开源VLMs达到更高潜力的催化剂- RoboFlamingo创造机器人视觉-语言操作新纪元
 发布于2024-11-07 阅读(0)
发布于2024-11-07 阅读(0)
扫一扫,手机访问
机器之心专栏
机器之心编辑部
还在苦苦寻找开源的机器人大模型?试试RoboFlamingo!
近年来,大模型的研究正在加速推进,它逐渐在各类任务上展现出多模态的理解和时间空间上的推理能力。机器人的各类具身操作任务天然就对语言指令理解、场景感知和时空规划等能力有着很高的要求,这自然引申出一个问题:能不能充分利用大模型能力,将其迁移到机器人领域,直接规划底层动作序列呢?
ByteDance Research基于OpenFlamingo开发了易用的RoboFlamingo机器人操作模型。通过微调,VLM可变成Robotics VLM,适用于语言交互的机器人操作任务。训练只需单机,使用简单。
OpenFlamingo 在机器人操作数据集 CALVIN 上进行了验证。实验结果表明,尽管只利用了带语言标注的数据的1%,RoboFlamingo在一系列机器人操作任务上取得了最先进的性能(SOTA)。此外,随着RT-X数据集的开放,采用开源数据预训练的RoboFlamingo并将其fine-tune到不同的机器人平台,有望成为一个简单有效的机器人大模型pipeline。 该论文还测试了各种不同的policy head、训练范式和Flamingo结构的VLM在Robotics任务上进行微调的表现。这些实验得出了一些有意思的结论。

- 项目主页:https://roboflamingo.github.io
- 代码地址:https://github.com/RoboFlamingo/RoboFlamingo
- 论文地址:https://arxiv.org/abs/2311.01378
研究背景

基于语言的机器人操作是具身智能领域的重要应用之一。它涉及多模态数据的理解和处理,包括视觉、语言和控制等。近年来,视觉语言基础模型(VLMs)在图像描述、视觉问答和图像生成等领域取得了显著进展。然而,将这些模型应用于机器人操作仍然面临一些挑战。其中之一是如何有效地结合视觉和语言信息,以提高机器人的感知和理解能力。另一个挑战是如何处理机器人操作的时序性,即在不同时间点上正确执行并协调不同的动作。解决这些挑战将推动基于语言的机器人操作的发展,进一步提升机器人在真实世界中的应用能力。
为了解决这些问题,ByteDance Research的机器人研究团队在现有的开源VLM(Visual Language Model)OpenFlamingo的基础上进行了微调和重设计,开发出了一套全新的视觉语言操作框架,命名为RoboFlamingo。RoboFlamingo采用VLM进行单步视觉语言理解,同时引入额外的policy head模块来处理历史信息。通过简单的微调方法,RoboFlamingo能够适应基于语言的机器人操作任务。这一创新的框架为解决语言和视觉交互中的挑战提供了有力的工具,并为机器人操作的进一步发展提供了新的可能性。
RoboFlamingo 在基于语言的机器人操作数据集 CALVIN 上进行了验证,实验结果表明,RoboFlamingo 只利用了 1% 的带语言标注的数据即在一系列机器人操作任务上取得了 SOTA 的性能(多任务学习的 task sequence 成功率为 66%,平均任务完成数量为 4.09,基线方法为 38%,平均任务完成数量为 3.06;zero-shot 任务的成功率为 24%,平均任务完成数量为 2.48,基线方法为 1%,平均任务完成数量是 0.67),并且能够通过开环控制实现实时响应,可以灵活部署在较低性能的平台上。这些结果表明,RoboFlamingo 是一种有效的机器人操作方法,可以为未来的机器人应用提供有用的参考。
方法
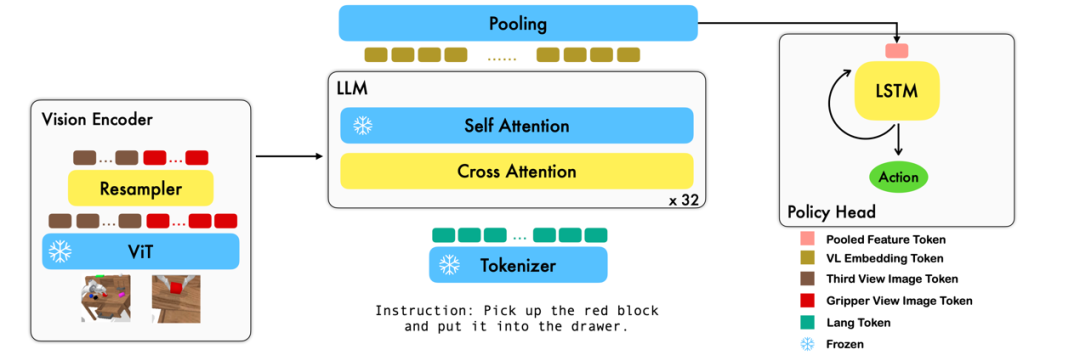
本工作利用已有的基于图像 - 文本对的视觉语言基础模型,通过训练端到端的方式生成机器人每一步的 relative action。模型的主要模块包含了 vision encoder,feature fusion decoder 和 policy head 三个模块。Vision encoder 模块先将当前视觉观测输入到 ViT 中,并通过 resampler 对 ViT 输出的 token 进行 down sample。Feature fusion decoder 将 text token 作为输入,并在每个 layer 中先将 vision encoder 的 output 作为 query 进行 cross attention,之后进行 self attention 以完成视觉与语言特征的融合。最后,对 feature fusion decoder 进行 max pooling 后将其送入 policy head 中,policy head 根据 feature fusion decoder 输出的当前和历史 token 序列直接输出当前的 7 DoF relative action,包括了 6-dim 的机械臂末端位姿和 1-dim 的 gripper open/close。
在训练过程中,RoboFlamingo 利用预训练的 ViT、LLM 和 Cross Attention 参数,并只微调 resampler、cross attention 和 policy head 的参数。
实验结果
数据集:
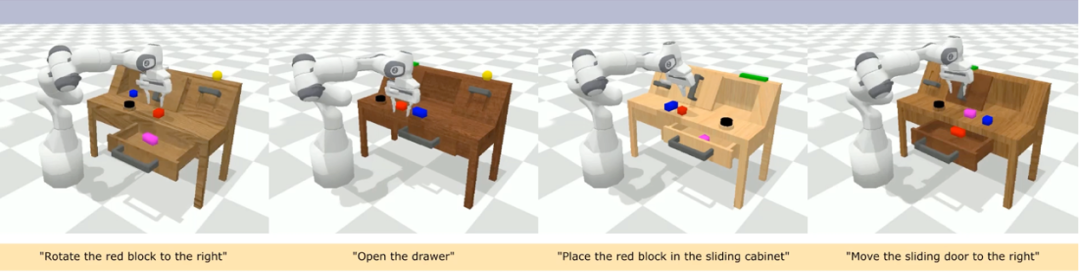
CALVIN(Composing Actions from Language and Vision)是一个开源的模拟基准测试,用于学习基于语言的 long-horizon 操作任务。与现有的视觉 - 语言任务数据集相比,CALVIN 的任务在序列长度、动作空间和语言上都更为复杂,并支持灵活地指定传感器输入。CALVIN 分为 ABCD 四个 split,每个 split 对应了不同的 context 和 layout。
定量分析:
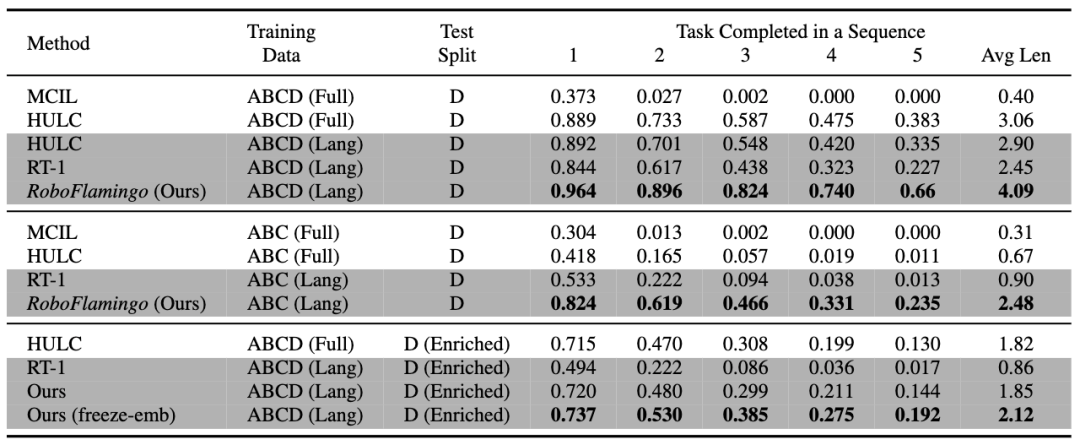
RoboFlamingo 在各设置和指标上的性能均为最佳,说明了其具有很强的模仿能力、视觉泛化能力以及语言泛化能力。Full 和 Lang 表示模型是否使用未配对的视觉数据进行训练(即没有语言配对的视觉数据);Freeze-emb 指的是冻结融合解码器的嵌入层;Enriched 表示使用 GPT-4 增强的指令。
消融实验:
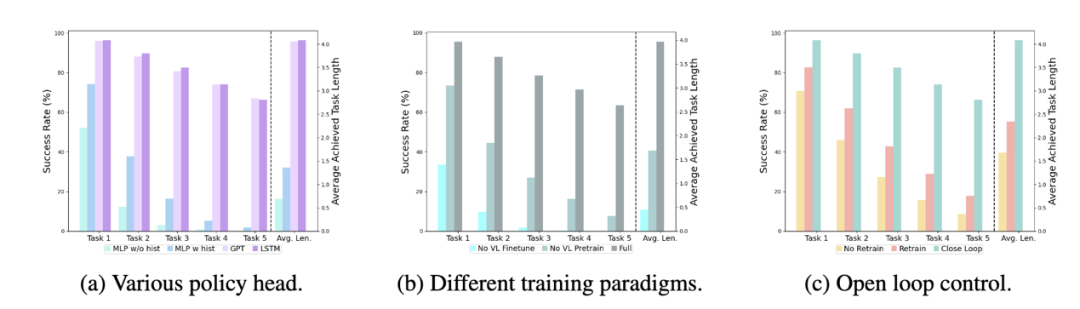
不同的 policy head:
实验考察了四种不同的策略头部:MLP w/o hist、MLP w hist、GPT 和 LSTM。其中,MLP w/o hist 直接根据当前观测预测历史,其性能最差,MLP w hist 将历史观测在 vision encoder 端进行融合后预测 action,性能有所提升;GPT 和 LSTM 在 policy head 处分别显式、隐式地维护历史信息,其表现最好,说明了通过 policy head 进行历史信息融合的有效性。
视觉-语言预训练的影响:
预训练对于 RoboFlamingo 的性能提升起到了关键作用。实验显示,通过预先在大型视觉-语言数据集上进行训练,RoboFlamingo 在机器人任务中表现得更好。
模型大小与性能:
虽然通常更大的模型会带来更好的性能,但实验结果表明,即使是较小的模型,也能在某些任务上与大型模型媲美。
指令微调的影响:
指令微调是一个强大的技巧,实验结果表明,它可以进一步提高模型的性能。






定性结果
相较于基线方法,RoboFlamingo 不但完整执行了 5 个连续的子任务,且对于基线页执行成功的前两个子任务,RoboFlamingo 所用的步数也明显更少。

总结
本工作为语言交互的机器人操作策略提供了一个新颖的基于现有开源 VLMs 的框架,使用简单微调就能实现出色的效果。RoboFlamingo 为机器人技术研究者提供了一个强大的开源框架,能够更容易地发挥开源 VLMs 的潜能。工作中丰富的实验结果或许可以为机器人技术的实际应用提供宝贵的经验和数据,有助于未来的研究和技术发展。
参考文献:
1. Brohan, Anthony, et al. "Rt-1: Robotics transformer for real-world control at scale." arXiv preprint arXiv:2212.06817 (2022).
2. Brohan, Anthony, et al. "Rt-2: Vision-language-action models transfer web knowledge to robotic control." arXiv preprint arXiv:2307.15818 (2023).
3. Mees, Oier, Lukas Hermann, and Wolfram Burgard. "What matters in language conditioned robotic imitation learning over unstructured data." IEEE Robotics and Automation Letters 7.4 (2022): 11205-11212.
4. Alayrac, Jean-Baptiste, et al. "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems 35 (2022): 23716-23736.
5. Mees, Oier, et al. "Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks." IEEE Robotics and Automation Letters 7.3 (2022): 7327-7334.
6. Padalkar, Abhishek, et al. "Open x-embodiment: Robotic learning datasets and rt-x models." arXiv preprint arXiv:2310.08864 (2023).
7. Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
8. Awadalla, Anas, et al. "Openflamingo: An open-source framework for training large autoregressive vision-language models." arXiv preprint arXiv:2308.01390 (2023).
9. Driess, Danny, et al. "Palm-e: An embodied multimodal language model." arXiv preprint arXiv:2303.03378 (2023).
10. Jiang, Yunfan, et al. "VIMA: General Robot Manipulation with Multimodal Prompts." NeurIPS 2022 Foundation Models for Decision Making Workshop. 2022.
11. Mees, Oier, Jessica Borja-Diaz, and Wolfram Burgard. "Grounding language with visual affordances over unstructured data." 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.
12. Tan, Mingxing, and Quoc Le. "Efficientnet: Rethinking model scaling for convolutional neural networks." International conference on machine learning. PMLR, 2019.
13. Zhang, Tianhao, et al. "Deep imitation learning for complex manipulation tasks from virtual reality teleoperation." 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- trc20和erc20哪个更快
- TRC-20比ERC-20更快,因为它具有更短的区块时间和更少的网络拥塞。TRC-20每秒可处理2,000笔交易,而ERC-20为15-25笔;TRC-20区块时间为3秒,而ERC-20为12-15秒。此外,Tron网络通常不太拥挤,节点数量、网络稳定性和交易费用也更具优势。
- 11分钟前 0
-
 正版软件
正版软件
- 人人都可成为AI开发者!李彦宏带来三大AI开发神器
- 2023年初崛起为科技领域最亮的星,展示了凯AI技术变革经济社会的巨大潜能。经过一年多的技术突破和市场验证,进入2024年,大模型的巨大价值已经得到主流国家的共识,主流科技公司纷纷布局。美国、中国等国家,正处于引领大模型产业发展的未来。在国内科技公司中,率先发布文心大模型的百度,已经取得了不凡成果。在今日举办的Create2024百度AI开发者大会上,百度创始人、董事长兼首席执行官李彦宏在主题演讲中透露,文心一言用户数突破2亿,文心大模型成为中国最领先、应用最广泛的AI基础模型。与此同时,李彦宏还打算让所
- 26分钟前 大模型 AI开发 0
-
 正版软件
正版软件
- AI失业潮已来,程序员职业是否真的会消失?
- 最近,有消息称OpenAI将发布突破性的多模态机器学习模型GPT-4o。关于人工智能引发全球性失业潮的报道再次占据各大媒体头条。国际货币基金组织总经理克里斯塔利娜·格奥尔基耶娃博士警告称,随着企业大量采用人工智能技术,全球劳动力市场将遭遇“海啸”,人工智能可能会消灭全球近一半(40%)的工作岗位以及美国和英国等发达经济体一半以上(60%)的工作岗位。克里斯塔利娜·格奥尔基耶娃博士在一次演讲中指出,人工智能的发展将对各行各业产生深远影响。尽管人工智能有助于提高生产效率和创新能力,但也将导致大规模的岗位消失。
- 41分钟前 人工智能 机器学习 OpenAI 0
-
正版软件
- 虚拟货币交易平台前十 全球最大的虚拟货币交易所排行
- 全球虚拟货币交易所排名根据交易量和用户数量,排名如下:交易量:币安火币OKXFTX币安美国用户数量:币安火币CoinbaseFTXOKX
- 51分钟前 0
-
正版软件
- 中国正规数字货币交易平台
- 中国境内仅有7家正规数字货币交易平台:火币网、OKX、币安中国、抹茶网、库币网、MXC抹茶、BitMart币玛特。这些平台已获得境外金融牌照,可为中国用户提供数字货币交易服务,但不得从事法币交易或代理其他交易平台。
- 1小时前 02:14 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1983天前
-
 2
2
- Overture设置踏板标记的方法
- 1820天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1809天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 2008天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1974天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1970天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1984天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 2006天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00