英伟达已适配 DeepSeek-V4 AI 模型
 发布于2026-04-25 阅读(0)
发布于2026-04-25 阅读(0)
扫一扫,手机访问
英伟达宣布Blackwell平台适配DeepSeek-V4系列模型
就在今天,英伟达发布了一则重要消息:其最新的NVIDIA Blackwell平台,已经正式完成了对DeepSeek-V4-Pro和DeepSeek-V4-Flash两款模型的适配。这意味着,开发者现在可以通过NVIDIA NIM微服务直接下载部署,或者利用SGLang与vLLM框架进行更灵活的定制化推理。
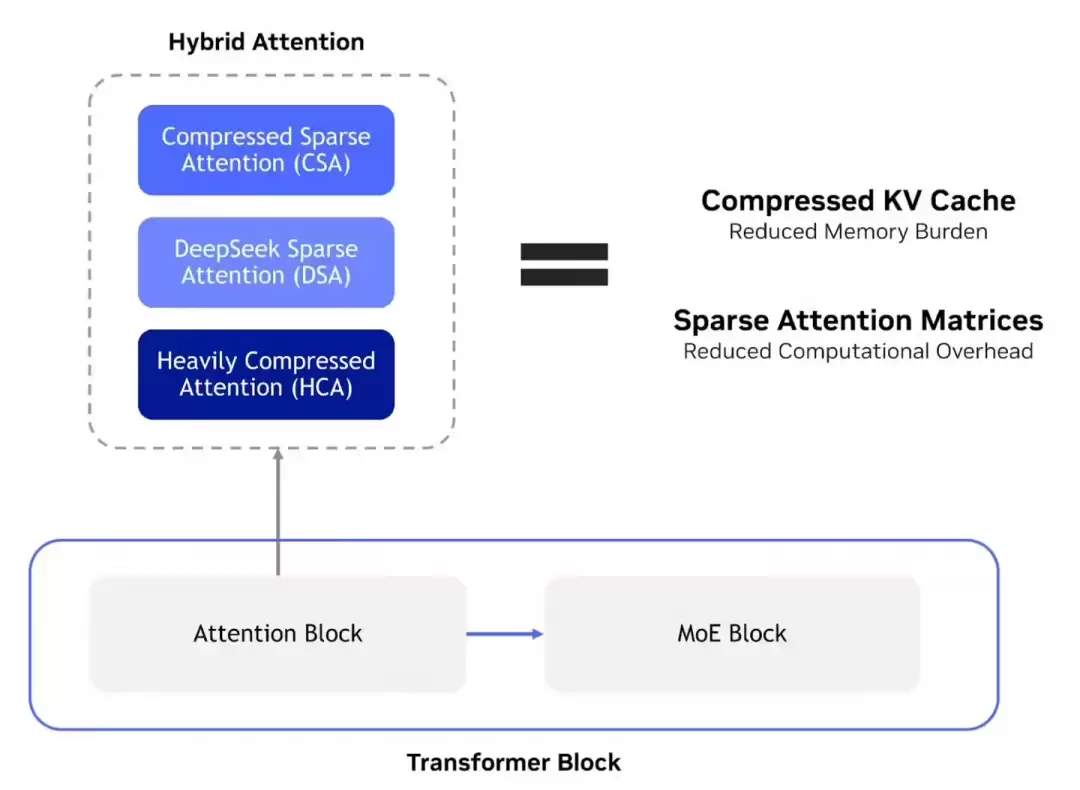
那么,这两款模型究竟有何不同?从官方公布的信息来看,定位非常清晰。DeepSeek-V4-Pro拥有高达1.6T的总参数量,激活参数为49B,显然是瞄准了需要复杂逻辑和深度思考的高级推理任务。而它的“兄弟”DeepSeek-V4-Flash则走了另一条路,总参数量为284B,激活参数13B,主打的就是一个“快”字,专为那些对速度和效率有极致要求的场景设计。
当然,它们也有显著的共同优势。两款模型都支持长达100万Token的上下文窗口,并且最高能输出38.4万Token。这个能力意味着什么?简单来说,无论是处理超长的技术文档、进行深度的代码分析,还是完成复杂的多轮对话,它们都能轻松应对。值得一提的是,这两款模型都采用了MIT开源协议,对开发者社区相当友好。
光有理论参数还不够,实际表现才是硬道理。根据实测数据,DeepSeek-V4-Pro在NVIDIA顶级的GB200 NVL72系统上,开箱即用的性能就超过了每秒每用户150个Token。对于希望快速上手的开发者,借助vLLM框架提供的“Day 0”配方,可以在Blackwell B300上实现快速部署。这还不是终点,随着Dynamo、NVFP4以及CUDA内核的持续深度优化,模型的推理性能还有望进一步提升。
最后,来看看部署生态。英伟达为开发者提供了灵活的选择路径。既可以通过封装好的NVIDIA NIM微服务,像调用API一样简便地下载和部署;也可以选择更底层的SGLang或vLLM框架,进行深度定制。其中,SGLang提供了低延迟、均衡以及最大吞吐量三种预设“配方”,以适应不同场景的优先级。而vLLM框架则更加强大,它支持将推理任务扩展到100个以上的GPU节点,并且内置了工具调用和推测解码等高级能力,为构建大规模、高性能的AI服务提供了坚实的技术底座。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- smart首款豪华掀背轿车 精灵#6 EHD 内饰设计曝光
- smart 公布首款豪华掀背轿车内饰手稿,透露三大设计“彩蛋” smart品牌今天正式揭晓了其首款豪华掀背轿车的内饰设计手稿。官方宣称,这款新车的内饰设计“源自梅赛德斯-奔驰的豪华底色”。仔细品味这份手稿,你会发现其中暗藏了三个颇为有趣的“彩蛋”:升降式扬声器、飞机涡轮造型元素以及经典的千鸟格纹理。
- 5分钟前 0
-
 正版软件
正版软件
- 新一代小米 SU7 配备 ALD 镀膜技术有效抑制逆光与远光干扰耐磨易清洗
- 小米汽车答网友问(第229集):车外麦克风、解锁逻辑等五大功能详解 今天,小米汽车官方持续更新答网友问系列,来到了第229集。这期内容聚焦于新一代SU7的一些实用细节,覆盖了从车外语音的硬件布局到日常洗车的注意事项,再到车辆解锁的个性化设置,解答了不少用户心中的疑问。 下面,就带你一起梳理一下本期问
- 6分钟前 0
-
 正版软件
正版软件
- 徕芬CEO叶洪新预热AirFold手持风扇下月发布
- 徕芬官宣5月新品发布会:7款新品齐发,折叠风扇率先亮相 徕芬科技又有大动作了。就在今天,其CEO叶洪新通过微博正式宣布,品牌将于5月举办一场重磅新品发布会。这次发布会的规模可不一般,计划一口气推出7款新产品,被官方称为自2025年推出直线往复式剃须刀以来,产品矩阵最大规模的一次集中更新。 在预热信息
- 6分钟前 0
-
 正版软件
正版软件
- 矽芯微成都基地首片晶圆成功加工下线,成为国内投产速度最快晶圆中道加工fab厂
- 四川矽芯微成都基地实现首片8寸晶圆下线,投产速度创国内纪录 4月22日,来自成都高新区的消息显示,四川矽芯微科技有限公司其成都基地项目近期取得关键进展:首片8寸晶圆成功加工下线,并顺利完成小批量试生产。值得注意的是,该项目从启动到投产,创造了国内晶圆中道加工fab厂的最快速度,预计将为成都高新区集成
- 21分钟前 0
-
 正版软件
正版软件
- 超大规模恐龙蛋化石群穿上“纳米防护服”
- 青龙山恐龙蛋化石穿上“纳米防护服”,超大规模遗址保护工程竣工 最近从青龙山恐龙蛋化石群国家级自然保护区传来一个好消息:历时近五年的科研攻关与现场施工,位于湖北十堰的恐龙蛋化石群防风化保护工程,终于在4月21日全面竣工。这意味着,总面积超过6200平方米的珍贵化石遗址,如今都穿上了一层看不见的“纳米防
- 21分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 518天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 525天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 536天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 828天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 544天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2322天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00