DeepSeek开源第三弹:高效FP8 GEMM库登场
 发布于2025-09-10 阅读(0)
发布于2025-09-10 阅读(0)
扫一扫,手机访问
2025 年 2 月 26 日,在开源周的第三天,DeepSeek 正式推出了其高效的 FP8 通用矩阵乘法(GEMM)库 —— DeepGEMM。该库不仅支持密集矩阵运算,还兼容混合专家(MoE)架构的 GEMM 操作,为 V3/R1 模型的训练与推理提供了强大助力。尤为引人注目的是,DeepGEMM 的核心代码仅约 300 行,却展现出卓越的性能表现。

为何需要 DeepGEMM?
在大规模模型的训练与推理中,矩阵乘法(GEMM,General Matrix Multiplications)是最关键的计算操作之一,尤其在深度学习过程中占据了大量计算资源。随着模型规模的不断扩展,特别是混合专家模型(MoE)的广泛应用,传统 GEMM 实现已难以满足高效计算的需求。MoE 模型通过动态激活部分专家来提升模型容量,但也带来了稀疏性和动态性的问题,使传统的密集矩阵乘法难以高效处理。
此外,低精度计算(如 FP8)在深度学习中的应用日益广泛,因其能够在降低内存消耗的同时维持较高的计算效率。然而,现有 GEMM 库对 FP8 的支持仍较为有限,特别是在 MoE 场景下,缺乏专门优化。DeepGEMM 的推出正是为了应对上述挑战,它实现了高效的 FP8 矩阵乘法,并同时支持密集和 MoE 两种模式,显著提升了大模型训练与推理的效率。
DeepGEMM 的主要特点
- 高性能:在 NVIDIA Hopper GPU 上,DeepGEMM 的 FP8 计算性能超过 1350 TFLOPS,内存带宽峰值达到 2668 GB/s。
- FP8 支持:作为首个专为 Hopper GPU 优化的 FP8 GEMM 库,DeepGEMM 能够有效减少内存占用并加速模型训练与推理过程。
- 简洁而强大的实现:尽管核心代码仅约 300 行,但其性能超越了许多专家级优化内核,这得益于团队在算法设计上的精妙构思及对 GPU 架构特性的深入理解。
- 即时编译(JIT):采用轻量级 JIT 模块,可根据硬件配置和输入尺寸在运行时动态生成高度优化的代码,从而进一步提升性能。
- 支持密集与 MoE GEMM:不仅适用于传统密集矩阵乘法,还特别针对 MoE 模型中的 GEMM 运算进行了优化,满足多样化的模型计算需求。
DeepGEMM 的性能表现
DeepSeek 团队在 H800 GPU 上使用 NVCC 12.8 对 DeepGEMM 进行了全面测试,涵盖了 DeepSeek-V3/R1 推理中可能涉及的各种矩阵形状(包括预填充和解码阶段,但不包含张量并行)。测试结果表明,DeepGEMM 的计算性能最高可达 1358 TFLOPS,内存带宽峰值达 2668 GB/s。相比基于 CUTLASS 3.6 的优化实现,性能提升幅度最高达 2.7 倍;在 MoE 模型下的分组 GEMM(连续性布局和掩码布局)中,性能提升也超过 1.2 倍。
总结
DeepGEMM 的发布标志着 DeepSeek 在高效矩阵乘法计算领域取得了又一重要突破。该库不仅支持 FP8 低精度计算,还对 MoE 模型进行了深度优化,大幅提升了大模型训练与推理的效率。未来,DeepSeek 还将带来哪些令人期待的开源项目?让我们共同关注其在开源道路上的更多精彩表现。
参考资料
deepseek-ai/DeepGEMM:https://github.com/deepseek-ai/DeepGEMM
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 驰声听说在线教师端app用什么登录-登录方式
- 驰声听说在线教师端app用什么登录,用户在本站下载安装好软件,点击手机桌面图标,打开app,然后填写用户名和密码,再认真查看下方的条款并同意之后就可以点击登录了。驰声听说在
- 10小时前 21:22 0
-
 正版软件
正版软件
- 驰声听说在线教师端app有什么功能-使用指南
- 驰声听说在线教师端app有什么功能,首先用户需要在本站下载提供的app,然后点开app进入首页,想要使用的话需要先注册,无学校班级的用户可以选择自由注册,进入app首页,可以加入班级,选择智能练习,同
- 10小时前 21:20 0
-
 正版软件
正版软件
- 驰声听说app怎么录音-录音教程
- 驰声听说app怎么录音,首先用户需要点击其中的提分功能,点击其中的音标学习功能,点击其中你需要录音的单元,点击其中的话筒按钮就能完成录音了。驰声听说app录音教程:
- 10小时前 21:17 0
-
 正版软件
正版软件
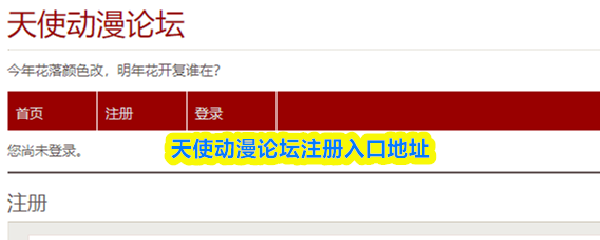
- 天使动漫论坛怎么注册-天使动漫论坛注册入口地址
- 天使动漫论坛可通过网页注册(地址https://www.wzw131.com/6city/bbs/register.php)或官方App完成。注册后需在验证申请版块提交申请以获得完整权限。若收不到验证
- 10小时前 21:14 0
-
 正版软件
正版软件
- 驰声听说app怎么收费-收费详细介绍
- 驰声听说app怎么收费,用户在本站下载安装好软件,点击手机桌面图标,打开app,首先用户需要点击右下方的我的功能,点击其中的续费功能,其中所有的价格就是软件的收费标准了。驰
- 10小时前 21:12 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 214天前
-
 2
2
- 高德地图是哪个国家开发的?
- 270天前
-
 3
3
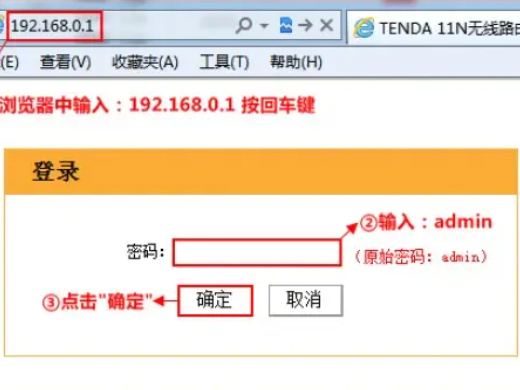
- 如何找到192.168.0.1登录入口
- 324天前
-
 4
4
- 拷贝漫画最新官网入口2025
- 103天前
-
 5
5
- yy漫画下拉式免费阅读官网入口
- 193天前
-
 6
6
- 2020美团外卖账单报告入口详解
- 212天前
-
 7
7
- 51漫画高清入口及最新章节更新
- 63天前
-
 8
8
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 231天前
-
 9
9
- 动漫共和国官网入口在线看
- 195天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00