哈工大联手鹏城实验室:让AI"自我纠错",视觉幻觉减少一半的武器
 发布于2026-05-01 阅读(0)
发布于2026-05-01 阅读(0)
扫一扫,手机访问
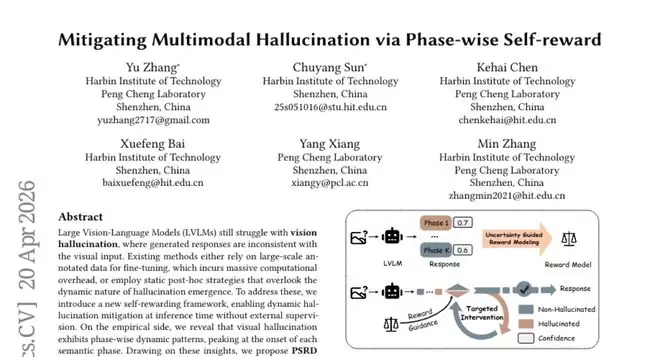
这篇论文来自哈尔滨工业大学与鹏城实验室的联合研究团队,于2026年4月发表在arXiv预印本平台,论文编号为arXiv:2604.17982v1,有兴趣深入了解的读者可通过该编号查询完整论文。
一、AI为什么会“看见”不存在的东西
你有没有遇到过这种情况?让AI助手描述一张图片,它说得头头是道,但仔细一看,内容却和图片对不上——要么把狗认成猫,要么凭空“脑补”出一辆不存在的汽车。这种现象在业内被称为“视觉幻觉”,它可不是什么无伤大雅的小毛病。试想一下,如果AI在分析医疗影像、描述自动驾驶路况或辅助证据审查时“信口开河”,后果可能相当严重。因此,如何让AI的“眼睛”更诚实,一直是学界攻坚的焦点。
最近,哈工大与鹏城实验室的团队提出了一套名为PSRD(基于阶段性自我奖励的解码方法)的新方案。他们宣称,这套方法能将主流视觉语言模型LLaVA-1.5-7B的幻觉率直接压低50%,而且无需重新训练模型或标注海量数据,只需在AI“说话”时进行实时监控与纠正。这听起来颇具吸引力,但它是如何做到的呢?要理解其精妙之处,我们得先拆解视觉幻觉产生的根源。
简单来说,大型视觉语言模型可以看作一个兼具“看图”和“说话”能力的系统。它先将图像转化为数字信号,再结合你的问题,由语言模型生成回答。问题往往出在“说话”这个环节:语言模型本质上是一个“词语接龙”高手,其训练目标是预测下一个最可能的词。当它描述图片时,注意力很容易从视觉事实本身,滑向“如何把句子编得通顺流畅”。于是,AI的语言习惯有时会压倒视觉证据,说出一些“听起来合理”却纯属虚构的内容。
现有的解决方案大致分为两派。一派是“事后修改”:让AI先生成完整回答,再用另一个程序检查并修正错误。这好比写完作文再请老师批改,效率不高,且修改过程可能引入新问题。另一派是“实时干预”:在AI生成每个词时都进行干预,通过对比信号压制幻觉倾向。这种方法计算开销巨大,且往往“一刀切”地对所有位置进行干预,在无误之处白费功夫,还可能损害语言的流畅性。
更重要的是,这两类方法都忽略了一个关键问题:幻觉究竟在哪个时刻最容易冒头? 哈工大团队决定先把这个规律摸清楚,再有的放矢地设计解决方案。
二、幻觉的“节奏”:它总在同一个时刻爆发
研究团队进行了一项基础实验。他们从COCO2014数据集中随机抽取500张图片,让LLaVA-1.5-7B为每张图片生成描述,并精细分析幻觉在整段描述中的分布规律。
他们将生成的描述切分成多个“语义阶段”,每个阶段大致对应一个完整短语或子句,然后统计每个阶段的幻觉发生率。
结果呈现出清晰的模式:从整体趋势看,幻觉率随着阶段推进缓慢上升,从第一阶段的14.6%逐渐爬升至第九、十阶段的17%左右。这说明错误确实会“传染”,前面的幻觉可能诱导后续描述继续跑偏,形成“幻觉传播”效应。
但更关键的发现藏在每个阶段内部:在每个语义阶段的开头,幻觉率最高;随着描述展开,幻觉率显著下降,到阶段末尾时已趋于稳定。
这好比一个人背诵讲稿:每次开启一个新话题段落时最容易卡壳或说错,因为他需要同时完成“开启新话题”和“回忆相关内容”两重任务。一旦进入状态,叙述就会顺畅许多,错误也随之减少。
这一发现揭示了干预的关键时机:不必在每个词上较劲,只需精准狙击每个语义阶段的开头即可。 这正是PSRD方法的核心直觉来源。
三、轻量级“裁判”的诞生:把大模型的判断力装进小瓶子
找到了幻觉的爆发规律,下一步就是打造一个能在关键时刻自动鉴别并纠正幻觉的工具。
最直接的想法是让AI自我审查:每生成一段话,就询问大模型“这段话真实吗?”,并根据回答决定是否重写。思路可行,但有个致命缺陷——大模型本身计算庞大,反复自审会让生成过程慢得无法实用。
研究团队的解决方案很巧妙:用大模型的判断能力去训练一个轻量级的“裁判模型”,在实际使用时只调用这个小裁判。 整个过程分为三步。
第一步:制造错误样本。 要训练能识别幻觉的裁判,首先需要足够的幻觉例子。团队采用两种方式诱导AI生成幻觉:一是使用被高斯噪声污染的模糊图片,干扰视觉信号以诱发“脑补”;二是设计特殊提示词,引导AI在描述真实内容后进行“合理推断”,虚构图中不存在的事物。通过这两种方法,团队构建了一个包含约40万条正确描述和4万条含幻觉描述的样本库。
第二步:让大模型标注样本。 对于每段描述,团队将其与对应图片输入大模型,询问图文是否吻合。大模型不仅给出“是/否”判断,还会输出一个置信度分数,即“不确定性信号”。置信度越高,样本越可靠;置信度越低,样本参考价值则相应降低。在后续训练中,高置信度样本会获得更高权重。
第三步:训练小裁判。 小裁判以擅长图文匹配的轻量模型CLIP为骨架。团队利用标注样本和置信度权重,通过三个协同的训练目标来打磨它:
1. 判别对齐损失: 确保小裁判能区分图文一致描述与含幻觉描述,使前者的匹配分数显著高于后者。
2. 边界强化损失: 要求正确描述与幻觉描述的匹配分数之间必须保持明显间隔,强化分辨能力。
3. 幻觉一致性损失: 使针对同一图片生成的不同幻觉描述在特征空间中聚集,提升识别稳定性,避免因表达方式不同而误判。
这三项目标的权重分别设为1.0、2.4和0.1。这个比例并非针对特定测试集微调得出,而是为了让各项损失在训练初期的数值量级大致相当,确保训练过程均衡稳定。
四、上场执裁:小裁判怎么在AI“说话”时纠错
训练完成后,小裁判便可实时介入AI的生成过程。具体而言,每当AI完成一个语义阶段的生成,小裁判立即介入评分——它将刚生成的文字与原始图片对比,给出一个“图文一致性分数”,可粗略理解为“这段话的真实程度”。
若分数高于预设阈值,说明该段落可信,AI继续生成下一阶段。若分数低于阈值,则意味着该阶段开头可能存在幻觉,系统随即启动干预。
干预采用一套名为“侦查-投影”的两阶段搜索策略:
侦查阶段: 系统并非盲目重写,而是先考察当前时刻概率最高的前K个候选词(默认K=5)。对每个候选词,系统在不额外干预的情况下生成一段描述,并由小裁判评分,选出初始分数最高的作为“种子轨迹”。如果最优种子词生成的描述已通过质量门槛,干预便以极小代价结束。
投影阶段: 若最优种子词仍未达标,则引入VCD对比解码技术进行干预。该技术通过同时生成“有视觉信息”和“无视觉信息”两个预测版本,利用其差异来压制不依赖视觉的语言惯性。干预强度由参数α控制。系统会先用小步长探测α增大时分数的变化趋势,估算斜率,并据此预测需要多大的α才能使分数越过门槛,随后进行验证。此过程仅需少量尝试即可找到合适强度,且系统会为预测值额外增加10%的余量,以应对奖励函数局部曲率带来的估算偏差。若斜率不稳定或α超出上限,系统则放弃当前候选词,换下一个种子词重试,最终以最佳结果收尾。
整个搜索过程严格限制对小裁判的调用次数,确保干预本身的计算成本可控。
五、实验战场:PSRD在五大测试中的表现
研究团队在五个公认的幻觉评测基准上对PSRD进行了全面检验,对比对象涵盖了从普通基线到最先进方法的各类模型。
在生成型幻觉测试中,最具代表性的Object HalBench基准用于检查描述中虚构物体的比例。PSRD表现极为亮眼:CHAIRs指标(描述中至少含一个幻觉物体的比例)从基线的46.3%骤降至10.1%;CHAIRi指标(所有提及物体中幻觉物体的比例)从22.6%降至4.1%。这一成绩甚至超越了众多需要大量标注数据重新训练模型的方法。此前无需重新训练的最佳方法Octopus的成绩为20.8%和6.6%,PSRD大幅改写了纪录。
在AMBER综合评测基准上,PSRD将LLaVA-1.5-7B的CHAIR分数从7.8压低至3.9,降幅恰好50%。幻觉相关的Hal分数从36.4降至20.1,认知幻觉(Cog)分数从4.2降至2.0。同时,反映模型正确识别真实物体能力的Cover分数稳定在48.2,说明PSRD没有因过度纠错而误伤真实内容。
在MMHal-Bench测试(通过GPT-4评估回答整体质量)中,PSRD的综合得分从基线的1.55提升至2.92,幻觉比例从0.76降至0.49,在所有无需重新训练的方法中位列第一。
在判别型测试(判断给定陈述与图片是否相符)中,于POPE基准的全套子测试上,PSRD将LLaVA-1.5-7B的F1分数提升至86.0,超越了此前最佳方法Octopus的83.4。在AMBER判别任务上,F1分数从基线的71.1跃升至85.0,提升达13.9个百分点。
团队还验证了PSRD的跨模型泛化能力。将为LLaVA-1.5-7B训练的小裁判模型直接用于InstructBLIP-7B和LLaVA-Next-7B,效果依然显著。例如,对InstructBLIP-7B,CHAIR分数从8.4降至4.4;对LLaVA-Next-7B,Hal分数从37.6骤降至21.1。这表明小裁判学到的判断能力捕捉了视觉幻觉的某种普遍特征,而非特定模型的“怪癖”。
六、幻觉传播:PSRD如何切断错误的“多米诺骨&牌”
研究团队设计了一项专门分析,量化PSRD在阻止幻觉“滚雪球”方面的效果。
他们定义了“阶段级幻觉积累速率”指标,用于计算相邻语义阶段间幻觉率增长的平均值。该值越高,说明错误越容易像多米诺骨&牌一样连锁传递;越低则说明模型输出更稳定。
结果显示,LLaVA-1.5-7B基线模型的积累速率为0.35%,优秀的动态干预方法M3ID为0.40%,而PSRD仅为0.07%——大约是基线的五分之一,比M3ID低了近六倍。这意味着PSRD不仅能减少当前阶段的幻觉,更能有效阻断幻觉向下一阶段的“传染”,从根源上切断了错误连锁反应。
七、效率的算盘:快与准之间怎么平衡
任何实用技术都需权衡效率。PSRD在纠错时需调用小裁判并可能进行多次尝试,这必然比直接生成答案更耗时。团队对此进行了坦诚分析。
他们发现,通过调整接受门槛τ,可以在纠错力度与速度之间灵活权衡。当τ设为30%时,PSRD比直接运行M3ID能多减少67.2%的幻觉,但推理时间约为M3ID的4倍。当τ设置得更宽松时,系统干预频率降低,速度更快,但幻觉压制效果也相应减弱。这个参数是连续可调的,用户可根据对精度与速度的具体需求进行设置。
此外,团队使用ChatGPT-4o-mini评估了生成文本的流畅度。在500段图片描述的对比中,PSRD的描述在48.5%的情况下被认为比M3ID更流畅,M3ID在37.5%的情况下更好,另有14%被认为不相上下。这表明PSRD在压制幻觉的同时,较好地保持了语言的自然流畅。
小裁判模型自身在独立的幻觉分类测试中也表现稳健。在AMBER HalDet数据集上,其准确率达80.5%,F1分数88.7%;在MHal-detect数据集上,准确率72%,F1分数81.7%,均优于对比基线。这进一步证实了小裁判所学判断能力的可靠性。
结语
归根结底,PSRD研究的核心贡献在于将复杂问题拆解为两个可分别攻克的环节:先是洞察幻觉的发生时机(每个语义阶段的开头),再以低成本工具在该时刻精准干预(用大模型训练小裁判进行实时监控与纠正)。两者结合,产生了超越许多复杂方法的效能。
这项研究推动的方向很明确:让AI在描述和理解图像时更加可信。无论是医生用AI辅助阅片,还是安防系统分析监控画面,亦或是教育工具帮助认知世界——在这些场景中,AI的每一次“诚实”回答,都增添了一份可靠与安全。
对技术细节感兴趣的读者,可通过论文编号2604.17982在arXiv平台查阅全文,其中包含了完整的算法伪代码、实验设置与消融分析。
Q&A
Q1:视觉幻觉在AI生成描述时为什么总在段落开头最严重?
A:根据PSRD的研究,AI在开始一个新的语义段落时,需要同时处理“开启新话题”和“回忆图片内容”双重任务,这使其更容易脱离视觉事实,生成听起来合理但虚构的内容。进入描述状态后,语境趋于稳定,幻觉率随之下降。这一规律正是PSRD选择精准干预时机的核心依据。
Q2:PSRD训练的小裁判模型能直接用在其他AI模型上吗?
A:可以。验证表明,用LLaVA-1.5-7B训练的小裁判模型,直接应用于InstructBLIP-7B和LLaVA-Next-7B时,同样能显著降低幻觉率。这说明小裁判学到的判断能力反映了视觉幻觉的普遍特征,具备良好的跨模型泛化能力。
Q3:PSRD和现有的幻觉纠正方法相比速度上差距有多大?
A:当接受门槛τ设为30%时,PSRD的推理时间约为M3ID方法的4倍,但幻觉减少量比后者多出67.2%。PSRD设计了可调节的门槛参数,用户可根据对速度与精度的不同需求灵活调整,实现快速运行与高精度纠错之间的平衡。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 联想小新 Pro / GT 2026 款锐龙笔记本电脑今日开售:全系 32GB 内存,60~99.9Wh 大电池 + SSR 星耀舒视屏
- 联想小新2026锐龙本开售:全系32GB大内存,这次“元启”有点料 各位关注笔记本市场的朋友们,今天(1月28日)可有新东西看了!联想小新家族一口气上了四款搭载最新AMD锐龙处理器的2026款新品,而且全都贴着“AI元启版”的标签。说实话,这两年AI PC的声势不小,但到底是不是“战未来”,还得看具
- 16分钟前 0
-
 正版软件
正版软件
- 华硕无畏 Pro 14/16 笔记本 2026 款 酷睿版发布:至高可选 Ultra X7 358H 处理器、标配 32GB 内存,6999 元起
- 华硕无畏 Pro 14/16 2026款酷睿版发布:性能猛兽配顶级好屏 今晚华硕的新品发布会大家关注了吗?我全程跟下来,感觉这次灵耀系列的产品线更新确实有不少亮点。其中最吸引我的是无畏Pro 14和16的2026款酷睿版,它们居然搭载了英特尔最新的"Panther Lake"架构处理器,起步价只要6
- 16分钟前 0
-
 正版软件
正版软件
- 华硕灵耀 14 双屏 2026 笔记本发布:双 2.8K 144Hz OLED 触控屏、英特尔酷睿 Ultra X9 388H CPU
- 华硕灵耀14双屏2026发布:双屏设计的又一次进化 昨晚的华硕AI PC发布会真是精彩纷呈,不过要说最让我眼前一亮的,还得是这款灵耀14双屏2026。作为一名长期关注双屏设备的科技爱好者,我得说,这次华硕在双屏设计上又往前迈了一大步。新机搭载了英特尔最新的"Panther Lake"架构酷睿Ultr
- 16分钟前 0
-
 正版软件
正版软件
- 华硕灵耀 14 Air 2026 笔记本发布:至高可选第三代酷睿 Ultra 9 386H 处理器、1.19kg 重量,9999 元
- 华硕灵耀14 Air发布:轻薄性能新标杆,1.19kg机身塞进酷睿Ultra9 话说昨晚华硕那场AI PC发布会,可真是憋了个大招。他们新推的灵耀14 Air,我仔细研究了下参数,感觉这次在轻薄和性能的平衡上玩出了新花样——整机重量控制在1.19kg这个相当惊艳的数字,却敢给你装上第三代酷睿Ultr
- 17分钟前 0
-
 正版软件
正版软件
- Dynabook 发布《攻壳机动队 STAND ALONE COMPLEX》动画联名笔记本
- Dynabook 推出《攻壳机动队》联名笔记本:当经典科幻照进AI现实 说实话,作为一名资深科技编辑,我见过太多品牌联名产品,但上周Dynabook玳能发布的这款《攻壳机动队 STAND ALONE COMPLEX》联名笔记本,确实让我眼前一亮。他们直接在A面印上了动画的主视觉图,这设计够大胆的。更
- 17分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 524天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 531天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 542天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 834天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 550天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2328天前
相关推荐
- 联想小新 Pro / GT 2026 款锐龙笔记本电脑今日开售:全系 32GB 内存,60~99.9Wh 大电池 + SSR 星耀舒视屏
- 华硕无畏 Pro 14/16 笔记本 2026 款 酷睿版发布:至高可选 Ultra X7 358H 处理器、标配 32GB 内存,6999 元起
- 华硕灵耀 14 双屏 2026 笔记本发布:双 2.8K 144Hz OLED 触控屏、英特尔酷睿 Ultra X9 388H CPU
- 华硕灵耀 14 Air 2026 笔记本发布:至高可选第三代酷睿 Ultra 9 386H 处理器、1.19kg 重量,9999 元
- Dynabook 发布《攻壳机动队 STAND ALONE COMPLEX》动画联名笔记本
- TrendForce:预估 2026Q1 笔记本电脑出货量环比衰退 14.8%,二季度有望温和回升
- 2026 年荣耀 PC 各系列全线出击,多款笔记本通过 3C 认证
- 2026 款惠普星 Book Pro 16 笔记本上架:酷睿 Ultra X7 358H + 32G + 1T 售 7999 元
- 黑鲨电竞小平板海外发布:8.8 英寸 2K 屏,骁龙 8s Gen 3 处理器
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00