近百万字素材秒级处理 国产开源大模型再升级
 发布于2026-04-27 阅读(0)
发布于2026-04-27 阅读(0)
扫一扫,手机访问
DeepSeek-V4系列大模型发布
最近,国产AI领域传来重磅消息:自主研发的大模型DeepSeek正式推出了全新的V4系列。这次升级可不简单,在百万级超长上下文处理、全球实时知识储备、复杂逻辑推理这些核心技术上,都实现了跨越式的进步。那么,这款国产开源模型的实际表现到底如何?我们不妨通过一组实测来一探究竟。
要知道,超长上下文处理能力,可是衡量一个大模型能否胜任工业级应用的关键标尺。为了测试这项能力,测试者准备了一个总量接近百万字(97万字)的素材包,里面塞满了长篇文学作品、各领域新闻稿件等五花八门的文本。然后,一口气全部“喂”给了模型。
第一轮测试,要求模型从指定的新闻稿件中,精准提炼出第四部分的核心内容。结果,仅仅用了大约7秒钟,模型就输出了五个要点的结构化总结,既快又准。
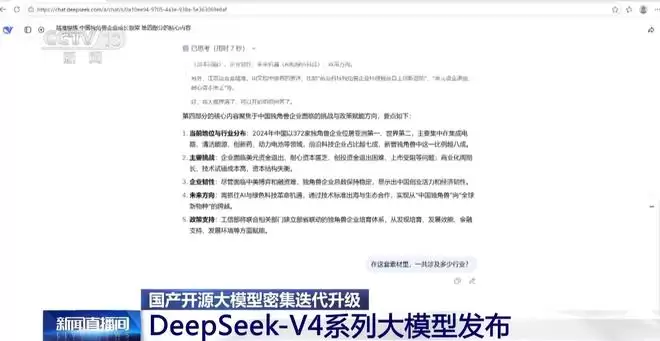
接下来,挑战升级。测试者抛出了一个需要“通读”全部近百万字内容才能回答的问题:“这套素材里,一共涉及多少个行业?”模型经过“思考”,给出了答案:大约45个细分行业。
真正的考验还在后面。测试者聚焦全球基建与民生实事,提出了一个复合型问题:“2025年下半年,全球有哪些国家开通了中国援建的新铁路线路?这些线路给当地老百姓带来的最直观变化是什么?”这个问题兼具时间限定、地域跨度、事实核查和深度解读,难度不小。
然而,模型的表现令人印象深刻。它不仅准确列出了非洲、拉美等多个国家的铁路项目,还详细阐述了每条线路带来的改变。例如,在提到坦赞铁路激活项目时,它指出完工后货物运输时间预计将缩短近三分之二,年运力将提升至240万吨。更生动的是,它还引用了当地一位73岁退休铁路工人的感慨:“铁路老了,速度太慢,许多货主都改走更贵的公路。升级后青年有工作、农民能卖货、企业敢投资,它不仅是一条铁路,更是未来。”

从堪称“超级记忆力”的百万字内容处理,到覆盖全球的“海量知识库”,再到应对复杂场景的深度逻辑推理,通过这一系列实测,国产大模型技术快速迭代的脉搏,清晰可感。
多款国产开源大模型密集迭代升级
值得注意的是,DeepSeek-V4还有一个重要标签——“开源”。其实,近期国内多家科技企业都完成了开源大模型的迭代升级,形成了一波密集的发布潮。
梳理一下不难发现,本轮国产开源模型的迭代,覆盖了技术降本、工业级应用、专项能力突破、端侧适配等多个核心方向,堪称一次多维度的集体跃进。具体来看:
腾讯开源的混元模型,重点在于大幅降低了AI推理的部署成本,这让中小企业无需高昂投入,就能快速搭建属于自己的AI应用;
月之暗面发布的Kimi模型,擅长把复杂任务拆解开来,让多个AI小助手协同工作,从而能应对更为复杂的工业场景;
而稀宇科技的Minimax,则在代码生成与程序理解这个专业领域,实现了显著的性能跃升。

对于这股开源浪潮,中国电子信息产业发展研究院未来产业研究中心副研究员钟新龙指出,以DeepSeek-V4为代表的开源路线,有效降低了企业应用成本,扩大了开发者生态,增强了产业链的自主选择空间。可以说,开源大模型正在加速人工智能从工具应用,走向产业基础设施。

随着核心技术的持续突破,国产开源大模型已经成长为全球人工智能开源生态中不可或缺的核心供给方和重要驱动力量。全球最大的AI开源社区Hugging Face发布的2026年春季报告显示,过去一年,该平台上高达41%的大模型下载量,都来自中国研发的模型。这无疑标志着,中国已成为全球开源大模型供给最活跃、增长最快的地区之一。
国产大模型加速融入实体经济
随着核心技术的突破和开源生态的完善,国产开源大模型的发展,正告别早期单一的模型技术比拼阶段,全面进入一个全行业协同发展的生态跃升期。人工智能技术,正在加速融入千行百业,为实体经济的转型升级,注入强劲的智能动能。
那么,开源大模型到底意味着什么?通俗地讲,就是人工智能研发企业将AI最核心的“技术底座”免费向全社会开放。这就好比顶级大厨公开了自己的独家菜谱和全套标准化烹饪技法。无论是大型企业、中小微市场主体,还是普通开发者,都能免费使用这套技术底座,根据自己的生产、研发需求进行二次改良和定制开发,而无需从零开始搭建AI系统。这极大地降低了人工智能技术的应用门槛和研发成本。
钟新龙副研究员进一步解释道,过去,先进模型主要掌握在少数闭源平台手中,企业更多是“购买能力”。而开源模型成熟后,企业可以围绕自身的数据、业务流程和行业知识进行二次开发,形成更贴近自身场景的人工智能应用。
这种开源开放的发展模式,有效打破了AI技术的行业应用壁垒。它推动国产大模型从“能聊天、会问答”的通用交互能力,向“能执行、可落地、提效率”的真正生产力工具全面转型,深度融入制造、能源、交通、金融等实体经济重点领域。

政策层面也在强力助推这一进程。今年1月,工业和信息化部等八部门联合印发的《“人工智能+制造”专项行动实施意见》中,明确将建设高水平人工智能开源社区、部署实施一批标杆开源项目纳入核心任务。文件提出,到2027年,要推动3至5个通用大模型在制造业深度应用,打造100个工业领域高质量数据集,并推广500个典型应用场景。

钟新龙认为,开源大模型正在把全球人工智能的竞争格局,从少数巨头的垄断,推向更广泛的产业竞争。人工智能主权已成为各国政策的重要方向,而开源发展正在扩大参与主体,推动更多语言、更多地区、更多行业进入模型生态。
数据是最有力的证明:国产开源大模型的全球累计下载量已突破100亿次。我国已成为全球人工智能专利最大拥有国,专利申请量全球占比高达60%。目前,国内AI企业数量超过6200家,预计到2025年,人工智能核心产业规模将超过1.2万亿元。一幅波澜壮阔的智能经济图景,正在我们眼前展开。
(总台央视记者 王世玉 张伟)
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Anthropic又惹祸?大写「HERMES.md」触发计费Bug,扣光用户200美元
- 编辑:Youli 最近Anthropic的日子可不太平。上周,这家公司才刚放下身段,为Claude Code变笨的问题公开道歉,并找出三个Bug来“谢罪”,还调整了使用限额以安抚用户。没想到,消停没几天,新的麻烦又找上门了。 这次的问题,说起来有点让人哭笑不得:仅仅因为用户Git提交记录里出现了“H
- 11分钟前 0
-
 正版软件
正版软件
- 鑫谷无界巡天700T机箱开售,定价329元
- 鑫谷无界巡天700T机箱开售:全景“海景房”设计,售价329元 最近,一款主打全景视野的机箱新品在京东上架了。鑫谷推出的这款无界巡天700T机箱,以其270°无柱全景透视的左右分舱设计,瞄准了当下流行的“海景房”风格,同时兼容ATX、MATX、ITX多种规格主板,首发定价为329元。 那么,这款机箱
- 12分钟前 0
-
 正版软件
正版软件
- 昆仑万维:短剧平台已上线AI漫剧及AI真人剧
- 有投资者向昆仑万维(300418.SZ)提问,请问公司在AI动漫,AI游戏,AI视频上都有哪些布局? 4月27日,公司方面给出了回应。从整体战略来看,昆仑万维正沿着AGI与AIGC的全产业链条稳步推进。具体到模型层面,其布局覆盖了视频模型、音乐音频模型、世界模型,以及作为基础的文本与多模态大模型。
- 13分钟前 0
-
 正版软件
正版软件
- 全网怒喷!骂用户是“狗”的罗技悄悄复活,网友:脸呢?
- 罗技“复活”了,但互联网的记忆还在 上个月那句“我一降价,你还不是像狗一样跑过来”,想必大家还记忆犹新。罗技因此翻车,引发玩家、媒体和老用户的口诛笔伐,场面一度相当热闹。 令人意外的是,风波才过去一个月,罗技似乎已经用上了“复活卡”。抖音直播间照常带货,微博持续更新新品,旗舰店的促销活动也搞得风生水
- 14分钟前 0
-
 正版软件
正版软件
- 英特尔被曝将推 512 核心至强(Xeon)能效核处理器
- 英特尔被曝将推 512 核心至强能效核处理器,瞄准 2027 年市场 最近,关于英特尔未来产品线的消息在硬件圈里传得沸沸扬扬。综合几位知名爆料人 @jaykihn0、@9550pro 和 @SquashBionic 的信息来看,英特尔似乎正在酝酿一个“核弹级”的产品:一款拥有多达 512 个能效核(
- 14分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 520天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 527天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 538天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 830天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 546天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2324天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00