HDFS如何支持大数据分析
 发布于2026-05-03 阅读(0)
发布于2026-05-03 阅读(0)
扫一扫,手机访问
HDFS:大数据分析的基石,如何撑起海量数据的世界?
谈到大数据分析,一个绕不开的核心组件就是HDFS(Hadoop分布式文件系统)。它本质上是一个为存储和处理超大规模数据集而生的分布式文件系统。那么,它究竟是如何为大数据分析提供坚实支撑的呢?关键在于以下几大核心特性。
1. 高吞吐量访问:为数据洪流打开闸门
HDFS从设计之初,就将目标锁定在高吞吐量的数据访问上。这可不是锦上添花,而是处理海量数据分析任务的生命线。想象一下,如果数据读取速度成为瓶颈,再强大的计算框架也无用武之地。
2. 近乎线性的可扩展性:从TB到PB的从容
面对不断增长的数据,扩容是否头疼?HDFS的架构允许它轻松扩展到成千上万个节点,每个节点承载部分数据。这种设计使得它能够从容应对从TB级到PB级,甚至更庞大的数据集,业务增长再无后顾之忧。
3. 内置的容错性:让硬件故障不再可怕
在由大量普通硬件组成的集群中,节点故障是常态而非意外。HDFS通过智能的数据复制机制来保障高可靠性。默认情况下,每个数据块都会被复制三份,并策略性地分布在不同节点上。这意味着即便个别节点宕机,数据依然安全无虞,整个系统照常运行。
4. 数据本地化:将计算送到数据家门口
“移动计算比移动数据更划算”——这是HDFS遵循的一个重要原则。系统会尽量将计算任务调度到数据所在的节点上去执行。这样做的好处显而易见:极大减少了数据在网络中的传输开销,直接提升了数据处理的速度和效率。
5. 简化的一致性模型:为实时分析开绿灯
与一些追求强一致性的复杂系统不同,HDFS采用了一种简化的一致性模型。一个典型体现是,它允许在文件写入的同时进行读取。这种特性对于某些需要近实时或流式分析的场景来说,无疑提供了极大的便利。
6. 与处理框架的深度集成:生态的力量
HDFS并非孤岛,它与Apache Hadoop MapReduce、Apache Spark等主流大数据处理框架有着原生的紧密集成。这些框架可以无缝利用HDFS的分布式存储能力,直接在其上运行复杂的分析任务,形成了强大而完整的大数据生态系统。
7. 经济高效:拥抱商用硬件
成本始终是技术选型的关键考量。HDFS的设计允许它在普通的商用硬件上稳定运行,这显著降低了海量数据存储与计算的总体拥有成本,使得大规模数据分析不再是巨头企业的专利。
8. 完善的数据管理与监控
管理一个庞大的分布式存储系统并非易事。幸运的是,HDFS提供了一系列丰富的工具,帮助管理员监控集群的健康状态、检查数据完整性,并跟踪各项性能指标,让运维工作变得清晰可控。
9. 多层次的安全性保障
数据安全至关重要。HDFS提供了包括数据加密、访问控制列表(ACLs)和审计日志在内的多层次安全功能,确保敏感数据在存储和访问过程中的安全性,满足企业级的安全合规要求。
总而言之,正是通过上述这些环环相扣的特性,HDFS为大数据分析构建了一个强大、可靠且经济的基础平台。它使得组织和企业能够有效地存储、管理并分析前所未有的海量数据,从而挖掘出深度的业务洞察,驱动更智能的决策。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:HDFS如何优化性能
下一篇:HDFS如何进行资源管理
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- PHP执行php.exe-v命令报错的解决方案
- 执行php.exe -v命令报错 你肯定遇到过这种情况:兴致勃勃地打开命令行,敲入php.exe -v想看看版本,结果迎面而来的不是亲切的版本号,而是一行让人心头一紧的警告: “PHP Warning: ‘C:\windows\SYSTEM32\VCRUNTIME140.dll’ 14.38 is
- 刚刚 0
-
 正版软件
正版软件
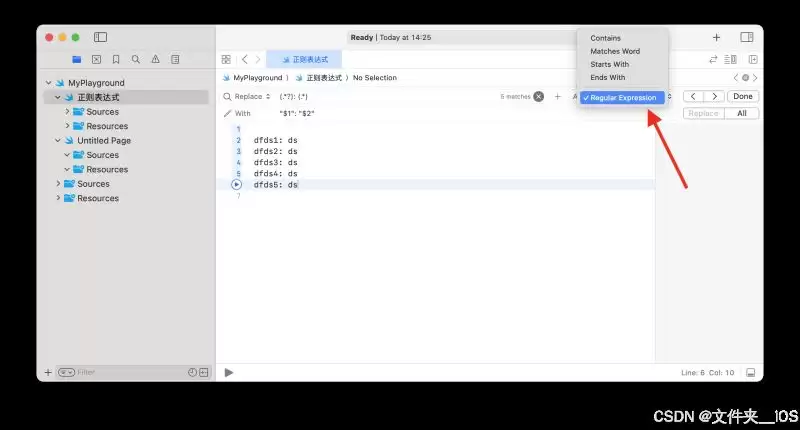
- Xcode 正则表达式实现查找替换功能
- 在Xcode中玩转正则表达式:让查找与替换“快准狠” 处理代码时,查找和替换几乎是每天的必修课。面对杂乱或格式不一的文本,简单字符串匹配常常力不从心。好在,正则表达式为我们提供了一柄“手术刀”——它能在复杂的文本中实现极为精准的模式匹配。如果你恰好是Xcode的重度用户,那么将正则表达式与Xcode
- 1分钟前 0
-
 正版软件
正版软件
- VScode中使用正则表达式替换字符串的3个步骤分享
- 快速回忆点: 搜索: ^(SET_)(.*)(_MM)(.*)替换: set_$2_mm_$4 场景: 工作中,你是不是也遇到过这样的情况?想批量修改一堆代码或文本,用普通的查找替换吧,总会误伤友军;一个个手动改吧,又太费时间。 别急,咱们今天就拿两个典型的场景练练手,看看VSCode的正则表达式替
- 1分钟前 0
-
 正版软件
正版软件
- VsCode中常用的一些正则表达式操作方法
- 在处理大量代码或文本数据时,你是否曾为批量查找和修改特定模式的内容而头疼?其实,Visual Studio Code内置的正则表达式搜索功能,正是解决这类问题的利器。用好它,能让你从繁琐的重复操作中彻底解放出来。 这篇文章将手把手带你掌握几个最实用、最能提升效率的正则搜索技巧,并且会持续更新补充。
- 1分钟前 0
-
 正版软件
正版软件
- Notepad++使用正则表达式匹配的方法
- Notepad++ 使用正则表达式匹配 想打开查找功能?很简单,按下ctrl+F这个快捷键,查找对话框就弹出来了。 接下来,记得选中底部的“正则表达式”选项,就能开启你的模式匹配之旅了。 一、常见匹配 1、正则表达式匹配以某字符开头的这一行数据 表达式:(?:^|\n)字符位置.* 示例:(?:^|
- 2分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 237天前
-
4
- 探析Spring Boot框架的优点和特色
- 553天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 491天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 467天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1099天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 927天前
-
 9
9
- 解决Python安装失败的问题
- 477天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00