LangChain技术指南与案例分析:用于多用户数据检索的综合解决方案
 发布于2024-11-20 阅读(0)
发布于2024-11-20 阅读(0)
扫一扫,手机访问
作者 | 崔皓
审校 | 重楼
摘要
文章探讨了如何确保不同用户数据的隔离,并提供灵活的配置选项以适应各种检索需求。

本文首先介绍了多用户数据检索的背景和挑战。其中包括数据权限管理、检索系统灵活性和用户体验问题。接着进行了技术分析,特别强调了使用Pinecone作为向量数据库来处理高维向量数据的优势。文中详细讨论了数据存储和检索的关键步骤,例如多用户支持的检索器确认、链条配置字段的添加以及运用可配置字段来调用链条。最后,通过实际代码演示了在LangChain中实现多用户检索的方法。包括环境设置、文本嵌入、配置索引器与Chain的构建,以及通过特定命名空间对文档库进行隔离的测试结果。
背景
多用户环境下的数据检索,要求系统能够区分并管理不同用户的数据。这不仅涉及到数据安全性和隐私保护,还要求检索系统能够灵活应对不同用户的数据检索需求。假设有一家大型企业,拥有庞大的知识库系统,该系统存储了从市场分析到技术文档的各类信息。企业内部有多个部门,如研发、市场、人力资源等,每个部门对知识库的数据访问需求不同。为了保证信息安全,企业需要实现对数据的权限控制,确保每个部门只能访问对应的相关数据。
在这个业务场景中,最大的挑战是平衡数据安全和用户数据检索需求。具体问题包括:
数据权限管理:如何确保每个用户只能访问授权的数据?
检索系统的灵活性:如何设计一个既能保护数据安全,又能灵活响应不同用户检索需求的系统?
用户体验:如何在不泄露其他部门数据的前提下,提供快速准确的检索结果?
技术分析
LangChain是大模型应用框架,特别擅长处理检索任务,即从大量数据中找到与给定查询最相关的信息。在这篇文章中,我们将重点介绍如何在LangChain框架中实现多用户检索。那么,为了实现多用户检索不同数据,就需要解决数据存储和数据检索两个问题。
数据存储方面
在AI应用中,如推荐系统或语义搜索,需要处理和检索大量的高维向量数据。因此在处理大规模向量数据时会面临如下问题:
- 实时数据更新和查询延迟问题:AI应用需要快速反映数据的最新变更(如实时更新用户偏好)。许多系统难以在保证准确性的同时实现低延迟的数据更新和查询。
- 复杂的基础设施管理和成本:构建和维护用于存储和检索向量数据的基础设施通常复杂且成本高昂,尤其是在云环境下。
- 高维数据的存储和索引优化问题:存储密集或稀疏的向量嵌入,需要优化的存储结构和索引策略,以保持高效检索和存储性能。
- 多语言和多平台接入难题:AI应用开发者可能需要在不同的编程环境(如Python,Node.js)中处理向量数据,需要一个跨平台、易于使用的API。
为了解决上述问题,本例我们选用Pinecone。Pinecone是一个为AI应用设计的云原生向量数据库,提供简易API和自管理的基础设施。它专门处理高维向量数据,能够以低延迟处理数十亿向量的检索请求。向量嵌入作为其核心,代表语义信息,赋予AI应用长期记忆功能,使其能在执行复杂任务时利用以往经验。
与传统标量数据库相比,Pinecone提供了针对向量数据的优化存储和查询,解决了处理复杂向量数据的难题。它的索引包含独特ID和密集向量嵌入的浮点数数组,也支持稀疏向量嵌入和元数据键值对,用于混合搜索和过滤查询。Pinecone保证高性能、实时性,每个pod副本每秒可处理200个查询,反映最新数据更新。用户可通过HTTP、Python或Node.js进行增删改查操作,灵活处理向量数据。
数据检索方面
为了实现多用户检索需要执行如下关键步骤:
1. 多用户支持的检索器确认:检查使用的检索器是否支持多用户功能。目前LangChain没有统一的标识或过滤器来实现这一点,每个向量存储和检索器可能有自己的实现方式(如命名空间、多租户等)。通常,这通过在`similarity_search`时传递的关键字参数来暴露。因此,需要通过阅读文档或源代码来确定所用检索器是否支持多用户功能,以及如何使用它。
2. 为链条添加配置字段:在运行时调用链条并配置任何相关标志。查阅相关文档了解更多关于配置的信息。需要说明的是, “链条”(Chains)是LangChain的一个关键概念,它们是一系列处理步骤的集合,用于执行特定的任务。为了支持多用户检索,用户需要在链条中添加配置字段。这些字段允许在运行时动态调整链条的行为,以适应不同用户的需求。
3. 使用可配置字段调用链条:运行时,通过前面设置的可配置字段,可以实现对链条的个性化调用。这意味着用户可以根据不同的情境或用户需求,调整链条的行为。这一步是实现多用户检索的关键,它确保了检索结果能够根据不同用户的独特需求进行优化和调整。
上面三点需要索引支持多用户查询,用户查询数据的参数可以通过配置字段的方式传递给Chains,同时Chains 可以接受配置字段并且执行,完成数据检索的操作。
根据前面对Pinecone向量存储的描述,我们通过查阅LangChain 官方文档了解。
既然数据存储和数据检索的问题都得到了解决,下面就开始代码实践的环节。包langchain_community.vectorstores.pinecone.Pinecone 下面包含了as_retriever方法,该方法创建并返回一个VectorStoreRetriever对象,该对象从VectorStore初始化。这个检索器提供了多种搜索类型,使得用户可以根据不同需求进行定制化的向量数据检索。
该方法的关键参数如下:
search_type(可选字符串)定义:指定检索器执行的搜索类型。选项:"similarity":标准的相似度搜索,默认选项。"mmr":最大边缘相关性(Maximum Marginal Relevance),用于生成多样化的搜索结果。"similarity_score_threshold":设置相似度分数阈值,仅返回超过此阈值的文档。search_kwargs(可选字典)功能:提供给搜索函数的关键字参数。包含内容:k:返回的文档数量,默认为4。score_threshold:用于similarity_score_threshold的最小相关性阈值。fetch_k:传递给MMR算法的文档数量,默认为20。lambda_mult:MMR结果的多样性程度,从1(最小多样性)到0(最大多样性),默认为0.5。filter:基于文档元数据的过滤条件。返回值类型:VectorStoreRetriever功能:一个检索类,用于在VectorStore上执行数据检索操作。
代码实践
技术分析之后就需要分几个步骤进行代码实践,具体步骤如下:
Pinecone信息获取
首先需要注册Pinecone的账号,然后获取对应API Keys,在调用Pinecone服务的时候会用到它。注册Pinecone的过程比较简单,填写基本信息就可以完成,这里不再赘述。如下图所示,在用户控制台的“API Keys” 菜单中选择key对应的“复制”图标,从而复制“API Keys”留作备用。
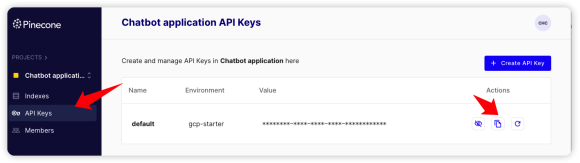
接着到“Indexes”页面去创建index,如下图所示,选择“Setup by model”。
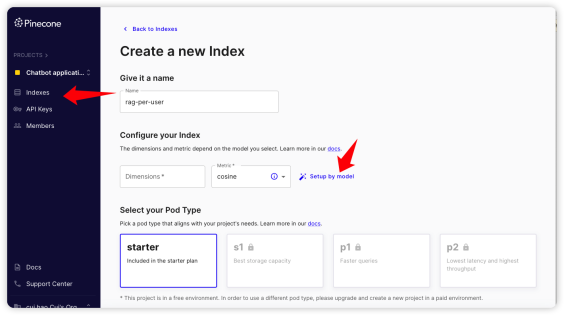
在弹出的对话框中,我们选择OpenAI 的embedding 作为index 的配置项。
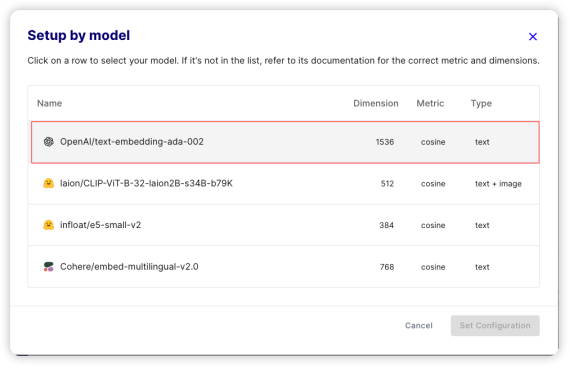
最终,如下图所示,点击“Create indexes” 按钮创建index。
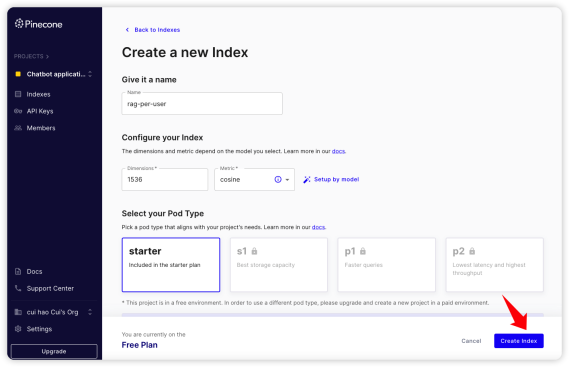
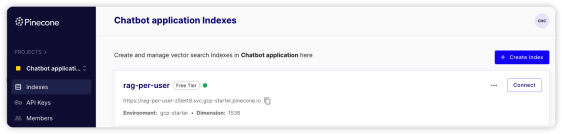
创建index 完成之后,可以通过下图看到对应的信息,其中“rag-per-user”是index的名字,gcp-starter作为环境的名字。这两个信息在初始化Pinecone的时候是需要的。
环境安装与参数配置
需要将代码需要的组件包安装好,通过如下命令实现安装:
!pip install openai langchain pinecone-client pypdf tiktoken -q -U
Openai:这是OpenAI提供的官方Python库,用于与OpenAI的API(如GPT和DALL-E等)进行交互。
Langchain:这个库可能是用于处理语言相关任务的。它可能包含了一些用于自然语言处理、机器翻译或其他语言技术的工具和模型。
pinecone-client:Pinecone是一个向量数据库,用于构建和部署大规模相似性搜索应用。pinecone-client 是其客户端库,用于与Pinecone服务进行交互。
Pypdf:这是一个Python库,用于处理PDF文件。它可能允许用户读取、写入、分割、合并和转换PDF文档。
Tiktoken:用来对文本进行分词。
接着再对一些参数进行赋值如下:
import osimport getpassos.environ["PINECONE_API_KEY"] = getpass.getpass("输入Pinecone key")os.environ["OPENAI_API_KEY"] = getpass.getpass("输入OpenAI Key")PINECONE_API_KEY=os.environ.get("PINECONE_API_KEY")PINECONE_ENVIRONMENT="gcp-starter"PINECONE_INDEX="rag-per-user"(1) 导入模块
import os: 导入 Python 的 os 模块,它提供了许多与操作系统交互的功能,包括管理环境变量。
import getpass:导入 getpass 模块,它用于安全地获取用户输入,而不在屏幕上显示输入(如密码或密钥)。
(2) 获取并设置环境变量
os.environ["PINECONE_API_KEY"] = getpass.getpass("输入Pinecone key"): 这行代码首先显示提示“输入Pinecone key”,然后等待用户输入 Pinecone 的 API 密钥。输入的内容不会在屏幕上显示。输入完成后,该密钥被设置为环境变量 PINECONE_API_KEY。
os.environ["OPENAI_API_KEY"] = getpass.getpass("输入OpenAI Key"): 同样,这行代码用于获取并设置 OpenAI 的 API 密钥作为环境变量 OPENAI_API_KEY。
(3) 读取环境变量
PINECONE_API_KEY = os.environ.get("PINECONE_API_KEY"):从环境变量中读取 PINECONE_API_KEY 的值,并将其赋给变量 PINECONE_API_KEY。如果该环境变量不存在,它将返回 None。
(4) 设置其他Pinecone相关的变量
PINECONE_ENVIRONMENT="gcp-starter":设置了一个字符串变量 PINECONE_ENVIRONMENT,其值为 "gcp-starter"。这通常用于指定 Pinecone 服务的运行环境。
PINECONE_INDEX="rag-per-user": 设置 PINECONE_INDEX 变量为 "rag-per-user",这个值通常用于指定在 Pinecone 中使用的特定索引。
整体上,这段代码的目的是安全地获取和存储与 Pinecone 和 OpenAI 服务相关的敏感信息(如 API 密钥),同时还设定了一些与 Pinecone 服务相关的配置变量。这样做可以在代码的其他部分安全地使用这些密钥和配置,而不必硬编码在代码中,从而增强了安全性和灵活性。
文本嵌入
接下来,使用 Pinecone 作为向量存储(Vector Store)和 OpenAI 作为嵌入生成器,用于搭建一个语言处理系统。
import pineconefrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain_community.chat_models import ChatOpenAIfrom langchain.vectorstores import Pineconepinecone.init(api_key=PINECONE_API_KEY, environment=PINECONE_ENVIRONMENT)index = pinecone.Index(PINECONE_INDEX)embeddings = OpenAIEmbeddings()vectorstore = Pinecone(index, embeddings, "text")vectorstore.add_texts(["我的工作职责是为用户提供产品方面的介绍。"], namespace="product-service")vectorstore.add_texts(["我的工作职责是为用户提供技术方面的支持。"], namespace="tech-service")from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import (ConfigurableField,RunnableBinding,RunnableLambda,RunnablePassthrough,)template = """基于如下信息回答问题:{context}Question: {question}"""prompt = ChatPromptTemplate.from_template(template)model = ChatOpenAI()retriever = vectorstore.as_retriever()代码解释如下:
(1) 导入所需模块和类
import pinecone: 导入 pinecone 模块,用于与 Pinecone 服务交互。
from langchain.embeddings.openai import OpenAIEmbeddings: 从 langchain 库中导入 OpenAIEmbeddings 类,用于生成文本嵌入(embeddings)。
from langchain_community.chat_models import ChatOpenAI: 导入 ChatOpenAI,这可能是用于处理聊天或问答类型任务的模型。
from langchain.vectorstores import Pinecone: 导入 Pinecone 类,用于在 Pinecone 服务上操作向量存储。
(2) 初始化 Pinecone 服务并创建索引
pinecone.init(api_key=PINECONE_API_KEY, envirnotallow=PINECONE_ENVIRONMENT): 使用提供的 API 密钥和环境变量初始化 Pinecone 服务。
index = pinecone.Index(PINECONE_INDEX): 创建或访问一个名为 PINECONE_INDEX 的 Pinecone 索引。
(3) 设置嵌入生成器和向量存储
embeddings = OpenAIEmbeddings(): 实例化 OpenAIEmbeddings 以生成文本嵌入。
vectorstore = Pinecone(index, embeddings, "text"): 创建一个 Pinecone 实例,用于存储和检索文本嵌入。这里使用了之前创建的 index 和 embeddings。
(4) 向量存储中添加文本
vectorstore.add_texts(["我的工作职责是为用户提供产品方面的介绍。"], namespace="product-service"): 将一段文本添加到向量存储中,用于表示“产品服务”相关的信息。
vectorstore.add_texts(["我的工作职责是为用户提供技术方面的支持。"], namespace="tech-service"): 将另一段文本添加到向量存储中,用于表示“技术服务”相关的信息。
(5) 设置输出解析器、提示模板和模型
导入了多个 langchain_core 中的类和函数,这些可能用于处理和解析语言模型的输出。
template = "..." 和 prompt = ChatPromptTemplate.from_template(template): 定义一个聊天提示模板,用于指导语言模型如何回答问题。
model = ChatOpenAI(): 实例化一个 ChatOpenAI 模型,可能用于处理聊天或问答任务。
retriever = vectorstore.as_retriever(): 将 vectorstore 转换为一个检索器(Retriever),用于从存储的嵌入中检索相关信息。
这段代码设置了一个基于 Pinecone 和 OpenAI 的语言处理系统,它能够存储和检索文本信息,并且使用特定的模型和模板处理聊天或问答类型的任务。
配置索引器与Chain
紧跟着,需要建立一个处理链(chain),使用配置的检索器(configurable_retriever),提示模板(Prompt),模型(Model),和输出解析器(StrOutputParser)。这个Chain 就是用来执行按照namespace 进行索引的。代码如下:
(1) 配置检索器
configurable_retriever = retriever.configurable_fields(...): 这行代码创建了一个可配置的检索器 configurable_retriever。它通过 ConfigurableField 定义一个可配置的字段 search_kwargs,该字段用于定义检索器的搜索参数(例如,如何从向量存储中检索数据)。
(2) 构建处理链
处理链由几个部分组成,通过 | 符号连接,表示数据将按顺序通过这些组件。
{"context": configurable_retriever, "question": RunnablePassthrough()}: 这是链的第一部分,包含两个输入:context 和 question。context 通过 configurable_retriever 获取,而 question 直接通过 RunnablePassthrough 传递,后者意味着问题(question)不进行任何处理就传递到链的下一个部分。
- prompt: 然后,输入数据传递到 prompt。这个ChatPromptTemplate 对象负责根据上下文和问题格式化提示,准备好交给语言模型处理。
- model: 接下来,格式化好的提示传递给 model,这里的 model 是 ChatOpenAI 实例,它会根据提供的提示生成回答。
- StrOutputParser(): 最后,模型的输出传递给StrOutputParser,这个解析器将模型的输出转换成字符串形式。
整体来看,这个处理链的作用是:根据检索到的上下文和未处理的问题生成一个格式化的提示,然后使用 ChatOpenAI 模型来生成回答,并将这个回答转换为字符串。这种方式非常适合于问答系统,其中上下文信息是根据需要动态检索的,而问题直接传递给模型以生成答案。
测试结果
创建好Chain之后,我们来尝试对其提出问题,由于我们之前定义了不同namespace对应的工作职责。这里我们就直接询问工作职责的问题,首先测试product-service 这个namespace,看看它返回什么答案。
chain.invoke("你的工作职责是什么?",config={"configurable": {"search_kwargs": {"namespace": "product-service"}}},)结果如下:
我的工作职责是为用户提供产品方面的介绍。
结果和我们预期一致,product-service 这个namespace 确实是用来处理产品方面的问题的。
接着再测试tech-service 这个namespace的回答。
chain.invoke("你的工作职责是什么?",config={"configurable": {"search_kwargs": {"namespace": "tech-service"}}},)结果如下:
我的工作职责是为用户提供技术方面的支持。
看来返回结果也是正确的。
文档库隔离
上面通过在不同的namespace 中加入不同的text文本信息,让不同用户通过访问不同的namespace 来做到“知识”内容的隔离。但是,真实的应用场景是针对不同的namespace上传不同的文档,当我们提问的时候需要制定namespace,来确定由哪个文档来回应消息。
于是,我们针对product-service 和tech-service 两个不同的namespace 上传两个不同的文档,分别是product-service.pdf 和 tech-service.pdf。两个文档的内容如下:
product-service.pdf 是一个产品服务知识库,采用问答形式。它提供了关于客户服务的具体指导,特别是关于退货政策的细节。
产品服务知识库(问答形式) 问:如果客户询问关于退货政策的具体细节,我们应该如何回答? 答:⾸先,礼貌地感谢客户对产品的购买。然后, 详细解释我们的退货政策:客户可以在购买后的30 天内⽆条件退货,产品必须保持原始状态且包装完整。提醒客户保留收据,因为这是退货的必要凭证。 最后,告知客户退货流程,并提供相关表格和联系信息。
tech-service.pdf 是一个技术服务知识库,同样采用问答形式。它主要提供了关于技术问题解决方案的指导,特别是针对智能锁失灵的问题。
技术服务知识库(问答形式) 问:客户如何解决智能锁频繁失灵的问题? 答:⾸先,指导客户检查智能锁的电源和电池状态,确认电量是否充⾜。如果电量正常,请引导客户重置智能锁,具体⽅法是⻓按重置键 5 秒钟。如果问题仍然存在,请建议客户检查智能锁的软件版本是否最新,并引导进⾏系统更新。若以上步骤⽆法解决问题,建议客户联系技术⽀持以获取进⼀步的帮助。
有了文档之后,我们就需要将其上传并且嵌入到向量库Pinecone中, 代码如下:
from langchain.document_loaders import PyPDFLoaderfrom google.colab import drivedrive.mount('/content/drive')file_path = '/content/drive/My Drive/files/product-service.pdf'loader = PyPDFLoader(file_path)documents = loader.load_and_split()vectorstore.add_documents(documents, namespace="product-service")file_path = '/content/drive/My Drive/files/tech-service.pdf'loader = PyPDFLoader(file_path)documents = loader.load_and_split()vectorstore.add_documents(documents, namespace="tech-service")由于我使用的是colab 环境,所以这段代码是关于如何在 Google Colab 环境中加载 PDF 文件并将它们的内容添加到一个向量存储(vector store)中。下面是对代码的详细解释:
(1) **导入所需模块和类**
- `from langchain.document_loaders import PyPDFLoader`: 导入 `PyPDFLoader` 类,这个类用于加载 PDF 文件并将其内容转换为可处理的文档格式。
- `from google.colab import drive`: 导入用于在 Google Colab 环境中挂载 Google Drive 的模块。
(2) **挂载 Google Drive**
- `drive.mount('/content/drive')`: 这行代码将 Google Drive 挂载到 Colab 的文件系统中。这使得在 Colab 中可以直接访问存储在 Google Drive 中的文件。
(3) **加载并处理第一个 PDF 文件**
- `file_path = '/content/drive/My Drive/files/product-service.pdf'`: 设置第一个 PDF 文件的路径。
- `loader = PyPDFLoader(file_path)`: 创建 `PyPDFLoader` 实例并传入文件路径,准备加载文件。
- `documents = loader.load_and_split()`: 使用 `load_and_split` 方法加载 PDF 文件并将其内容分割成单独的文档。这些文档通常是 PDF 的每一页或者每个段落。
(4) **将文档添加到向量存储**
- `vectorstore.add_documents(documents, namespace="product-service")`: 将从 PDF 文件中加载的文档添加到向量存储中,指定命名空间为 "product-service"。
(5) **重复以上步骤加载第二个 PDF 文件**
- 设置第二个 PDF 文件 `tech-service.pdf` 的路径。
- 再次创建 `PyPDFLoader` 实例,加载第二个文件。
- 将从第二个文件中加载的文档添加到向量存储中,这次指定命名空间为 "tech-service"。
整体来看,这段代码的目的是将两个 PDF 文件(分别关于产品服务和技术服务的知识库)的内容加载到一个向量存储系统中,可能用于后续的搜索或检索任务。通过将文件内容分割成单独的文档,并使用命名空间区分不同的文件内容,代码有效地组织了信息,便于后续处理。
既然PDF文档已经嵌入了,接下来就是重头戏了。我们定义了一个名为ask_question 的函数,它使用一系列处理步骤(即一个处理链)来根据给定的问题和命名空间从一个向量存储中检索并回答问题。代码如下:
from langchain.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughdef ask_question(question, namespace):retriever = vectorstore.as_retriever()template = """基于如下的上下文内容进行回答[CONTEXT][/CONTEXT]:[CONTEXT]{context}[/CONTEXT]如果你不知道答案,你就回答:我不知道。Question: {question}"""prompt = ChatPromptTemplate.from_template(template)model = ChatOpenAI() configurable_retriever = retriever.configurable_fields(search_kwargs=ConfigurableField(,name="Search Kwargs",description="The search kwargs to use",))chain = ({"context": configurable_retriever, "question": RunnablePassthrough()}| prompt| model| StrOutputParser())response = chain.invoke(question,config={"configurable": {"search_kwargs": {"namespace": namespace}}},)print(response)代码解释如下:
(1) 导入所需模块和类
导入 ChatPromptTemplate,StrOutputParser,RunnablePassthrough 等类,这些类用于处理和解析语言模型的输出。
(2) 定义 ask_question 函数
def ask_question(question, namespace): 定义一个函数,接受两个参数:question(要问的问题)和 namespace(用于指定搜索的命名空间,可能代表不同类型的知识库)。
(3) 设置检索器和提示模板
retriever = vectorstore.as_retriever(): 获取向量存储的检索器。
template = """...""": 定义一个聊天提示模板,该模板指定如何格式化问题和上下文。需要特别注意的是,这里设计的prompt template 为“如果你不知道答案,你就回答:我不知道。”这是在告诉大模型,如果不能从知识库中获取答案,就如实回答“不知道”,不要试图去编造答案。
prompt = ChatPromptTemplate.from_template(template): 使用上述模板创建一个 ChatPromptTemplate 实例。
(4) 配置检索器
configurable_retriever = retriever.configurable_fields(...): 创建一个可配置的检索器,它允许调整搜索参数(如命名空间)。
(5) 构建处理链
chain = (...): 创建一个处理链,它包括以下部分:
将 configurable_retriever 和 RunnablePassthrough 作为输入,前者用于获取上下文,后者直接传递问题。
使用 prompt 来格式化输入。
model(这里是 ChatOpenAI 实例)用于生成回答。
StrOutputParser 将模型的输出转换为字符串。
(6) 调用处理链并打印响应
response = chain.invoke(...): 使用 invoke 方法调用处理链,并传入问题和配置(包括指定的命名空间)。
print(response): 打印出生成的响应。
该函数利用一个配置好的处理链来自动回答问题。它从指定命名空间的向量存储中检索相关上下文,然后使用这些上下文和提供的问题生成一个合适的回答。这对于基于特定知识库自动回答用户问题的场景非常有用。
最后,我们来看运行结果。
执行如下语句:
ask_question("退货政策", "product-service")传入提出的问题,以及对应的namespace。由于之前PDF文件中就对退货政策进行了描述,现在就通过product-service 这个namespace 搜索与之相关的内容。得到如下结果:
答:客户可以在购买后的30天内无条件退货,产品必须保持原始状态且包装完整。请提醒客户保留收据,因为这是退货的必要凭证。退货流程和相关表格以及联系信息可以提供给客户。
从结果上看与PDF文档中的内容保持一致。
接着,我们再提问“智能锁失灵”的问题,这里我们不向“tech-service”提问,而向“product-service”提问。显然,product-service的namespace 存放的文档是关于产品服务相关的,并不知道“智能锁失灵”这样的技术支持问题。所以,先执行代码再看结果,代码如下:
我不知道。
很显然结果是“我不知道”,通过上面prompt template 的定义,我们让大模型在没有搜索到文档内容的时候,不要编造任何信息,而是如实回答:“我不知道”。这也证明了在product-service的namespace中不存在与技术支持相关的信息。
最后,我们通过如下代码询问 tech-service,
ask_question("智能锁失灵", "tech-service")看结果如下:
回答:首先,指导客户检查智能锁的电源和电池状态,确认电量是否充足。如果电量正常,请引导客户重置智能锁,具体方法是长按重置键5秒钟。如果问题仍然存在,请建议客户检查智能锁的软件版本是否最新,并引导进行系统更新。若以上步骤无法解决问题,建议客户联系技术支持以获取进一步的帮助。
从结果上看,与我们的设想相同,和技术支持相关的问题从tech-service 的namespace中获取。
总结
文章提供了一种有效的方法可以在LangChain框架下实现多用户数据检索,确保了数据安全性和隐私保护的同时,也保证了检索系统的灵活性和用户体验。通过使用Pinecone作为向量数据库,它克服了传统标量数据库在处理高维向量数据时遇到的难题。文章详细介绍了多用户检索的实现步骤,从检索器的配置到链条的构建,再到实际的代码演示,全面覆盖了从理论到实践的各个方面。通过提供具体的示例和代码,文档使读者能够更容易地理解和应用这些概念到实际的多用户检索任务中。
作者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 币圈做空怎么操作
- 做空是一种预测市场下跌的金融策略,包括借入资产、卖出资产,并在价格下跌时回购资产以获利。币圈做空步骤包括:选择交易所,开设账户,借入资产,卖出资产,市场下跌,回购资产,返还资产,计算利润。
- 6分钟前 0
-
 正版软件
正版软件
- 薄饼交易所卖不出去怎么办
- 当薄饼交易所中无法出售薄饼时,投资者可以采取以下解决办法:1.降低价格;2.提高流动性;3.寻找场外交易(OTC)市场;4.细分市场;5.调整营销策略;6.耐心等待。研究市场并咨询专业人士对于做出明智决定至关重要。
- 21分钟前 0
-
 正版软件
正版软件
- 热衷炒币的韩国7月底决定虚拟资产税法何时执行!会影响市场吗
- 本站(120bTC.coM):韩国政府在2022年年底的税制修定计划中,决定将虚拟资产税的实施时间延后至2025年1月。而据韩国媒体今(21)日报导,韩国财政部已经开始审查虚拟资产税法,并会在下个月底公布《税法修正案》前,决定是否如期实施。早前,韩国财政部长兼副总理崔尚木17日在政府世宗办公室受访时表示:在税法修改案制定之前我们还有时间,所以我们会考虑(推迟虚拟资产税实施)虚拟资产税制度尚不完善此前原定于2022年实施的虚拟资产税,由于税务机关、和虚拟资产交易所相关系统尚未准备就绪,已被延期两次。主要原因
- 36分钟前 虚拟货币 比特币听证会 虚拟货币交易 欧洲杯概念币 0
-
正版软件
- 什么是WEB3钱包
- Web3钱包是一种数字钱包,用于管理和存储加密货币和数字资产,特点是非托管、多链支持、DApp兼容、智能合约交互和安全存储。工作原理是连接到区块链网络,生成公钥和私钥,通过签名授权交易。
- 56分钟前 0
-
 正版软件
正版软件
- 深蓝S07月底有望上市,现已开放预定:全系标配后驱,综合续航突破1200km
- 7月16日消息,深蓝汽车今日不仅详细披露了旗下新款车型S07的核心配置,更宣布该车型已正式开启“先享抢订”活动。消费者只需支付520元意向金,即可享受“免费赠送价值2399元隔热膜”的特惠,此举也被视为该车可能在本月底正式登陆市场的强烈信号。1.设计理念:深蓝S07延续家族式造型风格,提供星耀黑、冷星白等七种丰富配色。前脸设计:封闭式前格栅搭配时尚的贯穿式LED灯组,展现独特美感。尾部设计:顶置单点式刹车灯搭配动感的黑色下包围,营造运动氛围。据小编了解,深蓝S07的尺寸数据已公布:长宽高:4750mmx1
- 1小时前 23:14 0
最新发布
-
 1
1
- 阿里追捧的中台,“热度”退了?
- 1982天前
-
 2
2
- Overture设置踏板标记的方法
- 1819天前
-
 3
3
- 思杰马克丁取得CleanMyMac中国区独家发行授权
- 1809天前
-
 4
4
- IBM:20万台Mac让公司职工在工作中更快乐 更多产
- 2008天前
-
 5
5
- 报道称微软一直在悄然游说反对“维修权”立法!
- 1973天前
-
 6
6
- 美国怀疑华为窃取商业机密 华为:身正不怕影子斜
- 1969天前
-
 7
7
- 三星被曝正与联发科接洽 A系列手机有望搭载其5G芯片
- 1984天前
-
 8
8
- 环球墨非完成千万级融资 联合企业集团投资
- 2006天前
-
 9
9
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00