Python爬取中国院士信息,揭秘人才聚集地
 发布于2025-09-30 阅读(0)
发布于2025-09-30 阅读(0)
扫一扫,手机访问
院士(Academician)一词源自古希腊传说中的英雄Academy,这位英雄为了拯救雅典而牺牲,是科学及学术界的最高荣誉头衔。要了解中国院士的分布情况,我们可以借助Python爬虫来获取详细信息。
背景调研
目前,中国院士总数超过1500人,其中科学院院士799人,工程院院士875人。
- 科学院院士名单:http://www.casad.cas.cn/chnl/371/index.html
- 工程院院士名单:http://www.cae.cn/cae/html/main/col48/column_48_1.html
本文将以工程院院士信息的抓取为例进行详细讲解。
工程院士出生地分布图

必备模块
通过pip安装以下模块:
- scrapy爬虫框架模块
- jieba分词模块
- win32api
如果遇到ImportError: DLL load failed: 找不到指定的模块错误,请将D:\Python27_64\Lib\site-packages\pywin32_system32下的所有文件复制到C:\Windows\System32目录下。
爬虫流程
建立爬虫项目:在E盘下创建
project_scrapy文件夹,进入该文件夹并打开cmd窗口,运行以下命令搭建爬虫框架:scrapy startproject engaca_spider
目录树如下:
E:\project_scrapy>tree /f
设置输出内容:在
items.py中添加如下内容:# -*- coding: utf-8 -*-
在
settings.py中设置爬虫源头,添加以下语句:starturl = 'http://www.cae.cn/cae/html/main/col48/column_48_1.html'
省份列表文件:在
scrapy.cfg的同层文件夹中存放pro_list.txt文件。链接:https://pan.baidu.com/s/1brg0MIz,密码:selo爬虫核心代码:在
spiders文件夹下创建aca_spider.py文件,添加以下代码:# -*- coding: utf-8 -*-
结果输出代码:在
pipelines.py中处理输出内容,可以将内容保存到数据库或文本文件中。这里直接保存到result.txt中:# -*- coding: utf-8 -*-
在
settings.py中指定输出管道:ITEM_PIPELINES = { # ... }运行爬虫:在
scrapy.cfg的同层文件夹下打开cmd窗口,运行以下命令:scrapy crawl EngAca
结果文件
result.txt将生成在该目录下。
数据可视化
利用pycharts进行数据可视化,参照教程绘制地图热图。根据生成的热图,我们可以看出,江苏省的院士数量最多,超过100人,确确实实是一个人杰地灵的地方。
项目所有文件
所有项目文件的链接:https://pan.baidu.com/s/1smligBN,密码:jdst
总结
这是一个基础且重要的爬虫练习,涉及到的内容没有JS加密和反爬措施。通过这个练习,可以熟悉爬虫框架的使用。数据预测未来,掌握这些技能可以让我们在做事时先人一步。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 治愈兔技能与获取方式详解
- 拥有独特天赋“仁心”的治愈兔,在萌化状态下可清除己方全体所受的负面状态,并有效防止后续异常状态侵扰。在基础技能方面,火苗不仅能对敌人造成直接的物理打击,还能为自己积累1点能量,为接下来的技能释放做好准备;拍击则通过魔力凝聚,施加显著的魔法伤害;防御技能会瞬间在身体周围生成一层柔和的红色护盾,最高可减免80%incoming伤害;猛烈撞击带来强力的近身冲击,打出可观的物理输出;碰爪也不容小觑,攻击后还可追加一次额外的物理创伤,提升连击压制力。随着战斗进程推进,更多高阶技能逐步解锁。音波弹释放出震荡能量,造
- 4小时前 16:33 洛克王国:世界 0
-
 正版软件
正版软件
- 抖音爆款视频灵感哪里找?如何制作爆款短视频
- 在如今这个短视频时代,抖音已经成为了一个热门的社交平台,吸引了大量用户。很多人都在抖音上找到了自己的粉丝,甚至有些人通过抖音实现了财务自由。如何制作出爆款视频,成为了许多人关心的问题。下面,就让我来为大家揭秘爆款视频制作秘籍,让你在抖音上也能成为网红!
- 昨天 03-22 17:43 0
-
 正版软件
正版软件
- 抖音爆款视频背后的故事?抖音怎么拍视频好看
- 在信息爆炸的今天,抖音已经成为我们生活中不可或缺的一部分。每天,数以亿计的用户在抖音上刷视频、发布作品,其中,抖音爆款视频更是引发了无数人的关注。抖音爆款视频背后的故事究竟是什么呢?今天,我们就来揭秘抖音流量密码,一起探索抖音爆款视频背后的那些事儿。
- 昨天 03-22 17:32 0
-
 正版软件
正版软件
- 抖音小店流量提升工具有哪些?抖音电商爆款打造教程
- 第三方辅助引流工具,如流量助手等。这类工具主要基于众包逻辑,通过真实的移动端用户模拟自然浏览行为,来提升店铺的基础数据。
- 昨天 03-22 17:19 0
-
 正版软件
正版软件
- 抖音店铺流量少怎么办?抖音小店流量提升技巧
- 当发现抖音店铺流量少时,商家首先要做的不是盲目投钱,而是进行深度的“体检诊断”。
- 昨天 03-22 17:07 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 215天前
-
 2
2
- 高德地图是哪个国家开发的?
- 271天前
-
 3
3
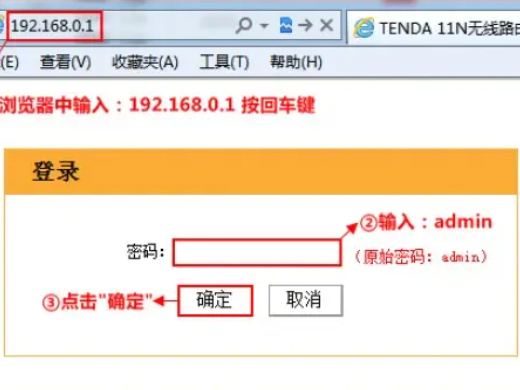
- 如何找到192.168.0.1登录入口
- 325天前
-
 4
4
- 拷贝漫画最新官网入口2025
- 104天前
-
 5
5
- yy漫画下拉式免费阅读官网入口
- 194天前
-
 6
6
- 51漫画高清入口及最新章节更新
- 64天前
-
 7
7
- 2020美团外卖账单报告入口详解
- 213天前
-
 8
8
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 232天前
-
 9
9
- 动漫共和国官网入口在线看
- 196天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00