更美观,绘制统计图形更便捷。
- Scikit-learn: 机器学习领域的标杆库,提供了简洁统一的API,覆盖了从数据预处理到模型评估的完整机器学习流程。
- 这五个库构成了一个黄金组合,它们紧密协作,覆盖了从数据清洗、探索到建模、展示的完整链路,是入门学习和实战应用的主力军。
四 五分钟上手示例
理论说再多,不如亲手跑一遍。下面这个极简示例,目标就是让你在五分钟内,体验一次完整的数据导入、统计和可视化小闭环。
- 目标: 读取一份示例数据,进行基本统计并绘制一张关系图。
- 步骤
- 启动你之前创建的环境:
source ~/venvs/data310/bin/activate(如果用的是conda,则是conda activate datasci)。 - 如果是首次在该环境操作,安装依赖:
pip install pandas matplotlib seaborn scikit-learn jupyter。 - 启动Jupyter Notebook:
jupyter notebook。浏览器会自动打开交互式编程界面。 - 在Notebook的新建单元格中,输入并运行以下代码:
- 启动你之前创建的环境:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载Seaborn内置的示例数据集(小费数据)
tips = sns.load_dataset(“tips”)
# 看看数据的基本统计情况(均值、标准差、分位数等)
print(tips.describe())
# 绘制散点图:观察总账单与消费额的关系,并用颜色和形状区分性别与是否吸烟
plt.figure(figsize=(8,5))
sns.scatterplot(data=tips, x=“total_bill”, y=“tip”, hue=“sex”, style=“smoker”)
plt.title(“Total Bill vs Tip”)
plt.show()- 看,就这么几行代码,你已经完成了一个最小化的数据分析闭环。这个示例可以直接在浏览器的Jupyter Notebook中交互运行,即时看到结果,是感受数据分析魅力的绝佳起点。
五 常见问题与优化建议
上路之后,难免会遇到些小沟小坎。这里整理了几个常见场景的应对策略,能帮你走得更稳、更远。
- 依赖冲突与可复现性
- 务必坚持使用虚拟环境(venv或conda)进行项目隔离。更专业的做法是,将项目依赖导出为
requirements.txt(pip)或environment.yml(conda)文件。这样一来,无论是团队协作还是环境迁移,复现一模一样的环境就是一行命令的事。
- 务必坚持使用虚拟环境(venv或conda)进行项目隔离。更专业的做法是,将项目依赖导出为
- 性能与加速
- 处理数值计算任务时,牢记优先使用NumPy和Pandas的向量化操作,避免低效的Python循环。如果计算量巨大,可以考虑使用Numba进行即时编译加速,或者采用多进程并行。至于GPU加速,通常是在涉及深度学习等复杂机器学习任务时,才需要专门考虑CUDA/cuDNN与相应框架(如PyTorch, TensorFlow)的版本匹配问题。
- 图形界面与显示
- 如果你在无图形界面的远程服务器上工作,在Jupyter Notebook中记得使用
%matplotlib inline魔法命令来内嵌显示图表。如果是在纯脚本中,则需要设置Matplotlib使用Agg这类非交互式后端:import matplotlib; matplotlib.use('Agg')。
- 如果你在无图形界面的远程服务器上工作,在Jupyter Notebook中记得使用
- 数据源与格式
- 数据交换格式有讲究。日常优先使用CSV(通用)或Parquet(列式存储,高效)格式。要读取Excel文件,需要额外安装
openpyxl或xlrd库。若数据在数据库中,则需要安装对应的驱动,比如连接PostgreSQL用psycopg2,连接MySQL用pymysql。
- 数据交换格式有讲究。日常优先使用CSV(通用)或Parquet(列式存储,高效)格式。要读取Excel文件,需要额外安装
- 学习路径
- 对于新手,一个务实的学习路径是:先花时间夯实Pandas的数据操作基础和Matplotlib/Seaborn的可视化技巧,这是数据分析的“硬功夫”。有了这些基础,再循序渐进地学习Scikit-learn中的标准机器学习工作流——如何划分数据集、训练验证模型、以及使用各种评估指标来衡量效果。一步一个脚印,知识体系才能牢固。
本文转载于:https://www.yisu.com/ask/28734561.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
下一篇:cmatrix怎样优化性能
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- CentOS 环境下 Golang 打包技巧有哪些
- 在 CentOS 环境下提升 Golang 打包效率的实用技巧 在 CentOS 服务器上使用 Golang 进行项目打包,是许多后端开发者的日常。虽然流程看似标准,但掌握一些进阶技巧,能显著提升构建效率、优化程序性能,并让部署过程更加丝滑。下面就来聊聊几个经过实践检验的核心方法。 1. 拥抱 Go
- 10分钟前 0
-
 正版软件
正版软件
- centos jenkins如何与其他系统对接
- CentOS 上 Jenkins 与外部系统的对接实践 一 对接总览与准备 在构建自动化流水线时,Jenkins 很少是一座孤岛。它需要与一系列外部系统“握手”,才能串联起从代码到部署的完整链条。常见的对接对象,无外乎这么几类:代码仓库(如 GitLab/GitHub)、容器编排平台(如 Kuber
- 10分钟前 0
-
 正版软件
正版软件
- tkmybatisupdate各种类型使用及说明
- 1.updateByExample 先来看第一种情况:你需要根据一个给定的条件(Example)来更新数据,并且要求更新对象里的所有属性,包括主键ID。这意味着,你传给方法的实体对象,每一个字段都必须有值。 怎么用呢?看下面的代码示例就明白了: package com.bsx.test; publi
- 11分钟前 0
-
 正版软件
正版软件
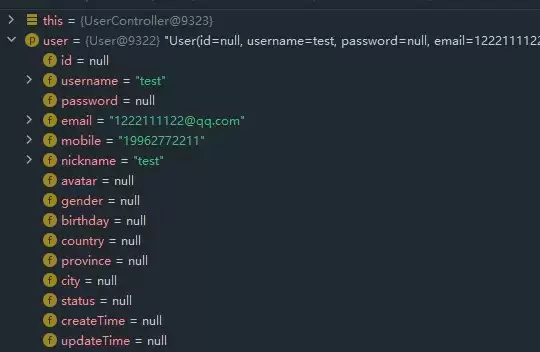
- Mybatis-plus在新增或修改时如何自动插入或修改某个字段值
- 一 效果 咱们先来看一个实际场景:当你向User表新增一条数据时,如果手动传入的createTime字段是null,会发生什么? 别担心,这正是MyBatis-Plus的“魔法”生效之处。使用它自带的sa ve方法执行新增后,你再查看数据库,会发现createTime字段已经被自动填上了当前时间戳。
- 11分钟前 0
-
 正版软件
正版软件
- CentOS Sniffer如何与其他工具协同工作
- CentOS 嗅探器与其他工具的协同实践 一 工具定位与总体思路 在 CentOS 环境下,我们常说的“Sniffer”其实是一个工具家族,核心任务就是抓包与分析,成员包括 tcpdump、Wireshark/TShark,以及像 MySQL Sniffer 这样的专精选手。实际工作中,很少有人会单
- 12分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 228天前
-
4
- 探析Spring Boot框架的优点和特色
- 544天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 482天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 458天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1090天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 918天前
-
 9
9
- 解决Python安装失败的问题
- 468天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00