关于CPU编程—无锁编程
 发布于2026-05-03 阅读(0)
发布于2026-05-03 阅读(0)
扫一扫,手机访问
无锁编程与分布式编程,谁更适合多核CPU?
前一篇文章我们分析了多核系统中三种典型锁竞争的加速比情况,其中分布式锁竞争的加速比与CPU核数成正比,性能表现相当亮眼。近年来,无锁编程在学术界备受关注。那么,一个很自然的问题是:采用无锁编程能否获得更优的加速比?或者说,它是否比分布式编程更适合多核CPU系统?
无锁编程的本质与性能基础
无锁编程的核心,在于使用原子操作替代传统的锁机制来保护共享资源。举个例子,要对一个整数变量进行加1操作。使用锁保护的代码大家都很熟悉:
int a = 0;
Lock();
a += 1;
Unlock();
如果对这段代码反编译,你会发现 a += 1; 通常被翻译成三条汇编指令:读取、计算、写回。在单核系统中,这三条指令执行期间若发生任务切换,其他任务对变量a的操作可能导致不可预测的结果,因此必须用锁保护。而在多核系统中,情况更复杂:即便是一条指令,也可能因为多个物理核心的并行写入而产生数据竞争,所以同样需要保护。
如果使用原子操作,例如VC中的 InterlockedIncrement(&a),最终的加1操作会被翻译成一条带 lock 前缀的汇编指令。这条指令通过内存栅障(memory barrier)阻止其他任务同时写入同一内存,从而避免竞争。原子操作的速度通常比锁快一倍以上,可以看作一种粒度极细的锁。
在无锁编程中,最常用的原子操作是CAS(Compare and Swap),例如VC中的 InterlockedCompareExchange。其最大优势是非阻塞性。但需要注意的是,像 InterlockedCompareExchange 这类操作带有全局内存栅障(full memory barrier),这意味着即便不是访问同一内存变量的原子操作也可能发生竞争。从竞争形式上看,这会引发固定式或随机式锁竞争,而无法实现理想的分布式竞争模式,其竞争激烈程度甚至可能超过使用普通锁的情况,最终加速比可能比固定式锁竞争更不理想。
当然,也有像 InterlockedCompareExchangeAcquire 这样不使用全局内存栅障的原子操作,理论上性能更好,但其对硬件有特定要求,且实际性能数据相对缺乏。
无锁编程在不同竞争模式下的加速比分析
那么,无锁编程在实际竞争中的表现究竟如何?我们可以套用上一篇文章的模型进行分析。
首先看固定式锁竞争。原子操作比普通锁快,我们假设其加锁/解锁时间减少为原来的1/2(即任务粒度增大一倍),同时其锁内操作指令极少,锁粒度可近似视为0。代入公式后,其加速比极限值大约为使用普通锁时的两倍任务粒度大小,比使用普通锁时提升约一倍,但依然无法随CPU核数线性增长。
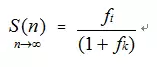
其次是随机式锁竞争。将普通锁替换为原子操作(锁粒度≈0)后,对于任务粒度非常大的情况,竞争概率p增加不明显;对于任务粒度极小的情况,概率p最大可增加近一倍,加速比也能获得一定提升。但在最坏情况下,其加速比公式表明,性能只是相对于普通锁略有提高,同样无法随CPU核数增加而增长。
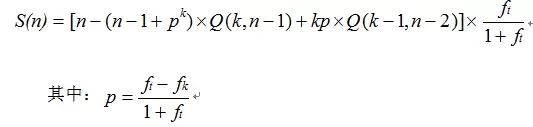
这里必须提一个关键点:上述分析尚未考虑无锁编程自身的算法开销。在实际的无锁算法中,一个CAS操作往往需要在一个循环中反复尝试才能成功完成一次写入,循环次数可能很多,这会导致实际性能低于理论计算结果。
因此,结论很清晰:即使采用无锁编程,只要其竞争模式仍是固定式或随机式,其加速比性能依然不乐观,与分布式锁竞争(其最坏情况加速比也能接近CPU核数)相距甚远。
分布式竞争与无锁结合的可能性
有人可能会想:既然分布式锁竞争性能这么好,那用原子操作替代普通锁来实现分布式竞争,岂不是能获得更好的加速比?
从理论上讲,如果使用不带全局内存栅障的原子操作进行分布式竞争,确实可能比使用普通锁获得更好的加速比。根据分布式加速比公式,使用原子操作后,任务粒度会增大2~3倍。对于任务粒度极小(实践中罕见)的情况,加速比可比使用普通锁时提升近一倍;但对于常见的、任务粒度较大的情况,加速比提升并不明显。
任务粒度的大小,很大程度上取决于程序员的划分。只要在划分任务时避免粒度过小,就能有效降低其对加速比的负面影响。而使用分布式锁竞争时,性能已经可以逼近单核多任务时的程序性能了。
实用性对比:为何分布式编程更胜一筹?
谈完理论性能,我们再来看看更现实的工程因素:实现难度和迁移成本。
无锁编程的难度极高,代码复杂,正确性严重依赖于对目标机器内存模型的精确理解,普通程序员难以掌握。而分布式编程的思维模式与单核多任务时代的数据结构与算法编程一脉相承,普通程序员经过学习完全可以掌握。
更重要的是生态继承性。目前无锁算法实现有限,功能也受限,且它几乎是一套独立于传统单核编程的新体系,难以复用以往的成果。分布式编程则是在原有单核多任务编程范式上的自然演进,可以充分继承之前的成果。例如,实现一个队列池,可以直接复用已有的成熟队列算法。这意味着,采用分布式编程能将现有单核程序移植到多核系统的工作量大大降低,通常只需进行一定程度的重构即可。
结论
综合来看,我们可以从四个维度对两者进行比较:
| 比较项目 | 无锁编程 | 分布式编程 |
|---|---|---|
| 加速比性能 | 取决于竞争方式。除非采用分布式竞争,否则性能不如分布式锁竞争。 | 加速比与CPU核数成正比,性能接近单核多任务时的水平。 |
| 实现的功能 | 有限 | 不受限制 |
| 程序员掌握难易程度 | 难度过高、过于复杂,普通程序员难以掌握。 | 与单核时代的数据结构算法难度相当,普通程序员可以掌握。 |
| 现有软件的移植 | 需废弃旧算法,无法复用以往成果。 | 可继承已有算法,在原有程序基础上重构即可。 |
从上表的综合比较不难看出,在绝大多数实际应用场景中,无锁编程的实用价值远低于分布式编程。因此,对于多核CPU系统而言,分布式编程是比无锁编程更合适、更务实的选择。
转自:http://blog.csdn.net/windows_zf/article/details/3086498
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:编程范式有哪些
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 如何通过dmesg检查驱动程序状态
- dmesg:深入Linux内核的“行车记录仪” 在Linux世界里,dmesg(全称display message或driver message)堪称系统内核的“实时日志”与“行车记录仪”。这个看似简单的命令行工具,能让你直接窥探内核消息缓冲区的动态,里面记录着从硬件自检、驱动加载到各类系统事件的宝
- 6分钟前 0
-
 正版软件
正版软件
- dmesg日志中的网络信息如何解读
- 解读dmesg日志中的网络信息:一份实战指南 在Linux系统的运维和故障排查中,dmesg命令(即display message或driver message)堪称一把利器。它忠实地记录着内核从启动到运行过程中的各种信息,其中就包含了网络硬件与驱动状态的完整“体检报告”。面对海量的日志输出,如何快
- 7分钟前 0
-
 正版软件
正版软件
- dmesg日志对硬件诊断有何帮助
- dmesg日志:硬件诊断的“黑匣子” 在Linux系统的工具箱里,dmesg(即display message或driver message)命令扮演着一个至关重要的角色。它就像系统内核的“实时通讯录”,专门负责显示内核环缓冲区里的消息。这些消息可不是普通的系统日志,它们往往记录了从硬件设备初始化、
- 8分钟前 0
-
 正版软件
正版软件
- PHP日志中的内存泄漏问题
- 在PHP中,内存泄漏是指程序在申请内存后,无法释放已申请的内存空间,一次又一次地申请内存,导致系统的可用内存越来越少,最终可能导致程序崩溃或系统崩溃。内存泄漏可能是由于编程错误、扩展模块的问题或者PHP本身的bug导致的。 要解决PHP日志中的内存泄漏问题,可以尝试以下方法: 1. 定位内存泄漏源
- 8分钟前 0
-
 正版软件
正版软件
- PHP日志中的数据库错误
- 在PHP应用程序中搞定那些恼人的数据库错误 和数据库打交道,出错几乎是每位PHP开发者的必修课。查询语法不对、连接配置出岔子、权限不够,或是数据类型不匹配,都可能让程序瞬间“罢工”。虽然无法看到你具体的报错信息,但下面这几个排查方向,堪称解决大多数数据库问题的“万能钥匙”。 1. 检查查询语法:从源
- 8分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 237天前
-
4
- 探析Spring Boot框架的优点和特色
- 553天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 491天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 467天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1099天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 927天前
-
 9
9
- 解决Python安装失败的问题
- 477天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00