不做遥操作、不采真机数据,这家公司的机器人靠学习“人类第一视角数据”干活
 发布于2026-04-25 阅读(0)
发布于2026-04-25 阅读(0)
扫一扫,手机访问

当谈到具身智能的现状,一个尖锐的比喻被提了出来:“当前技术更像是陷在动作模仿的泥潭里,环境或任务稍有风吹草动,好不容易学会的技能就大概率失灵。真正的出路在哪里?或许在于先让机器人像人一样,理解我们所在的物理世界,再去执行具体任务——这,才是为机器人装上大脑的关键。”深度机智的创始人陈凯对智客ZhiKer这样阐述。
一、从无人问津到硅谷共识:一条技术路线的逆袭
时间拉回到2024年底,当陈凯首次提出“AnthroLearning”(人类学习)这条技术路线时,场面一度有些冷清。这位在人工智能领域深耕十五年,曾任微软亚洲研究院首席研究员、主导过年调用量千亿次级产品的科学家,收到的反馈多是沉默,乃至质疑。
那时,具身智能领域的主流玩法是遥操作:让人戴上设备控制机器人,记录下每一个动作轨迹,再让机器人反复模仿;或者利用海量的互联网视频和仿真数据来训练。这套逻辑很直观,目标就是让机器人把动作“背”下来。
然而,这条主流路线的天花板也很明显。陈凯一针见血地指出:“这些方法的本质,无异于‘手把手教猴子干活’,效率太低。真正的突破口,在于通过人类的第一视角数据,向机器大脑注入物理常识,完成从‘猴子’到‘人’的进化。”
转折,来得比大多数人预料得更快。
2025年5月,硅谷的具身智能企业开始将目光转向人类第一视角数据。无独有偶,正是在这个月,陈凯与他同为中科大少年班学院毕业的张翼博联手,创立了深度机智。
到了去年年底,深度机智联合北京中关村学院,用1000小时人类第一视角数据训练出的PhysBrain基座模型,交出了一份令人惊艳的答卷。在一个“把胡萝卜放进盘子”的任务中,机器人的夹子碰到胡萝卜后,没有僵硬地重复抓取,而是像人一样尝试推动胡萝卜让其滚入盘中。几次尝试发现盘子边缘过高后,它主动转变策略,改为夹取,并在一次失败后调整角度和力度,最终成功。这种根据现场情况灵活变通、自主纠错的能力,并非预先编程,更像是模型自己“涌现”出来的智能。
那么,为什么业界认为2026年是关键节点?为什么这条路线在中国充满机会?技术收敛后,产业又将走向何方?智客ZhiKer与深度机智创始人陈凯、联合创始人兼CEO张翼博进行了一次深入对话。
对话:技术路线的收敛与共识
智客ZhiKer:为什么说“AnthroLearning”路线在快速收敛?
陈凯:这个速度确实超预期。2024年底我们提出这个概念时,它还很有争议,当时大家的焦点还在遥操作、真机数据和仿真上。真正的转折点出现在2025年5月,特斯拉宣布其Optimus机器人将逐步放弃动作捕捉数据,转向从人类第一视角数据学习。紧接着6月,原Google DeepMind科学家Andy Zeng创办的Generalist AI展示的Demo中,机器人往盒子里放积木块时用了“扔”的动作,这明显也是从人类数据中习得的。
这种对物理交互的灵活运用,恰恰是传统轨迹拟合方法难以实现的。到了去年底,Skild AI、Physical Intelligence、英伟达等硅谷公司都在向“人类第一视角数据”看齐,共识基本达成了。
张翼博:国内各大厂在春节前后也纷纷组建新团队跟进。今年3月之后,这条技术路线开始受到追捧。我们预测,2026年将成为“AnthroLearning”的元年。
物理常识:智能的“暗物质”
陈凯:无论各家走的是VLM、VLA还是世界模型路线,最终都会卡在一个核心瓶颈上:基座模型缺乏物理常识。VLM模型可能不理解空间关系,数不清桌上有几个杯子;世界模型生成的视频也许能以假乱真,但运动的物理真实性往往不足。
而人类第一视角数据采集自真实物理世界,天然蕴含着空间理解和交互过程。说得更直白些,现在的轨迹拟合就像在教猴子干活,但我们得先让它理解人类世界的常识,进化成“人”,再去学技能,这样效率才高。
张翼博:关键突破在于物理常识的注入,这不是简单的轨迹标注,而是对任务深层次的理解。比如拧开矿泉水瓶盖,先做什么后做什么,这些我们习以为常的下意识行为,恰恰是智能的“暗物质”,标注门槛极高。
二、技术实现:如何把人类经验“翻译”给机器人
陈凯:从时间线看,我们和英伟达的技术管线搭建几乎是同步的。英伟达在2026年2-3月公开方案,我们在2025年3月启动预研、6月搭出数据管线。区别在于,英伟达侧重于手部轨迹预训练,而我们直接增强VLM模型本身。最终大家都收敛到用人类数据增强物理直觉,从进度和投入看,我们略微领先。
具体来说,我们围绕数据转译、架构设计、训练目标三个环节,搭建了一套全栈矩阵,目的是把视频中隐性的经验提取成结构化的监督信号——任务如何拆解、关键状态是什么、手该怎么动、物体间有何约束、时空关系怎样。

这套“Egocentric2Embodiment”翻译管道的核心,是将人类第一视角视频转码成机器人能学的“结构化教材”。它通过多层次拆解,确保时序逻辑连贯,且每个判断都有画面证据支撑,最终输出带有标准答案的监督数据,让机器人知其然,也知其所以然。
利用这套方法,我们构建了E2E-3M数据集,并训练出具身大脑PhysBrain。在未出现于训练集的SimplerEnv四个操作任务上,PhysBrain(8B版本)以67.4%的平均成功率,超越了行业标杆Physical Intelligence的Pi0.5模型,领先优势达到10%。
“智能涌现”与“左右脑”架构
陈凯:涌现能力体现在模型对物理交互的直觉式理解,而非机械执行。在胡萝卜任务中,“推”这个动作从未出现在训练数据里,模型也没看过失败示范,这种灵活应变更像是一种内生的物理直觉。
为了在注入物理常识的同时,不损失模型的通用理解能力,我们在架构上做了关键设计——“左右脑”同构架构TwinBrainVLA。我们引入一个被冻结的VLM模块作为“左脑”,保持其开放世界理解能力;同时让可训练的“右脑”网络专门处理机器人本体感知和动作策略。
关键在于两者间的信息交互机制(AsyMoT),右脑可以动态查询左脑的语义知识,而左脑参数不会被污染。这就实现了知识迁移而不遗忘:右脑学会控制时,左脑依然保有“杯子易碎需轻放”的常识。遇到新场景,左右脑协同工作,既懂原理,也能操作。
张翼博:过去一年,我们观测到多次类似的智能涌现,并与英伟达交叉验证了数据规模的有效性。用1000小时数据实现这样的性能,本身就是对新范式的关键验证。
三、数据与身体:落地之路的双重基石
数据采集的工程化挑战
陈凯:数据采集、处理和模型预研同步推进,全流程不到3个月。核心难点有三:制作专用采集设备、确保数据确权与隐私合规、打造能提取物理常识的数据处理管线。管线建成后,训练工作就顺畅多了。
张翼博:我们是国内首批完成10万小时量级多模态第一人称视角数据采集的公司。通过自研的全套方案,综合成本远低于市场其他数据类型,数据有效性也大幅提升。
何旭国(深度机智硬件负责人):很多人以为在头上装个摄像头就能采集数据,但实际工程化问题很多。我们重新定义了什么样的设备能进入真实生产生活场景。传统智能眼镜在续航、负重上矛盾突出,因此我们最终将存储、算力等模块外置为定制腰包方案,最大限度减少头部负担。

我们还部署了轻量级手部检测模型,只在画面中间出现手时才开始拍摄,最大限度保证了数据的有效性。
为大脑设计适配的身体
陈凯:使用人类数据学习的最佳载体,应该是高度拟人的机器人。
何旭国:我们为这个“大脑”设计的身体,全身采用万元级谐波力控电机关节模组,共72个自由度。这款机器人在不通电时也能自主站立,这对未来进入实际场景非常重要,意味着低能耗和高安全性。

张翼博:谐波全身力控是技术路线,拟人体是结构路线。拟人要求每个自由度与人对齐,我们的优势在于“谐波+同构”兼得,而谐波关节模组的小型化正是行业难点,我们已取得关键突破。
四、未来展望:中国的机遇与产业的变革
陈凯:最终目标是实现具身AGI,或者说具备物理智能的大模型,用模型能力为机器人提供服务,提供更理解物理世界的“Token”。
张翼博:短期我们要“沿途下蛋”。先开源4B小模型,证明路线的可行性;同步推进数据采集设备的商业化;下一步是将更大模型产品化,供行业调用。同时,我们也在探索养老、教育等具体场景。
中国何以可能实现超车?
张翼博:中国的优势首先在数据。美国采集标注27万小时第一视角数据花费巨大,而中国拥有更丰富的场景和更低的采集成本。行业达到千万小时级别的人类第一视角数据,在今年就有望实现。
其次是算力。国产卡已完全可以承接需求,我们有充足的国产算力资源作为支撑。技术路线既已收敛,接下来就是投入信心和全行业共同努力的时候了。实现弯道超车,可能性非常大。
陈凯:另一个关键是,标注工作必须与模型架构、训练方法紧耦合。对手部轨迹建模也许只需几块钱算力,但对空间常识、任务理解的深度标注,可能需要几百块,投入大,回报也巨大。
中美发展各有侧重,中国在机器人本体领域有显著优势,美国在“具身大脑”上起步更早。但我们对赶超有信心:一是场景储备丰富,制造业基础雄厚;二是硬件协同潜力大,可以更高效率设计适配大脑的身体;三是有制度创新和国产芯片突破等有利因素。
张翼博:能与物理世界交互的人工智能,其估值空间是巨大的。这既是国家层面的需求,也将深刻影响制造业和服务业,未来或许能让“劳动”成为一种选择,而非必需。如果具身智能成为AGI的原生能力,整个AI产业链都将被重构。在这个赛道上,相信中美将是齐头并进的格局。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 微软发布《对Windows质量的承诺》:全面优化Windows 11性能、可靠性与用户体验
- 我们对Windows质量的承诺 最近,微软Windows + Devices部门的负责人Pa van Da vuluri,联合Windows Insider项目团队,发布了一份相当扎实的公告。这份题为《我们对Windows质量的承诺》的声明,可以说为Windows 11的未来发展定下了清晰的调子。核
- 5分钟前 0
-
 正版软件
正版软件
- 告别卡顿!华硕5070显卡助力AI创作速度飞起
- 当下的AI图像与视频生成:从指令跟随到工作流掌控 如今,视觉生成AI领域正经历一场明显的转变。图像模型已经能稳定地产出逼真写实的画面,而视频模型则在生成长度与连贯性上不断突破。更关键的是,它们都越来越“听话”,能够精准地遵循创作指令。对于创作者而言,重点已不仅仅是感叹技术的奇妙,而是如何将其高效地融
- 5分钟前 0
-
 正版软件
正版软件
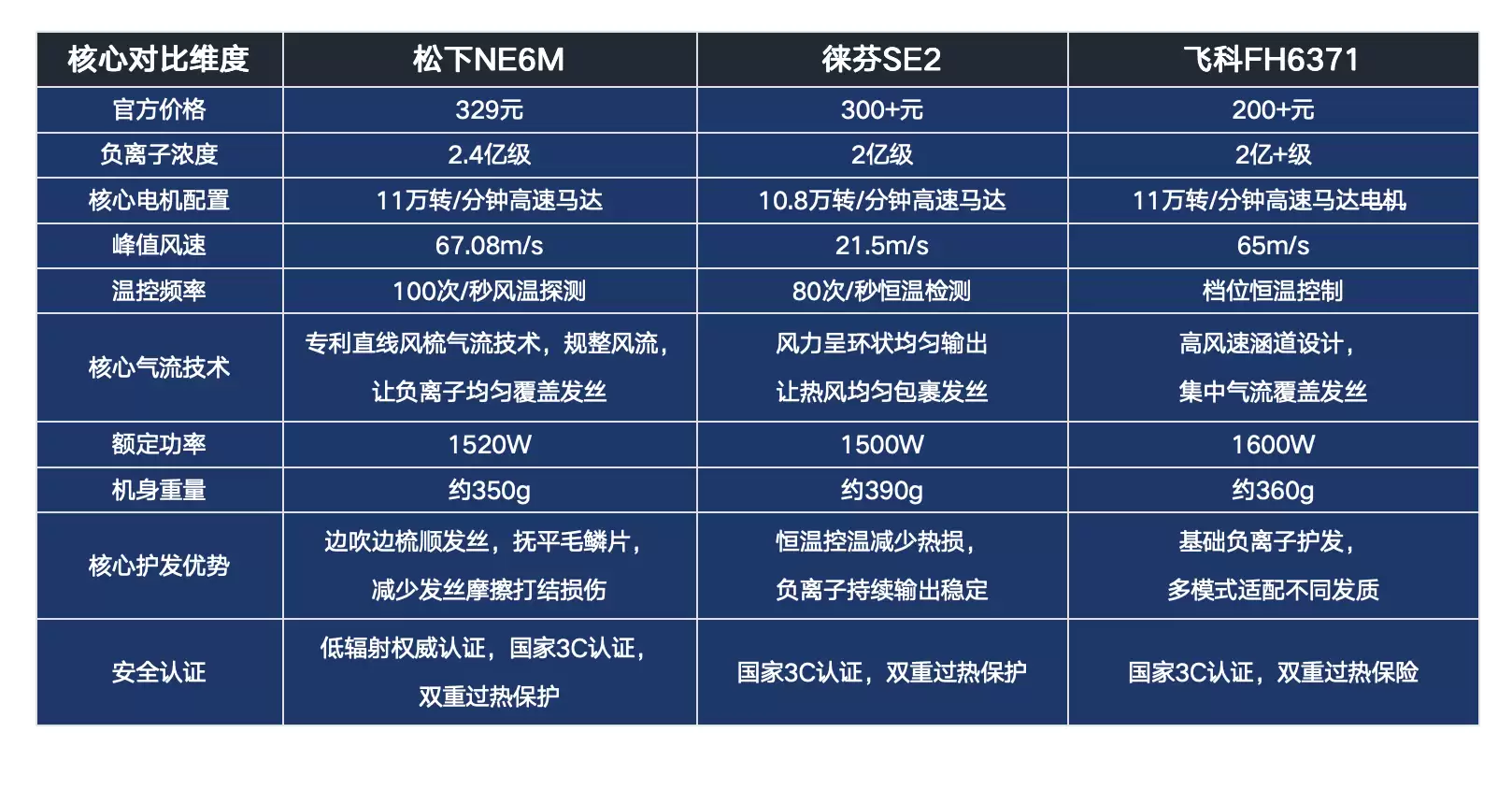
- 2026负离子吹风机推荐:3款高口碑护发款实测
- 核心观点总结 说到底,一台真正靠谱的负离子吹风机,它的护发效果并非来自“负离子”这个概念的简单叠加。关键在于三个硬指标:真实有效的负离子浓度、与之匹配的气流与温控技术,以及必不可少的安全认证。只有三者协同,才能发挥实效。合格的高浓度负离子产品,确实能有效中和发丝静电、抚平毛鳞片,显著改善毛躁打结的问
- 6分钟前 0
-
 正版软件
正版软件
- 荣耀X80i开启预售:1999元起 4月10日正式开售
- 荣耀X80i近日上市并开启预售,售价1999元起,国补后到手价1699.15元起,将于4月10日正式开售。 轻薄机身与旗舰工艺 先看外观。这次荣耀X80i提供了流沙粉、青柠绿、月影白、曜石黑四款配色,选择空间不小。手感方面,堪称一大亮点——整机厚度薄至7.34毫米,重量控制在185克,拿在手里感觉相
- 13分钟前 0
-
 正版软件
正版软件
- 听声锁敌,战场集结!ROG电竞耳机带你畅玩《三角洲行动》
- 《三角洲行动》玩家们注意了,赛季挑战“蝶变行动”火热开启中 想在战场上发挥稳定,一套性能出色的游戏装备至关重要,尤其是那双能“听风辨位”的耳朵。趁着赛季火热,咱们来盘一盘三款专为FPS游戏打造的ROG电竞耳机,看看哪款更能成为你的制胜利器。 ROG臻世游戏耳机:为发烧级音质而生 如果你对声音细节有着
- 13分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 518天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 525天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 536天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 828天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 544天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2322天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00