mysql去重查询的方法有哪些
 发布于2023-04-27 阅读(0)
发布于2023-04-27 阅读(0)
扫一扫,手机访问
一、插入测试数据
下图测试数据中user_name为lilei、zhaofeng的用户是重复数据。
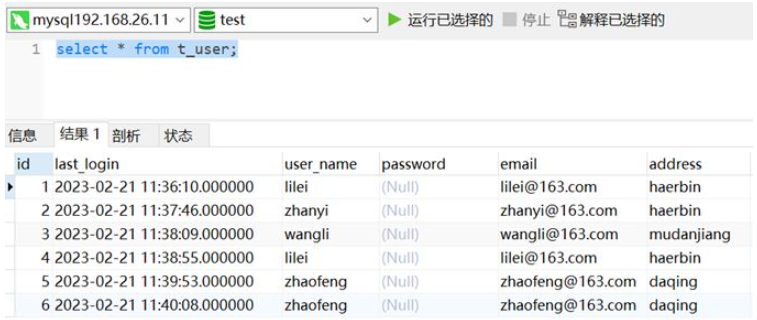
二、剔除重复数据方法
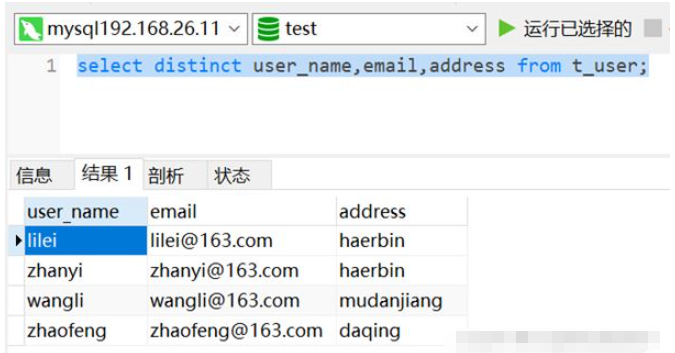
1.方法一:使用distinct
代码如下(示例):
select distinct user_name,email,address from t_user;
如下图,已将数据剔重,重复数据仅保留1条。
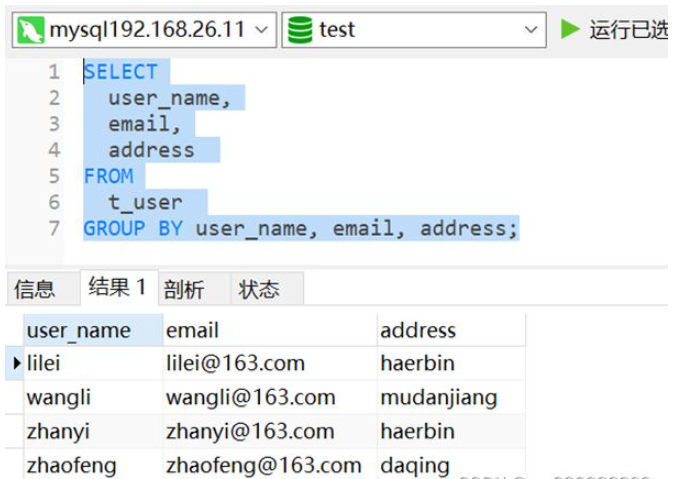
2.方法二:使用group by
SELECT user_name,email,address FROM t_user GROUP BY user_name, email, address;
如下图,已将数据剔重,重复数据仅保留1条。
3.方法三:使用开窗函数
(1)如果你的数据库是MySQL8以上版本你可以直接使用开窗函数row_number()
SELECT * FROM( SELECT t.*, ROW_NUMBER() OVER(PARTITION BY user_name ORDER BY last_login DESC) rn FROM table AS t ) AS t_user WHERE rn = 1;
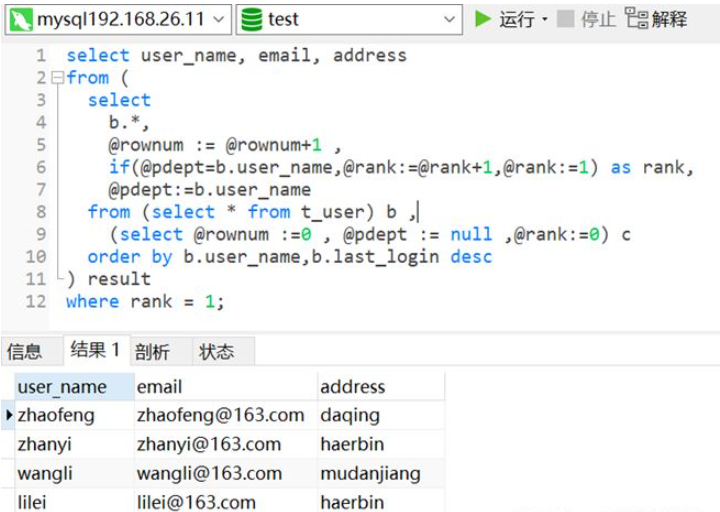
(2)如果你的数据库版本低于MySQL8,使用类row_number()方法
select user_name, email, address from ( select b.*, @rownum := @rownum+1 ,-- 定义用户变量@rownum来记录数据的行号 if(@pdept=b.user_name,@rank:=@rank+1,@rank:=1) as rank,-- 如果当前分组user_name和上一次分组user_name相同,则@rank(对每一组的数据进行编号)值加1,否则表示为新的分组,从1开始 @pdept:=b.user_name -- 定义变量@pdept用来保存上一次的分组id from (select * from t_user) b , (select @rownum :=0 , @pdept := null ,@rank:=0) c -- 初始化自定义变量值 order by b.user_name,b.last_login desc -- 该排序必须,否则结果会不对 ) result where rank = 1;
如下图,已将数据剔重,重复数据仅保留1条。
本文转载于:https://www.yisu.com/zixun/777113.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- UC浏览器隐藏功能在哪里?uc浏览器隐藏用法教程
- 还在纠结UC浏览器隐藏功能有哪些?莫慌,小编为你送上最详尽的UC浏览器隐藏用法教程,带你轻松玩转UC浏览器!uc浏览器隐藏用法教程1、打开UC智能组件!有超多方便大家快乐冲浪滴组件可以添加和开启!2、模式组件里有很多实用功能最推荐阅读模式啦!
- 1小时前 13:22 0
-
 正版软件
正版软件
- 王者营地怎么qq和微信一起玩?王者荣耀王者营地跨区组队操作教程
- 王者营地怎么qq和微信一起玩?众所周知,《王者荣耀》作为腾讯旗下的一款大型竞技类游戏网,支持微信和QQ登录,但是两者并不互通,在游戏登陆界面就可以看见,QQ登陆和微信登陆是完全两个不同的入口。因此很多玩家为了跟不同的好友一起玩,不得不开两个号。
- 1小时前 13:10 0
-
 正版软件
正版软件
- 支付宝怎么加好友?支付宝加好友的流程教程
- 支付宝怎么加好友?支付宝相信大家都用吧,支付宝的好友转账大家应该也会平时用到,那如果没有好友要怎么进行转账呢,那当然是先加好友了,接下来小编将给大家带来支付宝添加好友的方法教程,一起往下看看吧!支付宝加好友的流程教程1、首先进入支付宝首页后,点击下方导航栏中的消息选项2、在消息页面中,点击右上角的加号标志3、在加号标志选项中找到添加好友并点击4、进入添加好友页面
- 2小时前 12:27 0
-
 正版软件
正版软件
- 支付宝怎么转账到别人银行卡?支付宝转账到别人银行卡方法教程
- 支付宝怎么转账到别人银行卡?支付宝是我们最常用的支付工具,用户在使用的时候经常会用到转账功能,相信很多小伙伴把钱转到自己银行卡的方法都会,那么怎么转账到别人的银行卡呢?还不清除的小伙伴快跟随小编一起来看看吧。
- 2小时前 12:17 0
-
 正版软件
正版软件
- 支付宝如何关闭免密支付?支付宝关闭免密支付方法教程
- 支付宝如何关闭免密支付?虽然支付宝免密支付让我们的生活变得更加便捷,但是在某些时候也会带来不必要的麻烦,如果你不小心将手机遗失或者被盗,那么可能会导致支付宝被人恶意盗刷,所以有时候关闭支付宝免密支付也显得尤为重要,下面小编就给大家带来了支付宝关闭免密支付的方法教程,希望能帮到大家。
- 2小时前 12:06 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 198天前
-
4
- 探析Spring Boot框架的优点和特色
- 514天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 452天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 428天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1060天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 888天前
-
 9
9
- 解决Python安装失败的问题
- 438天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00