python08 - 操作文件和文件夹
 发布于2026-04-30 阅读(0)
发布于2026-04-30 阅读(0)
扫一扫,手机访问
Python操作文件和文件夹
在日常开发中,与文件和文件夹打交道是家常便饭。过去我们可能习惯使用os模块,但今天要介绍一个更精细、功能更强大的“升级版”工具——shutil模块。它能让你处理文件操作时更加得心应手。
好消息是,
shutil是Python的内置模块,无需额外安装,开箱即用。
一:文件处理
1:文件的复制(shutil)
复制文件是基础操作,shutil.copy()方法就是为此而生。它的核心逻辑非常清晰:将源地址的文件复制到目标地址。
from shutil import copy
# 核心方法 -> 源地址赋值到目标地址
copy(src_path, dist_path)来看一个实际场景:如何批量复制一个文件夹下所有特定类型(比如.txt)的文件?
import os
from shutil import copy
'''
源地址文件夹,复制到目标文件夹
'''
def copy_files(src_dir, dest_dir):
for file in os.listdir(src_dir):
if file.endswith('.txt'):
src_file = os.path.join(src_dir, file)
dest_file = os.path.join(dest_dir, file)
copy(src_file, dest_file)
if __name__ == '__main__':
src_dir = 'C:/Users/user/Documents/txt'
dest_dir = 'C:/Users/user/Documents/txt_copy'
copy_files(src_dir, dest_dir)? 这里有个细节值得注意:当目标路径指向一个已存在的文件时,copy操作就变成了文件内容的覆盖。如果想纯粹地复制文件内容,可以使用更直接的copyfile函数。
import os
from shutil import copyfile
'''
文件内容的复制
copyfile(src - 源文件路径, dst - 目标文件路径)
'''
def copy_file_content(src, dst):
copyfile(src, dst)
if __name__ == '__main__':
src = input("Enter the source file path: ")
dst = input("Enter the destination file path: ")
copy_file_content(src, dst)
print("File content copied successfully!")2:裁剪和变相重命名(shutil)
所谓“裁剪”,其实就是移动文件。它将文件从路径A移动到路径B。移动后,路径A下的原文件就消失了,只存在于路径B。
这个过程天然支持重命名功能。你可以将文件从A移动到B并改名,甚至可以在同一目录下移动并改名,这就巧妙地实现了文件的重命名。
from shutil import move
move(src, dist)下面的例子展示了如何批量移动.txt文件:
import os
from shutil import move
def move_files(src_dir, dest_dir):
for filename in os.listdir(src_dir):
if filename.endswith('.txt'):
src_file = os.path.join(src_dir, filename)
dest_file = os.path.join(dest_dir, filename)
move(src_file, dest_file)
if __name__ == '__main__':
src_dir = '/home/user/Documents/office/txt'
dest_dir = '/home/user/Documents/office/txt_files'
move_files(src_dir, dest_dir)3:文件的删除(os)
删除单个文件,使用os模块的remove函数通常就足够了。
from os import remove
def remove_file(file_path):
remove(file_path)
if __name__ == '__main__':
remove_file("txt01.py")4:文件的压缩和解压缩(shutil)
shutil同样简化了压缩和解压操作。make_archive用于压缩,unpack_archive用于解压。
# 如果只需要压缩可以使用这个
from shutil import make_archive
# 如果只需要解压可以使用这个
from shutil import unpack_archive# 如果只需要压缩可以使用这个
from shutil import make_archive
# 如果只需要解压可以使用这个
from shutil import unpack_archive
# src_dir中的文件压缩到dest_dir中
def zip_files(src_dir, zip_path):
# 压缩src_dir中的文件到dest_dir中,format是zip
make_archive(zip_path, 'zip', src_dir)
def unzip_files(zip_path, unpack_dir):
# 解压src_dir中的文件到dest_dir中
unpack_archive(zip_path, unpack_dir)
if __name__ == '__main__':
zip_files('E:\code_project\python\office\\txt', 'E:\code_project\python\office\\my_zip')
print('压缩完成')
unzip_files('E:\code_project\python\office\\my_zip.zip', 'E:\code_project\python\office\\txt2')
print('解压完成')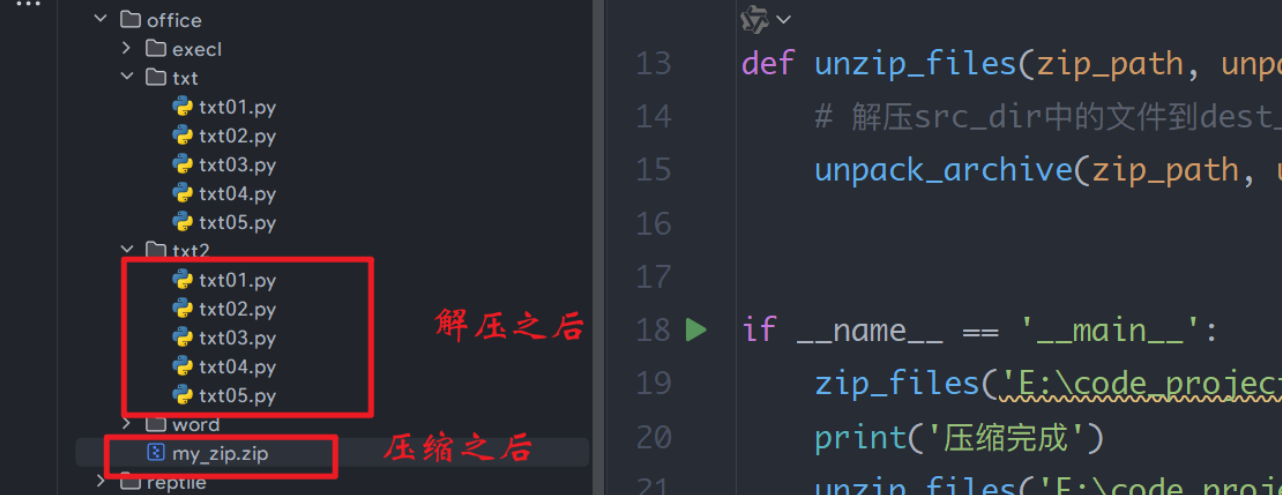
5:文件的查找(glob)
当需要快速定位文件时,glob模块是个利器。它支持通配符匹配,能帮你快速找到符合模式的文件。
import os
from glob import glob
def search_zip(base_path):
# 搜索当前目录下所有zip文件
# os.getcwd() -> 获取当前目录
# /*.zip -> 搜索当前目录下所有zip文件
search_path = base_path + "/*.zip"
search_ans = glob(search_path)
return search_ans
if __name__ == "__main__":
base_path = 'E:\code_project\python\office'
search_ans_of_office = search_zip(base_path)
# ['E:\\code_project\\python\\office\\my_zip.zip']
for ans in search_ans_of_office:
print(ans)
print("==========================================")
# 注意是直接子节点就要有对应的文件,否则找不到
# 例如将base_path范围扩大到上层目录,就没有了
base_path = 'E:\code_project\python'
search_ans_of_office = search_zip(base_path)
# []
for ans in search_ans_of_office:
print(ans)如果不使用通配符,而是明确知道文件名但不确定位置呢?这时可以结合递归进行深度查找。
final_result = []
# 通过名称递归查找文件到底在哪里
def search_by_name(base_path, name):
search_path = base_path + "/*"
search_ans = glob(search_path)
for ans in search_ans:
if os.path.isdir(ans):
search_by_name(ans, name)
else:
if name in ans:
final_result.append(ans)
if __name__ == "__main__":
# 从base_path这个大文件中找到所有包含name的全路径结果
base_path = "E:\code_project"
name = "txt05.py"
search_by_name(base_path, name)
print(final_result)更进一步,如果想查找包含特定内容的文件,就需要在判断为文件后,打开并读取内容进行匹配。
def search_all_by_content(base_path, content):
search_path = base_path + "/*"
search_ans = glob(search_path)
for ans in search_ans:
if os.path.isdir(ans):
search_all_by_content(ans, content)
else:
with open(ans, 'r', encoding="utf-8") as f:
# 读取文件内容
con = f.read()
if content in con:
final_result.append(ans)
if __name__ == "__main__":
# 从base_path这个大文件中找到所有包含name的全路径结果
base_path = "E:\code_project\python\office\\txt"
content = "import os"
search_all_by_content(base_path, content)
print(final_result)6:重复文件的清理(hashlib)
清理重复文件的原理很直观:利用hashlib计算文件的哈希值(如MD5),哈希值相同的文件即为重复文件,随后删除即可。
为了提升易用性,下面的示例结合了tkinter创建图形界面,在删除前进行二次确认。
import hashlib
def file_hash(file_path):
hash_md5 = hashlib.md5()
# 创建md5对象, 准备计算文件的md5
with open(file_path, 'rb') as f:
# 读取文件内容,每次读取4k,防止文件过大一次性加载到内存造成的性能等问题
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest() # 返回文件的md5值import hashlib
import os
import tkinter as tk
from tkinter import messagebox
def file_hash(file_path):
hash_md5 = hashlib.md5()
# 创建md5对象, 准备计算文件的md5
with open(file_path, 'rb') as f:
# 读取文件内容,每次读取4k,防止文件过大一次性加载到内存造成的性能等问题
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest() # 返回文件的md5值
def get_same_and_delete(base_path):
"""在指定目录下查找并确认删除重复文件"""
hashes = {}
duplicates = []
# 遍历指定目录及其所有子目录
# os.walk(base_path) -> 遍历指定目录及其所有子目录
# os.walk(directory) 是一个生成器函数,它会递归地遍历指定目录及其所有子目录
# 并返回一个三元组 (root, dirs, files)。具体来说,每次迭代时,os.walk 会返回以下内容:
# - root (str): 当前遍历到的目录路径。
# - dirs (list): 当前目录下的子目录列表(不包括子目录的子目录)。
# - files (list): 当前目录下的文件列表。
for dirpath, _, filenames in os.walk(base_path):
for filename in filenames:
filepath = os.path.join(dirpath, filename) # 获取文件的完整路径
try:
# 计算文件的md5值,如果之前有相同的md5值,说明该文件是重复的文件
file_hash_value = file_hash(filepath)
if file_hash_value in hashes:
# 此时找到了重复的文件,追加到重复文件列表中,一会进行删除询问
duplicates.append(filepath)
else:
# 否则将文件的md5值和文件路径添加到字典中
hashes[file_hash_value] = filepath
except Exception as e:
print(f"Error processing file {filepath}: {e}")
# 创建Tkinter根窗口
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 遍历重复文件列表,逐个确认是否删除
for dup in duplicates:
# 显示确认对话框
response = messagebox.askyesno("是否确认删除?", f"你要删除这个重复文件吗?:\n{dup}")
if response:
# 如果确定删除,则删除该文件,否则跳过删除
try:
os.remove(dup)
print(f"已经删除了重复文件: {dup}")
except Exception as e:
print(f"删除文件错误 {dup}: {e}")
else:
print(f"你跳过了该重复文件: {dup}")
root.destroy() # 销毁Tkinter根窗口
if __name__ == '__main__':
base_path = r"E:\code_project\python\office\txt"
get_same_and_delete(base_path)7:批量修改文件名称(shutil & glob)
批量重命名的核心思路很明确:首先确定需要修改的文件名特征,然后通过循环遍历,将目标字符串插入或替换到原文件名中,最后使用shutil.move完成重命名。
import shutil
import glob
import os
def update_name(base_path):
result = glob.glob(base_path)
for index, data in enumerate(result):
if os.path.isdir(data):
_path = os.path.join(data, '*') # 获取当前目录下所有文件
update_name(_path) # 递归调用
else:
# 不是文件夹,是文件了
path_list = os.path.split(data) # 单独把名字拿出来
name = path_list[-1]
# 生成一个新的名称
new_name = '%s_%s' % (index, name)
# 替换旧名称
new_data = os.path.join(path_list[0], new_name)
shutil.move(data, new_data)
if __name__ == '__main__':
base_path = r'E:\code_project\python\office\txt2'
update_name(base_path)二:文件夹处理
1:文件夹的复制(shutil)
复制整个文件夹树,使用shutil.copytree()方法可以一键搞定。
from shutil import copytree
def copy_files(src_dir, dest_dir):
copytree(src_dir, dest_dir)
if __name__ == '__main__':
src_dir = 'C:/Users/user/Documents/txt'
dest_dir = 'C:/Users/user/Documents/txt_copy'
copy_files(src_dir, dest_dir)2:文件夹的删除(shutil)
删除整个文件夹及其所有内容,shutil.rmtree()是你的不二之选。它比os.rmdir更强大,后者只能删除空目录。
import os.path
from shutil import rmtree
def remove_file(file_path):
if os.path.isfile(file_path):
os.remove(file_path)
print(f"文件 {file_path} 已被删除")
else:
try:
rmtree(file_path)
print(f"文件夹 {file_path} 已被删除")
except Exception as e:
print(f"删除文件错误 {file_path}: {e}")3:文件夹的裁剪和重命名(shutil)
文件夹的移动(裁剪)和重命名,使用的函数与文件操作完全一样——shutil.move(src, dist)。这个函数足够智能,能正确处理整个目录树的移动和更名。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Sublime配置Arduino单片机开发_Sublime编写硬件代码详细教程
- Sublime Text需通过手动配置arduino-cli实现Arduino开发:必须独立安装arduino-cli并写死绝对路径,配置FQBN与串口,补充include路径解决跳转失效,弃用已停更的Stino,推荐PlatformIO替代 先说一个核心事实:Sublime Text 本身并不能直
- 16分钟前 0
-
 正版软件
正版软件
- Composer波浪号版本约束如何用_Composer波浪号~版本教程【收藏】
- Composer波浪号版本约束如何用_Composer波浪号~版本教程【收藏】 很多人以为波浪号 ~ 是“差不多就行”的模糊匹配,那就大错特错了。它其实是一条有着精确数学边界的版本锁:你写到哪一位,它就卡死在哪一级的升级上限。用错了可不是小事,要么会锁死不该锁的版本,要么会放行不该升的变更——尤其是
- 16分钟前 0
-
 正版软件
正版软件
- 如何在WebStorm中通过SSH远程开发项目?
- 如何在WebStorm中通过SSH远程开发项目? 先澄清一个关键概念:WebStorm的SSH远程开发,可不是简单地“配个远程解释器+上传代码文件”。它的本质,是让JetBrains Gateway在远端服务器上启动一个完整的IDE后端服务,你的本地机器只负责显示界面和接收输入。所以,能连上SSH,
- 16分钟前 0
-
 正版软件
正版软件
- Sublime Text如何配置Rust开发环境_Sublime Rust开发环境配置实战
- Sublime Text 配置 Rust 环境必须同时满足三条件:rustc/cargo 在终端和 Sublime 中均可调用、文件语法手动设为 Rust、rust-analyzer 与 rustfmt 均用绝对路径显式配置;缺一则补全、格式化、跳转等功能静默失效。 想用 Sublime Text
- 17分钟前 0
-
 正版软件
正版软件
- VSCode Node.js调试_后端API接口断点调试全过程
- VSCode Node.js 调试:为什么你的 API 断点总是不触发? 关键在于请求是否真正到达断点所在路由,而非断点能否设置;常见原因包括入口文件路径错误、未启用--inspect、源码与运行文件不一致、中间件提前终止请求及端口冲突等。 调试 Node.js 后端 API 接口时,一个普遍存在的
- 18分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 234天前
-
4
- 探析Spring Boot框架的优点和特色
- 550天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 488天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 464天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1096天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 924天前
-
 9
9
- 解决Python安装失败的问题
- 474天前
相关推荐
- Sublime配置Arduino单片机开发_Sublime编写硬件代码详细教程
- Composer波浪号版本约束如何用_Composer波浪号~版本教程【收藏】
- 如何在WebStorm中通过SSH远程开发项目?
- Sublime Text如何配置Rust开发环境_Sublime Rust开发环境配置实战
- VSCode Node.js调试_后端API接口断点调试全过程
- 怎么在VSCode里管理NPM依赖-图形化查看包版本并一键升级方法
- 如何自定义Composer的安装目录结构
- PhpStorm设置不显示隐藏文件(侧边栏优化)
- 如何解决Elasticsearch搜索引擎问题?使用Composer引入ES客户端就可以!
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00