如何在 Java 中利用 面向对象的组合模式 构建支持无限递归的动态规则判别引擎
 发布于2026-05-01 阅读(0)
发布于2026-05-01 阅读(0)
扫一扫,手机访问
如何在 Ja va 中利用面向对象的组合模式构建支持无限递归的动态规则判别引擎

理解组合模式在规则引擎中的核心价值
组合模式的价值,从来不是为了“套用”某个设计模式。它的真正用武之地,在于解决一类非常典型的问题:当规则本身可以嵌套、分组、条件化,并且结构完全不确定时——比如用户自定义的“所有条件都满足”、“任意一个满足”或者“非此即彼”的复杂逻辑,同时还需要一套统一的执行逻辑。这时候,用树形结构来建模就显得再自然不过了。
在 Ja va 中实现这一点,其实并不依赖任何重型框架。关键在于一个巧妙的抽象:把“单个规则”和“规则容器”统一到同一个接口下。这样一来,调用方就完全无需区分眼前的是叶子节点还是分支节点,只管调用即可,整个系统的扩展性和灵活性也就随之而来。
定义统一的 Rule 接口与基础实现
一切的基础,是定义一个顶层的、统一的行为契约。这个契约非常简单:
Rule.ja va
boolean evaluate(Context context);
有了这个契约,我们就可以提供两类具体的实现:
- 原子规则(Leaf):比如
EqualsRule("status", "active")或者GreaterThanRule("age", 18)。它们直接读取上下文中的字段,进行判断,然后返回一个布尔结果,干净利落。 - 组合规则(Composite):比如
AndRule(List、children) OrRule(List或者children) NotRule(Rule inner)。它们的evaluate()方法会递归地调用所有子规则,再根据逻辑运算符(与、或、非)来聚合最终结果。
你看,通过这样的设计,任意深度的嵌套表达式——比如 AND(OR(A, B), NOT(C))——都能用一个清晰的对象树来表示。更妙的是,未来如果需要增加新的运算符,你只需要新增一个 Composite 类,完全不用修改已有的任何逻辑,这完美符合了“开闭原则”。
支持动态构建与运行时解析
理论模型有了,接下来就得让它“活”起来,能处理用户动态配置的规则。用户通常会用 JSON 或者一套自定义的 DSL 来描述规则,我们的任务就是把这些配置解析成一棵活的 Rule 对象树。
举个例子,解析下面这段 JSON:
{ "type": "and", "children": [ { "type": "eq", "field": "role", "value": "admin" }, { "type": "or", "children": [ { "type": "gt", "field": "score", "value": 90 }, { "type": "lt", "field": "age", "value": 35 } ] } ] }
实现起来并不复杂。我们可以编写一个轻量的 RuleParser,利用工厂方法,根据 JSON 中的 type 字段来创建对应的 Rule 实例。对于 children 这样的嵌套字段,就递归地调用解析器自身。这里有个细节值得注意:每个组合规则在构造时,最好不要立即校验子规则列表是否为空。允许空列表,并为其设定一个默认行为(比如 AND 规则遇到空列表时返回 true,OR 规则返回 false),可以有效避免运行时出现恼人的空指针异常。
执行时避免栈溢出与提升性能
“支持无限递归”听起来很强大,但在真实世界里,无限不等于无限制。嵌套层数一旦过深(比如上百层),Ja va 的调用栈就很可能撑不住,抛出 StackOverflowError。怎么解决?通常有两个思路:
- 主动防御:在
evaluate()方法中加入一个深度计数器,一旦超过预设的阈值(例如50层),就主动抛出像RuleEvaluationException("max depth exceeded")这样的业务异常,提前终止,避免系统崩溃。 - 改变执行模型:将隐式的递归调用,改为使用显式的栈(比如
Deque)来手动控制遍历过程。每个栈帧记录当前正在执行的规则和下一个要处理的子规则索引。这种方法不仅完全避免了栈溢出,内存消耗可控,而且在调试和日志记录时会清晰得多。
除了稳定性,性能也是关键。对于那些被高频调用、且计算结果纯函数化的原子规则(即输出只依赖于输入上下文,没有副作用),完全可以引入缓存机制。用一个 CachedRule 包装器,内部通过 WeakHashMap 来缓存最近的评估结果,这里的 ContextKey 可以根据规则依赖的字段哈希值来生成。这能在规则复杂、计算成本高时,带来显著的性能提升。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 怎样在Debian中调试Golang程序
- 在Debian系统中调试Golang程序 想在Debian系统里高效地调试Golang程序吗?Delve调试器绝对是你的不二之选。它功能强大,专为Go语言设计,能让你像外科手术一样精准地定位代码问题。下面,我们就来一步步搞定它的安装和使用。 第一步:安装Delve 首先,得确保你的系统已经装好了Go
- 11分钟前 0
-
 正版软件
正版软件
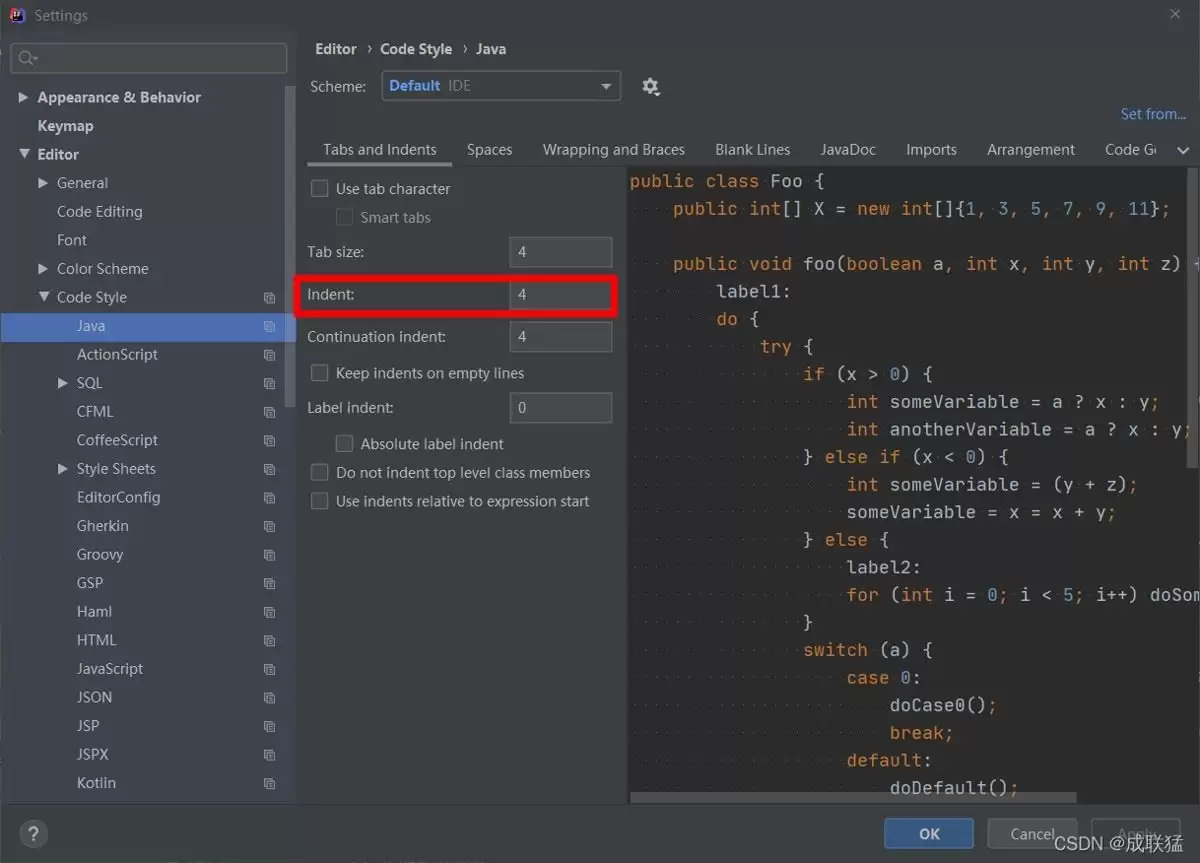
- idea设置回车换行缩进空格数为4的实现方式
- 首先在设置里设置 很多开发者习惯将代码缩进设置为4个空格,这能让代码结构看起来更清晰。在IntelliJ IDEA里,你通常会先到“设置”(Settings)里找到“编辑器”>“代码风格”,把制表符和缩进大小都调成4。这步操作,相信大家都轻车熟路了。 但是发现回车换行时 问题来了:设置改好后,满怀期
- 11分钟前 0
-
 正版软件
正版软件
- Debian上如何优化Golang内存使用
- 在Debian上优化Golang程序的内存使用 在Debian系统上运行Golang应用,内存效率往往是性能调优的关键一环。毕竟,谁不希望自己的程序既反赌,又吃得少呢?今天,我们就来聊聊几个切实可行的优化策略,帮你把程序的内存胃口管起来。 1. 升级Go版本 优化第一步,不妨从基础做起:确保你使用的
- 12分钟前 0
-
 正版软件
正版软件
- 怎样在Debian中安装Golang
- 在Debian系统中安装Golang,可以按照以下步骤进行 方法一:使用APT包管理器 对于大多数用户来说,通过系统自带的包管理器安装是最直接、最省心的方式。Debian的官方仓库已经为我们准备好了现成的Golang包。 更新APT包列表 动手之前,先确保你的本地软件包列表是最新的。打开终端,输入:
- 13分钟前 0
-
 正版软件
正版软件
- Debian上Golang如何进行代码审查
- Debian上Golang代码审查实操指南 一 环境准备 想在Debian上顺畅地开展Go代码审查,先把基础环境搭好。这事儿不难,按部就班来就行。 安装 Go 与 Git:打开终端,执行 sudo apt update && sudo apt install -y golang git 一条命令搞定
- 14分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 235天前
-
4
- 探析Spring Boot框架的优点和特色
- 551天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 489天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 464天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1097天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 924天前
-
 9
9
- 解决Python安装失败的问题
- 475天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00