python使用pdfplumber库一键提取pdf中的所有超链接
 发布于2026-05-03 阅读(0)
发布于2026-05-03 阅读(0)
扫一扫,手机访问
前言
在PDF的世界里,超链接有一个更专业的名字——“链接注释”。
根据PDF规范,它本质上是一种特殊的注释类型。其核心结构定义了用户可以点击的区域、指定了要跳转的目标地址(可能是网页URI,也可能是文档内的某个页面),并且可以设置一些视觉样式。正是这种设计,让PDF阅读器能够识别并响应我们的点击操作。
今天,我们就来聊聊如何用Python里的一个利器——pdfplumber库,把这些“藏”在PDF里的超链接给精准地“挖”出来。
pdfplumber这个库,专攻PDF文档解析。无论是文档的作者、创建时间这些基本信息,还是更复杂的表格、文本、图片,乃至我们今天的主角——超链接,它基本都能搞定,足以应对大多数常规的内容提取需求。
安装起来也毫不费力,一条pip命令就能搞定:
pip install pdfplumber
提取 pdf 中超链接详解
提取超链接,pdfplumber已经为我们准备好了现成的工具。每个页面对象都有一个.hyperlinks属性,调用它,就能直接获取当前页面上所有的超链接信息,返回的结果是一个字典列表,非常清晰。
来看一段基础代码。我们用pdfplumber打开一个名为“test.pdf”的文件,然后遍历每一页,通过.hyperlinks属性获取链接:
import pdfplumber
with pdfplumber.open(r'./data/test.pdf') as pdf_info:
for page in pdf_info.pages:
links = page.hyperlinks
print(links)
运行之后,你会得到一个结构化的列表,里面包含了链接所在的页码、目标URI地址等关键信息。效果类似下图所示:
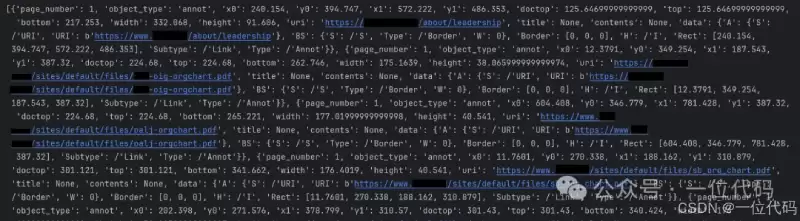
接下来,我们只需要从这个字典列表里,把我们需要的信息(比如URI)提取出来就行了。
下面是一个完整的函数示例。你只需要把文件路径换成你自己的PDF文件完整路径,运行后就能得到文档里所有页面的所有超链接。
import pdfplumber
def get_links(file_path):
res_links = []
with pdfplumber.open(file_path) as pdf_info:
page_number = 0
for page in pdf_info.pages:
page_number += 1
links = page.hyperlinks
if links:
for link in links:
res_link = link.get('uri')
res_links.append(res_link)
print(f'第{page_number}页,共有{len(links)}个超链接!')
else:
print(f'第{page_number}页,不存在超链接!')
return res_links
if __name__=="__main__":
# 文件路径为 pdf 完整路径
res_links = get_links('data/FCC_all.pdf')
print(res_links)
当然,这只是提取PDF超链接的其中一种有效方法,供各位参考。
方法补充
基本用法:提取所有超链接
核心逻辑其实非常直观:打开PDF,循环遍历每一页,然后从页面的hyperlinks属性里取出uri(也就是目标网址)。
import pdfplumber
def extract_links(pdf_path):
all_links = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
page_links = page.hyperlinks
if page_links:
for link in page_links:
# 每个 link 是一个字典,'uri' 键存储了目标网址
uri = link.get('uri')
if uri:
all_links.append(uri)
return all_links
if __name__ == "__main__":
links = extract_links("你的文件.pdf")
for link in links:
print(link)
如果你想更清楚地知道每个链接出自哪一页,可以在遍历时加上页码信息:
for i, page in enumerate(pdf.pages):
links = page.hyperlinks
if links:
print(f"第 {i+1} 页 有 {len(links)} 个链接")
for link in links:
print(f" - {link.get('uri')}")
else:
print(f"第 {i+1} 页 没有链接")
高级用法:灵活处理
处理其他类型的链接
需要留意的是,hyperlinks返回的字典里,不一定只有uri(网页链接)。它还可能包含指向PDF文档内部其他页面的链接(键为page),或者指向文档内某个命名目标的链接(键为nameddest)。区分处理它们能让你的脚本更健壮。
if 'uri' in link:
print(f"网页链接: {link['uri']}")
elif 'page' in link:
print(f"内部链接: 第 {link['page']} 页")
elif 'nameddest' in link:
print(f"命名目标: {link['nameddest']}")
提取链接的链接文本(高级技巧)
有时候,我们不仅想知道链接指向哪里,还想知道这个链接在PDF里显示成什么文字(比如“点击这里”或“了解更多”)。pdfplumber本身没有直接提供这个功能,但我们可以通过一个“曲线救国”的方式来实现:利用页面的chars属性(它包含了页面上每个字符的详细信息,包括坐标)。基本思路是,先拿到链接的矩形区域坐标(x0, y0, x1, y1),然后筛选出所有落在这个区域内的字符,再把它们组合起来,就得到了链接文本。这涉及到一些坐标计算,但对于处理复杂文档来说,是个非常实用的技巧。
处理加密PDF
如果遇到加密的PDF文件也不用慌。pdfplumber.open()方法贴心地提供了password参数,传入密码即可正常打开并解析。
with pdfplumber.open("encrypted.pdf", password="你的密码") as pdf:
# ... 正常提取链接
常见问题与注意事项
- 链接提取不到?这里有个关键概念:pdfplumber提取的是PDF标准中的“链接注释”。如果你的PDF里,网址是直接以纯文本形式写在内容里的(而不是可点击的链接对象),那么用文本搜索或正则表达式去匹配会更直接有效。
- 小心
CroppedPage相关的Bug:如果你对页面对象进行了裁剪操作,可能会遇到一些与CroppedPage相关的超链接提取Bug。万一碰到这种情况,可以尝试将pdfplumber更新到最新版本,或者更稳妥一点——直接在原始的、未经裁剪的Page对象上提取链接。 - 扫描版PDF无能为力:这一点必须明确:pdfplumber主要擅长处理计算机直接生成的PDF。如果你的PDF是扫描件(也就是一堆图片),那么库是无法直接从中提取超链接甚至文本的。这种场景下,你需要先借助OCR技术(比如
pytesseract这样的工具)把图片文字识别出来,再进行后续处理。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- c#如何调用WebAPI_c#WebAPI的最佳实践与常见坑点
- C#调用WebAPI的最佳实践与常见坑点 在微服务架构盛行的今天,通过HttpClient调用WebAPI几乎是每个C#开发者的日常。然而,从简单的GET请求到高并发下的稳定通信,中间隔着一系列容易踩坑的细节。下面我们就来梳理几个关键的最佳实践和那些容易让人栽跟头的“坑点”。 HttpClient
- 4分钟前 0
-
 正版软件
正版软件
- 如何正确处理 AJAX 提交后的 PHP 响应页面跳转问题
- AJAX 本身用于异步请求且不刷新页面,若需在提交数据后跳转并显示 PHP 处理结果,不应混合使用 $.ajax 和 window.open,而应改用表单 POST 提交或在 AJAX 成功回调中动态渲染响应内容。 很多开发者都遇到过这个典型的“断层”问题:前端明明通过 AJAX 把数据成功提交给了
- 4分钟前 0
-
 正版软件
正版软件
- c#如何使用for循环_c#for循环的正确用法与注意事项
- for循环必须理解三段式结构的执行时序和作用域边界,否则易导致逻辑错位、变量泄漏或无限循环;三个表达式执行顺序为:初始化→判断→循环体→迭代表达式,不可凭直觉猜测。 在C#里使用for循环,远不止“用对就行”那么简单。核心在于,你必须透彻理解其三段式结构的执行时序和作用域边界。否则,逻辑错位、变量泄
- 5分钟前 0
-
 正版软件
正版软件
- 为什么宝塔面板在线解压ZIP网站源码后出现大量乱码文件
- 为什么宝塔面板在线解压ZIP网站源码后出现大量乱码文件 在宝塔面板里解压一个从Windows传过来的ZIP包,结果发现中文文件名全变成了“天书”?别慌,这几乎是每个站长都会踩的坑。问题不在你的文件,而在于一个跨平台的老大难问题:编码打架。 宝塔用图形界面解压 ZIP 时中文文件名直接变乱码 说到底,
- 6分钟前 0
-
 正版软件
正版软件
- c#如何使用LINQ查询_c#LINQ查询常见问题与排错指南
- C# LINQ查询常见问题与排错指南 在C#开发中,Where过滤、Select投影、OrderBy排序这三个操作,几乎能搞定90%以上的内存集合查询需求。但话说回来,LINQ用起来顺手,坑也真不少:一个符号写错、一次枚举控制漏掉,或者不小心在IQueryable上误用了某个C#方法,轻则查出一堆空
- 7分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 237天前
-
4
- 探析Spring Boot框架的优点和特色
- 553天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 491天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 467天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1099天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 927天前
-
 9
9
- 解决Python安装失败的问题
- 477天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00