使用小型自动生成的数据集训练LLM编码的方法
 发布于2024-12-08 阅读(0)
发布于2024-12-08 阅读(0)
扫一扫,手机访问
译者 | 李睿
审校 | 重楼
尽管像GPT-4这样的大型语言模型(LLM)在软件编写方面表现出色,但是其高昂的成本和不透明性已经引发了人们对更经济实惠、规模更小的编码LLM的关注。

针对特定任务进行微调的替代方案可以有效降低成本。LLM的开发面临的主要挑战之一是在训练数据集的规模和模型性能之间取得最佳平衡。
为了应对这一挑战,微软公司最近发表的一篇论文介绍了一项新技术,该技术能够通过使用更少的示例训练高效的编码语言模型。该论文详细介绍了WaveCoder模型,并声称该模型在类似数量的示例上训练时要优于其他编码LLM模型。
为了补充WaveCoder,微软公司还推出了CodeOcean,这是一个涵盖2万个不同代码示例的优选数据集。这个数据集有助于进一步微调编码应用的基础模型。
选择正确的编码示例
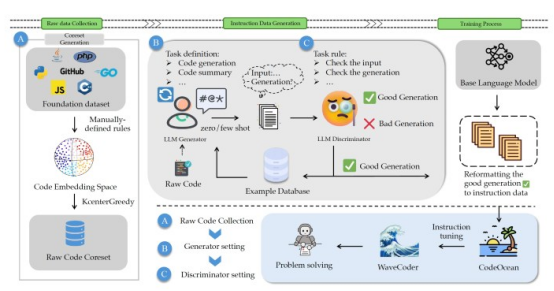 图1 CodeOcean管道
图1 CodeOcean管道
尽管WaveCoder作为LLM模型令人印象深刻,但在这篇论文中,更让人感兴趣的部分是CodeOcean,它提供了一个附带的数据集。CodeOcean的出现解决了一个重要挑战:如何创建一个在成本效益和质量方面保持平衡的数据集。研究人员认为,具有最大多样性的数据集可以产生引人注目的结果,即使数据集中的示例数量有限。
该研究团队从CodeSearchNet开始,这是一个包含200万对注释和代码的广泛编码数据集。他们使用基于BERT的Transformer模型为每个示例生成嵌入,将复杂信息转换为数字列表。
他们对嵌入应用了一种聚类算法,根据它们的相似性对示例进行排序。这种方法使研究人员能够从原始数据集中提取一个子集,最大限度地提高多样性。
添加说明
在建立核心数据集之后,研究人员必须创建包含代码和指令的训练示例。为了实现这一点,他们创建了一个生成器-鉴别器框架,用于根据原始代码示例生成指导性数据。最初,他们使用GPT-4在特定的场景中制作任务定义。这些初始任务定义与指导提示相结合,被提供给GPT-3.5,以生成额外示例的相应指令。
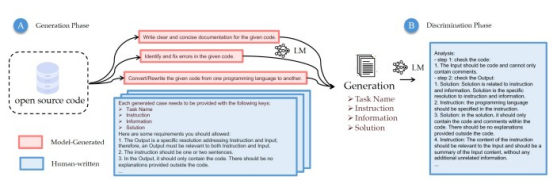 图2 CodeOcean的生成器-鉴别器框架
图2 CodeOcean的生成器-鉴别器框架
对于鉴别器组件,研究人员制定了一个单独的评估提示。这个提示以及代码和指令示例提供给GPT-4进行评估。然后,CodeOcean管道使用良好的示例来生成未来的训练示例。
研究人员通过这个迭代过程生成了2万个高质量的教学样本。这些示例跨越了四个不同的编码任务类别:代码生成、代码摘要、语言翻译(从一种编程语言到另一种编程语言)和代码修复。这四个类别包含了LLM编码任务的很大一部分。
训练WaveCoder
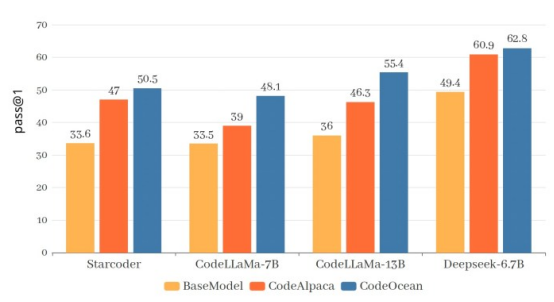 图3 WaveCoder优于其他在类似数量的示例上训练的编码LLM
图3 WaveCoder优于其他在类似数量的示例上训练的编码LLM
生成用于编码LLM的训练示例有很多方法。但微软的CodeOcean以强调泛化和示例效率而与众不同。与依赖大量数据的研究不同,CodeOcean可以使用较小的数据集实现高性能。
为了证明CodeOcean的有效性,研究人员对三种编码语言模型进行了微调:StarCoder-15B、CodeLLaMA(7B和13B)和DeepseekCoder-6.7B。考虑到数据集的大小,其微调既快速又经济高效。研究人员根据HumanEval、MBPP和HumanEvalPack这三个关键的编码基准对微调后的模型进行了评估。
通过在CodeOcean上进行多次训练,所有模型在这些基准测试上都有了显著的改进。在代码生成方面,研究人员描述了WaveCoder的影响和局限性:“在微调过程之后,与基础模型和一些开源模型相比,WaveCoder模型的性能有了显著的提高,但它仍然落后于专有模型(例如GPT-4和Gemini),以及使用7万多个训练数据训练的指示模型。”
WaveCoder和WizardCoder之间的性能差异很小,有78000个训练示例。这表明“精细化和多样化的指令数据可以显著提高指令调优的效率。”
WaveCoder在代码摘要和修复任务方面尤为出色。它在几乎所有编程语言上的表现都优于其他开源模型。这一成功强调了“定义和分类代码相关任务对增强代码LLM泛化能力的有效性”。
虽然微软公司尚未发布WaveCoder和CodeOcean的模型、代码和数据,但有关Hugging Face的讨论表明,该公司正在审查是否将它们对外发布。展望未来,研究人员的目标是探索更大数据集的效果,以及将CodeOcean与其他编码数据集相结合的潜在好处。
原文标题:How to train coding LLMs with small auto-generated datasets,作者:Ben Dickson
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- waxp币2024年有潜力吗
- WAXP币在2024年潜力巨大:市场规模庞大,预计不断增长。基于EOSIO平台,具有高吞吐量、低费用和可扩展性优势。专注于数字收藏品和NFT交易,提供专门的支持。建立了与福特汽车等行业领先公司的战略合作伙伴关系。团队积极应对挑战,寻求创新以保持竞争力。
- 15分钟前 0
-
 正版软件
正版软件
- 柚子币是干嘛的
- 柚子币(EOS)的主要用途包括:平台治理、交易费用、抵押资产、节点奖励以及dApp开发。它还可用作交换媒介、价值存储和参与去中心化融资。
- 25分钟前 0
-
 正版软件
正版软件
- usdt币交易有哪些平台
- USDT币交易平台USDT币交易平台允许用户买卖与美元挂钩的稳定币USDT。流行的交易所包括:币安火币OKXBitMEXKraken选择平台时应考虑:安全和信誉加密货币对费用法币支持客户服务
- 40分钟前 0
-
 正版软件
正版软件
- etc币和ltc币哪个好
- ETC币和LTC币没有绝对的"更好"之说,两种货币各有优劣。技术基础:ETC是以太坊经典,LTC则基于比特币。交易速度:LTC胜过ETC,每秒可处理56笔交易。费用:ETC和LTC均相对较低,但LTC费用更低。功能:ETC提供智能合约,LTC侧重点对点支付。优势:ETC社区支持强,LTC交易速度快,费用低廉。适合人群:ETC适合重视社区和开发的人,LTC则更
- 1小时前 22:20 0
-
 正版软件
正版软件
- 韩国虚拟币交易所排名
- 韩国虚拟货币交易所排名:1.Bithumb(最大交易量、市场份额超50%);2.Upbit(种类多、安全技术先进);3.Korbit(比特币交易为主,合规性强);4.Coinone(品种丰富,验证措施严格);5.GDAC(费用低廉,用户友好)。
- 1小时前 22:10 0













