面试必问的Java运行时架构JVM详解
 发布于2026-04-27 阅读(0)
发布于2026-04-27 阅读(0)
扫一扫,手机访问
一、先画个整体框架
很多初学者接触JVM,容易陷入细节而忽略整体。在深入每个组件之前,建立一个清晰的全局认知至关重要。
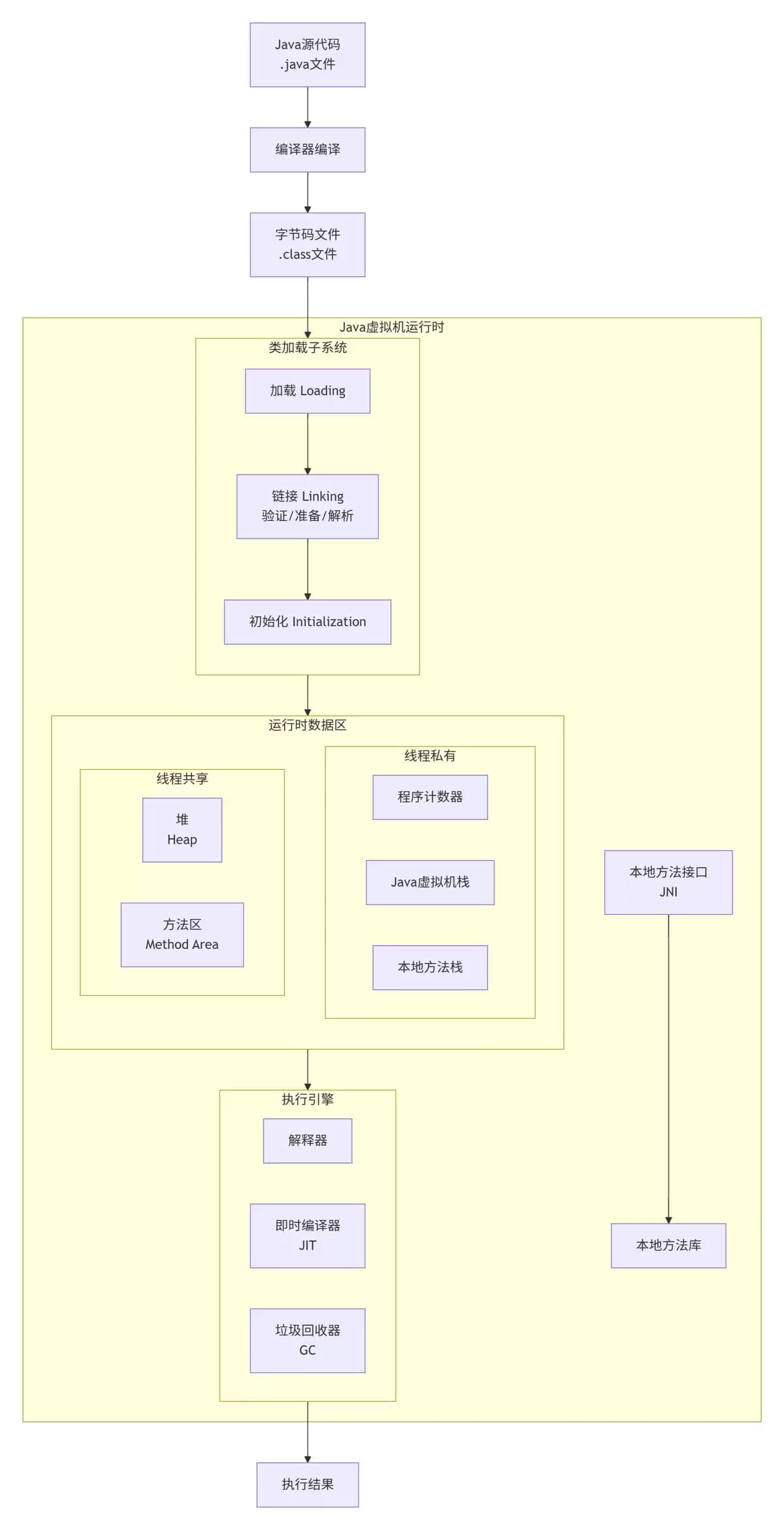
这张图就是JVM的骨架,务必印在脑子里。整个运行时环境可以概括为三个核心模块:
- 类加载器(ClassLoader)—— 负责将字节码文件搬运到内存中。
- 运行时数据区(Runtime Data Area)—— JVM的内存世界,所有数据都在此分配和存储。
- 执行引擎(Execution Engine)—— 真正的执行者,将字节码指令翻译并驱动CPU运行。
这三者协同工作,构成了Ja va“一次编写,到处运行”的基石。
二、类加载器 ClassLoader
它干什么的?
简单来说,ClassLoader就是JVM的“搬运工”和“翻译官”。它的核心任务是把硬盘上冷冰冰的.class字节码文件,加载到内存中,并转换成JVM内部能够识别和操作的数据结构——ja va.lang.Class对象。
这个过程可以抽象为一条清晰的流水线:
.ja va 源文件
↓ 编译
.class 字节码文件
↓ ClassLoader
内存中的 Class 对象(ja va.lang.Class)
三个阶段
类加载并非一步到位,而是分为三个严谨的阶段:
1. 加载(Loading)
- 根据类的全限定名(如
ja va.lang.String)定位到对应的.class文件。 - 读取该文件的二进制字节流,并将其转换为方法区中特定的运行时数据结构。
- 在Ja va堆中生成一个代表该类的
Class对象,作为程序访问方法区中这些数据的入口。
2. 链接(Linking)
- 验证:进行严格的格式、语义和安全检查,确保字节码是合法且无害的,这是守护JVM安全的第一道关卡。
- 准备:为类的静态变量在方法区分配内存,并设置默认初始值(如int是0,引用是null)。注意,这里还不是赋值。
- 解析:将常量池内的符号引用(如一个方法名)替换为直接引用(具体的内存地址或偏移量)。
3. 初始化(Initialization)
- 执行类的
() - 这是类加载过程中,Ja va程序代码真正开始执行的起点。
双亲委派模型
这是类加载机制的精髓,也是面试官最喜欢追问的环节之一。
三层类加载器:
| 加载器 | 负责加载 | 例子 |
|---|---|---|
| Bootstrap ClassLoader | JDK 核心类 | String, Object |
| Extension ClassLoader | JDK 扩展类 | ja vax.* |
| Application ClassLoader | 用户 classpath | 自己写的类 |
双亲委派流程:当一个类加载器收到加载请求时,它不会自己先去尝试加载,而是把这个请求逐级向上委托给父加载器去完成。只有父加载器反馈无法完成时,子加载器才会尝试自己加载。
加载请求
↓
ApplicationClassLoader
↓ 问爸
ExtensionClassLoader
↓ 问爸
BootstrapClassLoader
↓ 找不到
ExtensionClassLoader 尝试加载
↓ 找不到
ApplicationClassLoader 尝试加载
↓ 成功
返回 Class
为什么这样设计?核心目的是为了保证Ja va核心类库的类型安全。试想一下,如果没有这个机制,用户在自己的类路径下编写了一个ja va.lang.String类,那么系统将存在多个不同版本的String,基础类的行为将变得混乱且不可控。双亲委派模型确保了像Object、String这样的核心类,永远由最顶层的Bootstrap加载器加载,从而形成了带有优先级的层级关系,避免了类的重复加载和核心API被篡改。
三、运行时数据区 Runtime Data Area
这是JVM内存管理的核心舞台,也是性能调优和故障排查的重灾区。理解每个区域的特性和边界,是进阶的必经之路。
1. 程序计数器(Program Counter Register)
特点:
- 一块非常小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。
- 它存储的是下一条需要执行的字节码指令的地址。
- 线程私有:每个线程都有自己独立的程序计数器,各线程之间互不影响。
为什么不会发生OOM(内存溢出)?因为它的生命周期与线程相同,且仅存储一个简单的指令地址,大小在编译期就已确定,不会动态扩展,因此是唯一一块在Ja va虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
2. 虚拟机栈(VM Stack)
特点:
- 线程私有,生命周期与线程同步。
- 描述的是Ja va方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧。
- 栈帧中存储着局部变量表、操作数栈、动态链接、方法返回地址等信息。
一个栈帧包含:
- 局部变量表:存放方法参数和方法内部定义的局部变量。
- 操作数栈:方法执行过程中进行算术运算或调用其他方法时传递参数的临时工作区。
- 动态链接:指向运行时常量池中该栈帧所属方法的引用,以支持方法调用过程中的动态绑定。
- 返回地址:方法正常退出或异常退出时,PC计数器应该恢复的值。
会 OOM 吗?当然会。虚拟机栈可以动态扩展,但如果扩展时无法申请到足够内存,就会抛出OutOfMemoryError。更常见的是,如果线程请求的栈深度大于虚拟机所允许的深度(例如一个无限递归的方法),则会抛出StackOverflowError。下面就是一个典型的栈溢出例子:
// 死递归,栈溢出
public int sum(int n) {
return sum(n) + 1; // 没有终止条件
}
3. 本地方法栈(Native Method Stack)
其作用与虚拟机栈非常相似,区别在于虚拟机栈为执行Ja va方法服务,而本地方法栈则为执行本地(Native)方法服务。所谓本地方法,通常是指用C/C++等语言实现的方法,通过JNI(Ja va Native Interface)调用。在HotSpot虚拟机中,本地方法栈和虚拟机栈是合二为一的。
4. 堆(Heap)
这是JVM中最大的一块内存区域,也是垃圾收集器管理的主要区域。
- 几乎所有的对象实例以及数组都在这里分配内存。
- 线程共享:所有线程都可以访问堆中的对象,因此这里也是线程安全问题的高发区。
- 由于对象生命周期长短不一,现代垃圾收集器基本都采用分代收集算法,所以堆内存常被细分为新生代和老年代。
为什么要分代?这源于一个被称为“弱分代假说”的经验法则:绝大多数对象的生命周期都非常短暂。分代之后,可以将不同“年龄”的对象放在不同的区域,从而针对新生代(朝生夕死的对象)和老年代(长期存活的对象)采用最合适的垃圾回收算法,极大地提升了GC效率。
5. 方法区(Method Area)
方法区是各个线程共享的内存区域,它存储了已被虚拟机加载的:
- 类型信息:如类的全限定名、访问修饰符、父类、实现的接口等元数据。
- 类的结构信息:运行时常量池、字段描述、方法描述等。
- 运行时常量池:存放编译期生成的各种字面量和符号引用。
- JIT编译器编译后的代码缓存。
JDK 1.8 的重大变化:在JDK 1.7及之前,方法区的实现被称为“永久代”(Permanent Generation),它位于堆内存中。从JDK 1.8开始,永久代被彻底移除,取而代之的是元空间(Metaspace),它移到了本地内存(Native Memory)中。
| 版本 | 方法区实现 | 位置 |
|---|---|---|
| JDK 1.7 | PermGen | 堆内 |
| JDK 1.8 | Metaspace | 本地内存 |
为什么要改?根本原因是为了解决永久代的内存管理问题。永久代有固定的大小上限,容易因加载过多类或常量池过大而引发ja va.lang.OutOfMemoryError: PermGen space。元空间使用本地内存,其容量理论上只受限于操作系统可用内存,并且由元空间虚拟机进行更高效的内存管理,减少了Full GC的发生。
四、执行引擎 Execution Engine
它干什么的?
执行引擎是JVM的“CPU”,它负责将字节码文件解释或编译成对应平台上的机器指令并执行。字节码毕竟是一种中间代码,无法被物理CPU直接识别。
解释器 vs JIT 编译器
JVM通常采用解释与编译并存的混合模式来平衡启动速度和运行效率。
| 组件 | 特点 | 适用场景 |
|---|---|---|
| 解释器 | 逐行读取、解释、执行字节码,响应速度快。 | 程序启动阶段,或只执行一次的“冷”代码。 |
| JIT 编译器 | 将热点代码整个编译优化成本地机器码并缓存,后续直接执行。 | 被频繁执行的“热点”代码,如循环体、高频调用方法。 |
JIT 的热点探测:JVM如何知道哪些是“热点代码”呢?它内置了两类计数器:
- 方法调用计数器:统计方法被调用的次数。
- 回边计数器:统计一个方法中循环体代码执行的次数。
当某个方法的调用次数或循环次数超过设定的阈值时,JIT编译器就会将其判定为热点代码,触发即时编译。
垃圾回收器
GC是JVM知识体系中最复杂、也最考验功力的部分。不同的垃圾回收器实现了不同的垃圾收集算法。
常见 GC 算法:
| 算法 | 原理 | 缺点 |
|---|---|---|
| 标记-清除 | 首先标记所有存活对象,然后统一回收所有未被标记的对象。 | 会产生大量不连续的内存碎片。 |
| 复制 | 将内存分为两块,每次只使用一块。GC时,将存活对象复制到另一块,然后清空已使用的整块空间。 | 内存利用率只有50%。 |
| 标记-整理 | 标记过程与“标记-清除”一样,但后续不是直接清理,而是让所有存活对象向一端移动,然后直接清理掉边界以外的内存。 | 移动对象成本高,且需要暂停用户线程。 |
常见垃圾回收器:基于上述算法,衍生出了多种适用于不同场景的垃圾回收器,如追求吞吐量的Parallel Sca venge/Parallel Old,追求低停顿的CMS,以及面向全堆、可预测停顿时间的G1,还有JDK 11后推出的、以超低延迟为目标的ZGC和Shenandoah。
五、本地接口 JNI
Ja va并非无所不能,在某些需要直接操作底层硬件、调用操作系统特定功能或复用遗留C/C++库的场景下,就需要借助JNI(Ja va Native Interface)这座桥梁。
JNI允许Ja va代码调用本地方法(通常由C/C++编写),反之亦然。
典型场景:
- 调用操作系统提供的、Ja va API未封装的底层功能。
- 对性能有极致要求的计算密集型任务(如图形处理、密码学运算)。
- 访问特定硬件设备。
public native String hello(); // native 方法声明,其实现由C/C++完成
六、记忆口诀
最后,用一张结构图来串联所有核心知识点,方便记忆和复述:
JVM 三大部分: ┌─────────────────────────────────┐ │ 类加载器 ──── 加载字节码 │ │ 运行时数据区 ── 分配内存 │ │ 执行引擎 ──── 执行字节码 │ └─────────────────────────────────┘ 运行时数据区五块: 计数器(无GC) 虚拟机栈(存方法调用,会OOM) 本地方法栈(native方法) 堆(对象,会GC) 方法区(类信息) 双亲委派: Bootstrap → Extension → Application
写在最后
JVM知识体系庞大,面试中考察的不仅是记忆,更是理解和表达。一个常见的误区是死记硬背概念,一旦被深入追问就容易露怯。
真正有效的学习方法是“可视化”和“脉络化”。尝试自己动手画几遍JVM的整体结构图,把每个区域的作用、关联、常见问题标注在旁边。面试时,如果能一边在白板上勾勒出清晰的JVM架构,一边流畅地讲解各个模块的协作关系,这种直观的表达方式往往能极大提升面试官的好感度。
技术表达本身就是一种能力。能将复杂原理清晰呈现,远比机械地背诵概念更有价值。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:如何用日志辅助Node.js调试
下一篇:使用C#自制一个截屏工具
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 如何利用CentOS Golang日志进行调试
- 在 CentOS 上用 Golang 日志高效调试 一 日志输出与级别配置 工欲善其事,必先利其器。一套清晰的日志输出配置,是高效调试的基石。通常,我们可以从两个方向入手。 使用标准库 log:这是最直接的方式。通过设置输出目标、日志前缀和格式标志,可以快速让日志落地。比如,下面的示例就将日志定向写
- 1小时前 11:31 0
-
 正版软件
正版软件
- CentOS Golang日志清理技巧有哪些
- CentOS 上清理与管理 Golang 日志的实用技巧 日志管理这事儿,说大不大,说小不小。处理好了,它是排查问题的利器;放任不管,它分分钟就能吃光你的磁盘空间。尤其在 CentOS 这类服务器环境里运行 Go 应用,一套清晰、自动化的日志管理策略,绝对是生产环境稳定的基石。下面,我们就来聊聊几个
- 1小时前 11:31 0
-
 正版软件
正版软件
- Golang日志在CentOS上的备份方法
- 在CentOS上备份Golang应用程序的日志,可以采用以下几种方法: 对于在CentOS上运行的Golang应用,日志管理是个绕不开的话题。放任不管,日志文件会无限膨胀,不仅占用磁盘空间,查找历史记录也如同大海捞针。那么,如何高效、自动地备份这些日志呢?下面这几种主流方案,总有一款适合你的场景。
- 1小时前 11:30 0
-
 正版软件
正版软件
- CentOS中C++代码如何优化与重构
- 在CentOS系统中优化和重构C++代码 想让你的C++程序在CentOS上跑得更快、更稳、更易于维护?这事儿说难也不难,关键在于遵循一套系统化的方法。下面这份指南,就为你梳理了从诊断到优化的完整路径。 1. 代码分析与诊断 优化之前,先得知道问题在哪。盲目动手,往往事倍功半。 使用静态分析工具:像
- 1小时前 11:30 0
-
 正版软件
正版软件
- CentOS环境下C++依赖如何解决
- CentOS 环境下 C++ 依赖处理指南 在CentOS上折腾C++项目,依赖问题往往是第一道坎。系统库版本老旧、第三方库缺失、编译运行报错……这些问题处理起来有没有一套清晰的章法?答案是肯定的。接下来,我们就系统性地梳理一下,从基础环境到疑难杂症,如何高效地解决CentOS下的C++依赖问题。
- 1小时前 11:30 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 231天前
-
4
- 探析Spring Boot框架的优点和特色
- 547天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 485天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 461天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1093天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 921天前
-
 9
9
- 解决Python安装失败的问题
- 471天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00