Linux怎么查看进程消耗的VSS/RSS/PSS内存 Linux内存指标详解
 发布于2026-04-28 阅读(0)
发布于2026-04-28 阅读(0)
扫一扫,手机访问
Linux怎么查看进程消耗的VSS/RSS/PSS内存 Linux内存指标详解

ps 命令只能看到 VSZ 和 RSS,看不到 PSS/USS
说到排查内存问题,很多工程师的第一反应就是敲下 ps aux --sort -rss。这个命令确实能给出一个排序,但这里头其实有个关键限制:你看到的 VSZ 其实就是 VSS(单位是KB),而 RSS 就是驻留集大小。至于更关键的 PSS 和 USS,ps 命令本身是给不出来的。为什么呢?因为这两个值需要去解析 /proc/[pid]/smaps 这个文件,并根据共享比例进行计算或统计独占部分,内核并没有直接把它们暴露给 ps 命令的字段。
这里有个常见的误区,以为 %MEM 这个百分比能真实反映进程的内存压力。其实不然,它仅仅是 RSS / MemTotal 的结果。问题在于,RSS 会把像 libc、libpython 这样的共享库,在每个使用它的进程里都重复计算一遍。这就导致你看到的 RSS 总量,可能远远高于系统实际被占用的物理内存。
VSZ包含了所有已经通过 mmap 映射但还没真正访问(触发缺页中断)的内存区域,比如你 malloc 了一大块空间但还没往里写数据。RSS也并不完全等于“当前吃掉的物理内存”,它里面混着共享页,而且不区分这些内存是否可以被回收(比如映射的 page cache)。- 所以,如果你想定位那个真正拖垮系统的“元凶”,只看 RSS 很容易误判。举个典型的例子:20个 Ja va 进程都共用同一个 JDK 的共享库,它们的 RSS 总和可能比实际占用的物理内存高出 3 到 5 倍。
smem 是唯一能直接输出 PSS/USS 的常用命令行工具
那么,有没有更直接的工具呢?有,就是 smem。这个工具的设计目的就是干这个的。它会去读取每个进程对应的 /proc/[pid]/smaps 文件,按照内存页的粒度进行统计和聚合,自动帮你算出 PSS(共享内存均摊后的结果)和 USS(完全私有的内存)。安装之后,基本的使用命令如下:
$ sudo smem -k -c "pid user command pss uss rss"
这里有几个关键参数值得一说:
-k:让输出以 KB 为单位,看起来更直观(默认是字节,数字会很长)。-c:用来自定义显示的列,你必须显式指定pss和uss,它们才会出现在结果里。- 你还可以加上
-P "nginx"来过滤进程名,用-u按用户汇总,或者用-w查看系统级别的内存总览。
需要注意一点:smem 通常需要 root 权限才能读取所有进程的 smaps 文件。如果是非 root 用户运行,你只能看到自己权限下进程的 USS/PSS,而且部分字段可能会是空的。
手动从 /proc/[pid]/smaps 提取 PSS/USS 要小心字段歧义
当然,如果你喜欢刨根问底,也可以直接去啃 /proc/[pid]/smaps 这个原始文件。不过,这个文件内容可不少,每个进程都有几十行统计信息,真正对我们有用的其实就几行:
- 找到以
Pss:开头的行,后面的数值就是该虚拟内存区域(VMA)对进程总 PSS 的贡献值(单位KB),把整个文件里所有的Pss:值加起来,就是这个进程的 PSS。 - USS 在这个文件里没有直接的汇总字段。理论上,你需要把所有
MMUPageSize:为 4kB 且是私有(Private)的页大小加起来。更简单一点的理解是:USS ≈ 所有区域的Size:减去共享的部分。但实际操作起来挺麻烦的,所以通常的建议是:直接用smem。 - 另外,千万别把
Referenced:和Rss:搞混了。Referenced表示最近被访问过的物理页,而Rss表示当前被映射的所有物理页(包括那些还没被访问过的)。
手动计算时一个典型的错误是:用 grep "Pss:" 抓取行,然后用 awk 求和。这可能会漏掉一些特殊的 VMA(比如 vvar、vdso),因为它们可能没有 Pss: 这一行——而 smem 在内部已经做好了这些边缘情况的遍历和回退处理。
USS 才是 kill 进程后能立刻释放的内存
理解这几个指标的现实意义是什么?最关键的一点在于:当系统内存不足(OOM)触发 killer 机制时,内核会优先选择 USS 大、但 PSS 小的进程来干掉。原因很直接:USS 大,意味着这个进程独占了大量的物理内存,杀掉它,这些内存立刻就能被释放出来,收益最高。反过来,如果一个进程 RSS 很高但 USS 很小(比如一堆通过 fork 产生的 Python worker,共享同一个解释器),那么杀掉其中一个,对释放物理内存几乎没什么帮助。
怎么验证呢?可以试试这个方法:
- 先找到一个疑似内存泄漏的进程,记下它的 PID。
- 执行
cat /proc/[pid]/smaps | awk '/^USS:/ {sum+=$2} END {print sum}'来估算 USS(注意:较新的内核版本才有直接的USS:字段;老内核还得靠smem或手动计算)。 - 同时,用
cat /proc/[pid]/statm | awk '{print $1 * 4}'快速估算一下它的 RSS(单位KB)。如果算出来的 USS 只有 RSS 的 10%–20%,那基本可以断定,这个进程严重依赖共享内存,它很可能不是导致内存紧张的首要原因。
真正棘手的情况,是 USS 在缓慢上涨,但 PSS 却变化不明显。这通常指向堆内存泄漏或者没有正确释放的 mmap 区域。遇到这种情况,就需要祭出更深入的工具了,比如 pmap -x [pid] 或者 gdb --pid [pid] 来进一步分析内存布局了。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- win10重装系统后没声音怎么办
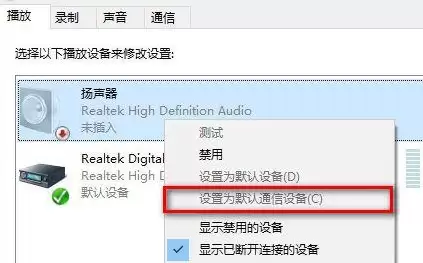
- 如何解决win10重装系统后没有声音的问题? 不少朋友选择重装Win10系统,本意是修复原有的一些故障,结果装完却发现:电脑没声音了。这确实让人头疼。别急,这个问题其实很常见,通常与系统默认设置或驱动配置有关。下面,我们就来一步步排查和解决。 win10重装系统后没声音的解决方法: 首先,我们可以从
- 2分钟前 0
-
 正版软件
正版软件
- Win10控制面板疑难解答功能无法使用解决教程
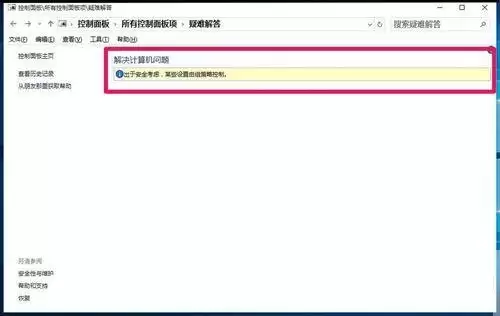
- 当Win10的“自救”功能被锁:如何重新启用故障排除 用Windows 10的朋友可能都遇到过这类烦心事儿:打印机突然罢工、声音消失不见,或者网络连接时断时续。其实,系统内置了一个相当好用的“自救”工具——控制面板里的“疑难解答”(也叫故障排除)。它能自动诊断并修复不少常见问题,堪称新手救星。但有时
- 3分钟前 0
-
 正版软件
正版软件
- Win10右下角图标不折叠怎么设置
- Win10右下角图标如何设置不折叠? 你是不是也遇到过这种情况?电脑右下角的任务栏图标,总是悄无声息地“躲”进那个小箭头里,等发现微信有新消息或者网盘上传完成时,可能已经过去好一阵子了。没错,这个默认的折叠设计,本意是保持任务栏整洁,但对于需要实时关注通知的朋友来说,确实有点不方便。今天,我们就来彻
- 35分钟前 0
-
 正版软件
正版软件
- Win10清理卸载残留软件
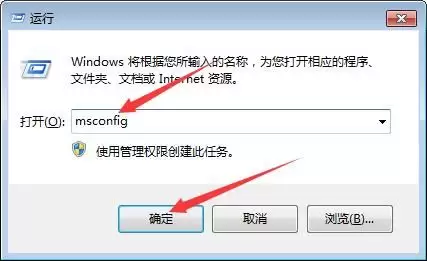
- Windows 10怎么清理卸载完的残留? 软件卸载后,那些残留文件和注册表项还在系统里“安营扎寨”,确实让人头疼。不过别担心,按照下面这套方法来操作,保证能把它们清理得干干净净。 Win10清理卸载残留软件方法 第一步,按下键盘上的快捷键组合 “Win + R”,这个操作会立刻调出“运行”对话框。
- 36分钟前 0
-
 正版软件
正版软件
- Win10系统APPCRASH事件解决方法
- 如何解决Win10系统中的APPCRASH事件? 最近在后台收到一些朋友的咨询,反映遇到了APPCRASH错误弹窗。这确实是个挺恼人的问题——程序突然崩溃,工作进度中断,还常常让人摸不着头脑。那么,这个APPCRASH究竟是怎么回事?简单来说,它是Windows系统里应用程序崩溃时触发的错误报告事件
- 37分钟前 0
最新发布
-
 1
1
- 《抖音》充值抖币官网入口
- 512天前
-
 2
2
- 大麦网官网订票入口
- 407天前
-
 3
3
- 直接点击打开漫蛙网页版
- 522天前
-
 4
4
- 天堂漫画免费入口及最新观看链接
- 194天前
-
 5
5
- 喵趣漫画官网
- 514天前
-
 6
6
- B站免费入口长期可用指南
- 255天前
-
 7
7
- 中国裁判文书网官网入口查询
- 182天前
-
 8
8
- 次元城动漫官网入口
- 474天前
-
 9
9
- 58动漫网入口及永久访问方法
- 139天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00