Meta发布Muse Spark:华人天团废墟重建,最恨Llama的果然是小扎自己
 发布于2026-04-24 阅读(0)
发布于2026-04-24 阅读(0)
扫一扫,手机访问
Meta AI“推倒重来”:华人天团交出首份答卷Muse Spark,但更大的战争才刚刚开始

作者 | 猫猫头
邮箱 | cathy@pingwest.com
在Llama 4的“崩盘”成为旧闻之后,Meta的AI路线图经历了一场彻底的自我革命。创始人扎克伯格亲手拆解了过去的团队与技术架构,转而押注一条全新的道路。九个月后,在一片关注与质疑声中,由他重金组建、以华人科学家为核心的研发天团,交出了第一个作品——Muse Spark。这不仅仅是一个新模型,更是一次宣告:Meta打算用一套从零搭建的全新AI技术栈,重新回到牌桌。
4月8日,Meta Superintelligence Labs (MSL) 正式发布了其成立以来的首个模型Muse Spark。九个月前,随着Alexandr Wang以首席AI官的身份加入Meta,一场技术重构悄然启动。团队推翻了Llama时代的技术遗产,从基础设施、模型架构到数据管道,全部从头开始。如今,Muse Spark作为这套新栈的首个产出,已直接上线驱动Meta AI。
可以说,在Llama 4因基准测试风波陷入被动后,Muse Spark标志着Meta AI一次不留退路的全面重启。
Muse Spark是什么?
简单来说,这是一个处处与前任Llama“反着来”的模型。它被刻意设计得小巧、轻量,并追求极致的响应速度。本质上,它是一个原生的多模态推理闭源模型。
先看它的几个核心能力:
真正的原生多模态: 不同于将视觉编码器“缝合”到文本模型上的常见做法。Muse Spark从预训练阶段开始,就让文本、图像、语音在同一个高维特征空间里共同学习。这意味着它处理图片时,无需先将其转化为文字描述,而是能直接从像素层面提取和理解信息。
Visual Chain of Thought(视觉思维链): 传统的思维链推理局限于文本领域。Muse Spark将这一机制引入了视觉空间,使其能够在图像内部进行“思考”,自主构建视觉元素之间的空间与逻辑关系。
Contemplating Mode(沉思模式): 对标Gemini的Deep Think和GPT Pro的极限推理模式。但它的独特之处在于非单线串行推理,而是在后台并行启动多个子智能体,各自处理任务的不同维度,最后由主控系统融合结果。在该模式下,其在Humanity‘s Last Exam测试中达到58%,在FrontierScience Research测试中达到38%。
工具调用与多智能体编排: 这些能力均为原生支持,而非后期附加。
目前,Muse Spark已在meta.ai和Meta AI应用上线,沉思模式正逐步灰度开放,同时其私有API也已面向少量合作伙伴提供预览。

技术亮点:效率革命与可预测的扩展
模型发布当日,MSL团队成员几乎集体在社交平台X上发声,透露了几个关键信息。
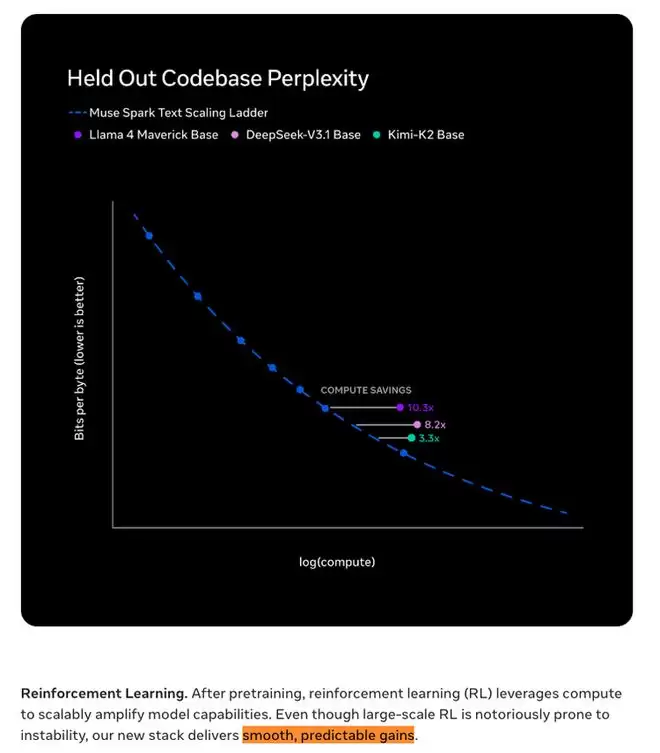
Meta官方博客披露了一项重要数据:在预训练阶段,新技术栈达到同等能力水平所需的算力,比上一代的Llama 4 Ma verick减少了超过一个数量级。这不是百分之几十的提升,而是十倍以上的效率飞跃。博客原文强调其“显著优于用于对比的领先基座模型”。
Alexandr Wang在推文中提到了一句至关重要的话:“我们在预训练、强化学习和测试时推理三个阶段,都看到了可预测的扩展规律。” 这或许比任何单一的基准测试分数都更有意义。它意味着这套技术栈并非偶然调优成功的“幸运儿”,而是一个具备平滑、可预测扩展曲线的系统性工程。
首席科学家赵晟佳的描述更为形象:模型的训练路径是一次“端到端的教育”——包括“学校教育”(预训练)、“家庭作业”(强化学习)和“在职培训”(产品部署后的持续学习)。他意味深长地补充道:“我们才刚刚开始。”
强化学习部分有一个有趣的技术细节。研究员毕树超提到了训练中最具挑战的部分:大规模强化学习的不稳定性,以及与“奖励机制作弊”作斗争。但最新的博客显示,他们最终将强化学习训练推进到了“平滑、可预测增益”的状态,相关性能指标呈对数线性增长,并且在未见过的评测集上也能平滑泛化。
更有意思的是训练中间出现的“相变”现象:团队引入了“思考时间惩罚”机制。模型起初通过延长“思考”时间来提升表现,随后在惩罚压力下学会了“思想压缩”——用更少的计算资源解决相同问题,之后再次延伸推理以达到更高性能。研究员Ananya Kumar称这个过程“相当巧妙”。
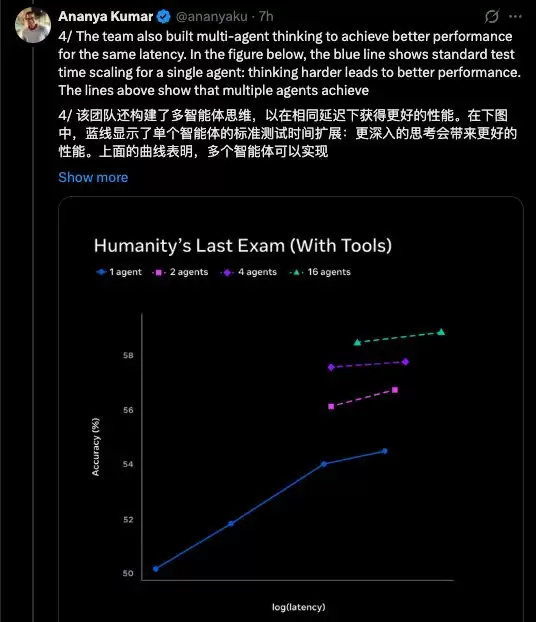
Ananya展示的另一组图表揭示了多智能体推理的关键洞察:多个智能体并行推理,在相同时间延迟下,能达到比单智能体更高的性能。换句话说,沉思模式不仅仅是“让模型想得更久”,更是“让多个模型同时思考不同方面”。
作为多模态底座的总架构师,余家辉的话值得玩味:“这是一段充实的旅程,不仅仅在于构建模型,更在于构建其背后的团队与文化。” 他们在九个月里,同步完成了两件大事。

Jason Wei的回忆则充满了画面感:“第一周,我们在食堂进行了一次漫长的晚餐,畅想研究方向,然后回到桌前写了一个基本的推理脚本。如今,我们拥有了一套相当完整的技术栈,并且发布了第一个模型。”

基准测试:领先与争议并存
那么,Muse Spark在实际测试中表现如何?
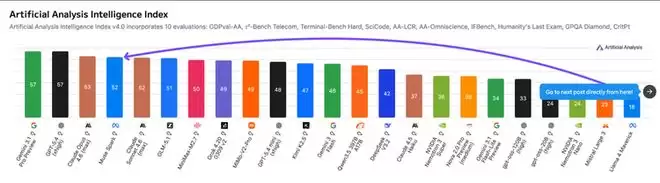
在极高难度的医学问答基准HealthBench Hard上,Muse Spark得分42.8,优于GPT-5.4的40.1,更是远超Gemini 3.1 Pro的20.6和Claude Opus 4.6的14.8,领先优势接近两到三倍。
在科研论文图表深度理解测试CharXiv Reasoning上,它以86.4分位居行业榜首。
在真实软件工程任务测试SWE-bench Pro上,达到55.0%,超过了Claude Opus 4.6的51.9%。
然而,在综合性的Artificial Analysis智能指数上,Muse Spark得分为52分,仍落后于GPT-5.4和Gemini 3.1 Pro的57分。
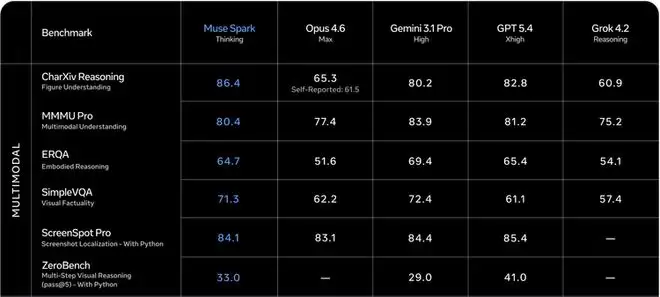
这些数据表明,Muse Spark在需要深度视觉理解的医疗多模态和科研图表领域,已建立起断档式的领先优势,在代码工程上也跻身第一梯队。但其综合能力与纯文本高级推理方面,与顶尖模型尚有差距。
这样的表现也引来了批评。Ndea的联合创始人François Chollet直言Muse Spark“看起来是个令人失望的模型”,他认为模型过度优化了公开基准测试,牺牲了实际可用性。对此,Alexandr Wang的回应显得克制:他承认模型在ARC AGI 2等部分评测上表现不佳,并强调所有数据均已主动公开。
Chollet的质疑并非空xue来风。Llama 4时代,Meta就曾因基准测试争议损伤过信誉。此次Muse Spark在特定领域断档领先,究竟是源于对测试的定向优化,还是其原生多模态架构带来的真实能力突破?这个问题需要更多独立的第三方测试来验证。

更大的图景:一次彻底的技术栈重构
无论如何,Muse Spark的重要性远不止于今天的基准测试分数。
从模型的设计理念,到研发团队重点介绍的技术细节,一切都指向对Llama时代的全面反叛。在扎克伯格看来,Llama 4的溃败必须被彻底翻篇。因此,不仅是开源路线或模型架构需要调整,而是整个训练基础设施都必须推倒重来。此次核心成员们的分享,焦点都集中在底层技术栈的重构上。Muse Spark的发布,也让外界更加明了扎克伯格重金挖来Alexandr Wang及其团队的深层意图。
可以说,最急于告别Llama的,正是Meta自己。它必须在废墟之上,完成重建。
此次发布也是Meta招兵买马后,那支备受瞩目的华人科学家团队交出的首份答卷。余家辉、赵晟佳、任泓宇、毕树超、林纪——这些以前OpenAI核心成员身份被Meta以重金招揽的科学家,在纸面上构成了一个明星阵容。他们的首要任务,就是用一款模型帮助Meta重新在AI竞赛中站稳脚跟。这是扎克伯格的当务之急。
九个月前,扎克伯格交给他们的是一张白纸。如今他们交出的,不仅仅是一个模型,更是一套涵盖了预训练、强化学习、测试时推理的完整技术栈。而最关键的是,这套技术栈的扩展曲线被证明是平滑且可预测的。
这只是一个开始。更大的模型,已经在路上了。

点个“爱心”,再走吧
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Meta正式推出其全新AI模型“Muse Spark”,“含芯量”满满的科创芯片设计ETF天弘(589070)近20日净流入超7000万元
- 4月9日A股芯片板块观察:市场低开,资金暗流涌动 4月9日,A股市场三大指数集体低开,其中,聚焦于硬核科技的上证科创板芯片设计主题指数,开市跌幅达到1.02%。 将视线投向热门交易品种,截至发稿,备受关注的科创芯片设计ETF天弘(589070)交投活跃,成交额已突破1000万元,换手率维持在1.6%
- 5分钟前 0
-
 正版软件
正版软件
- OPPO Pad Mini配置曝光:或搭载骁龙8 Gen 5处理器
- OPPO Pad Mini配置曝光:小尺寸平板或将迎来性能与设计新标杆 近日,科技圈传来新消息。根据外媒曝光的信息,OPPO似乎正在准备一款小型平板电脑——OPPO Pad Mini。从流出的配置来看,这款产品不仅在尺寸上做了减法,更在屏幕、性能和便携性上做足了加法,目标直指追求高效与移动体验的用户
- 6分钟前 0
-
 正版软件
正版软件
- 拳头游戏宣布《无畏契约》冠军巡回赛 VCT 重大革新,2027年起改为锦标赛模式
- 拳头游戏宣布《无畏契约》冠军巡回赛 VCT 重大革新,2027年起改为锦标赛模式 电竞圈的重磅消息来了。拳头游戏于4月8日晚正式宣布,其旗舰电竞项目《无畏契约》冠军巡回赛(VCT)将在2027年迎来一次彻底的系统性革新。这次变革的核心,是从现有模式转向一个以锦标赛为驱动的全新竞技生态,旨在开放全球通
- 6分钟前 0
-
 正版软件
正版软件
- 微软(MSFT.US)AI掌门人:语音控制尚处“雏形”,自然对话理解仍需海量训练
- AI语音交互的“最后一公里”:微软高管揭示技术突破的关键所在 最近,微软人工智能业务负责人穆斯塔法·苏莱曼的一席话,点出了当前AI体验中一个普遍却关键的瓶颈。尽管用户越来越习惯用语音指挥AI助手,但在他看来,要让机器真正听懂我们随口说的话,背后的技术还得再上一层楼。 语音转录:通往自然对话的“第一道
- 7分钟前 0
-
 正版软件
正版软件
- 戴森推出手持无叶风扇HushJet Mini Cool,售价99美元
- 戴森“无叶”再进化:一款能揣进口袋的强劲凉风 距离戴森首次推出碘伏性的无叶风扇,已经过去了近十七年。这款产品曾与它的吸尘器前辈一样,成为消费电子领域的标志。如今,这项经典设计迎来了一个意想不到的形态:一款可以握在掌心的手持随身风扇——HushJet Mini Cool。 熟悉戴森的朋友都知道,其无叶
- 7分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 517天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 524天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 535天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 827天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 543天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2321天前
相关推荐
- Meta正式推出其全新AI模型“Muse Spark”,“含芯量”满满的科创芯片设计ETF天弘(589070)近20日净流入超7000万元
- OPPO Pad Mini配置曝光:或搭载骁龙8 Gen 5处理器
- 拳头游戏宣布《无畏契约》冠军巡回赛 VCT 重大革新,2027年起改为锦标赛模式
- 微软(MSFT.US)AI掌门人:语音控制尚处“雏形”,自然对话理解仍需海量训练
- 戴森推出手持无叶风扇HushJet Mini Cool,售价99美元
- 存储芯片涨价后,5000元的iPhone都要扩容了:大容量买不起
- Meta将裁员10%:加码AI战略,全球约8000人受影响
- 欧洲最大苹果博物馆开馆:展出数千藏品,还原乔布斯创业车库
- 被喷「电子垃圾」的MacBook Neo,线下门店居然卖疯了
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00