网页数据抓取入门教程,简单实用人人能学
 发布于2025-10-11 阅读(0)
发布于2025-10-11 阅读(0)
扫一扫,手机访问
环境需求
这个工具对环境的要求非常简单,只需一台能上网的电脑和一个版本号大于31的Chrome浏览器即可。当然,浏览器版本越新越好,目前Chrome浏览器已更新至60多版本,满足要求并不难。
在线安装过程
在线安装需要能够翻墙,访问Chrome应用商店
- 在线访问Web Scraper插件页面,点击“添加至Chrome”按钮。
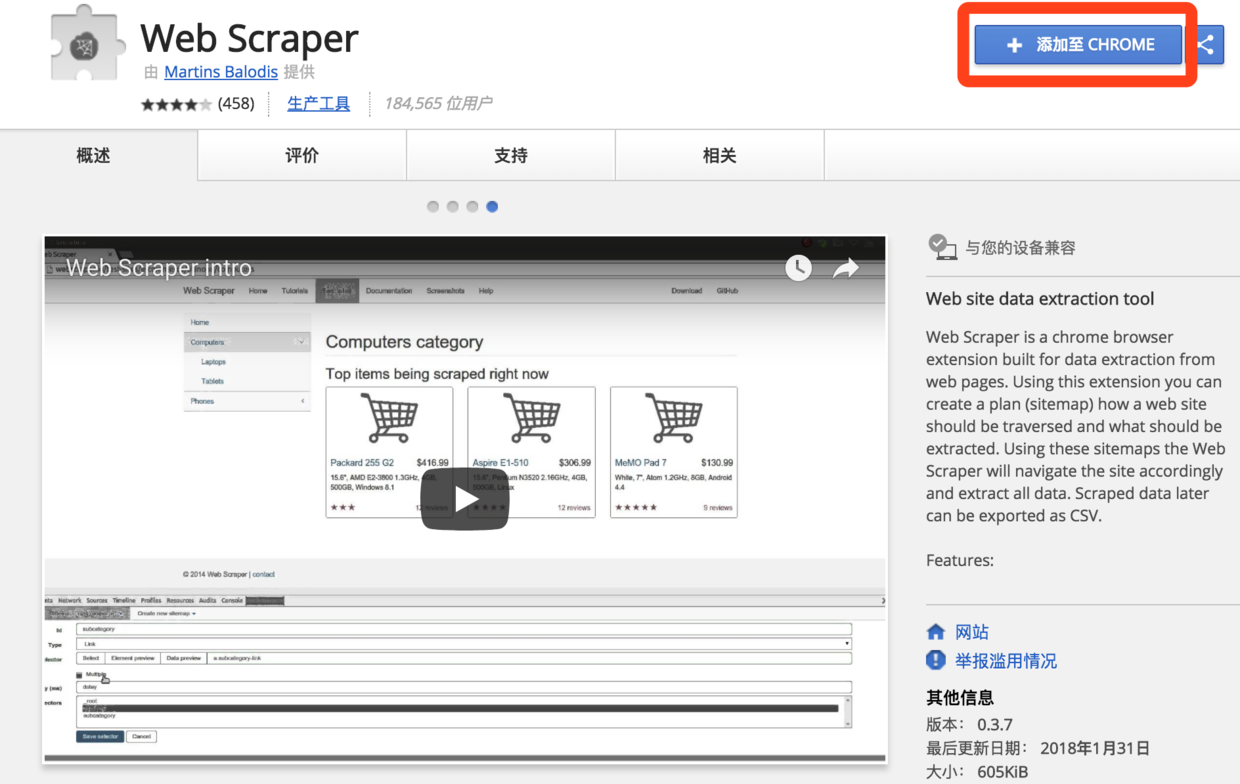 2. 在弹出的对话框中点击“添加扩展程序”。
2. 在弹出的对话框中点击“添加扩展程序”。
 3. 安装完成后,Web Scraper的图标将显示在浏览器顶部工具栏中。
3. 安装完成后,Web Scraper的图标将显示在浏览器顶部工具栏中。

本地安装过程
无法翻墙的用户可以使用本地安装方式,在本公众号回复「爬虫」可下载Chrome和Web Scraper扩展插件
- 打开Chrome浏览器,在地址栏输入
chrome://extensions/,进入扩展程序管理界面,然后将下载好的扩展插件Web-Scraper_v0.3.7.crx拖拽到此页面,点击“添加到扩展程序”即可完成安装。如图:
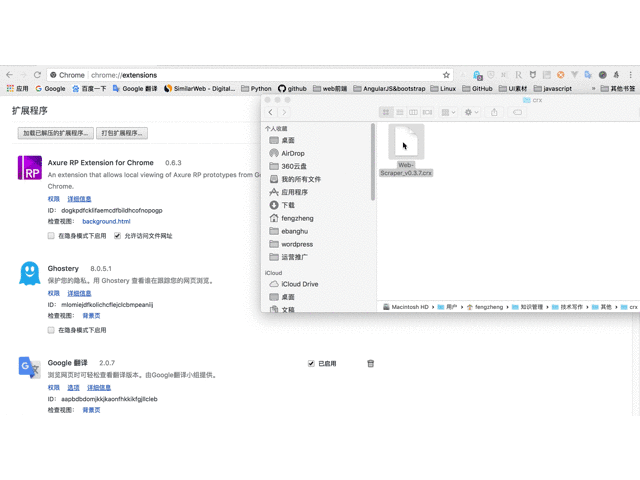 2. 安装完成后,Web Scraper的图标将显示在浏览器顶部工具栏中。
2. 安装完成后,Web Scraper的图标将显示在浏览器顶部工具栏中。
初识Web Scraper
开发人员可以跳过此部分,直接看后面的内容
在Windows系统下,可以使用快捷键F12(某些笔记本可能需要按Fn+F12);
在Mac系统下,可以使用快捷键Command+Option+I;
也可以直接在Chrome界面上操作,点击设置->更多工具->开发者工具。
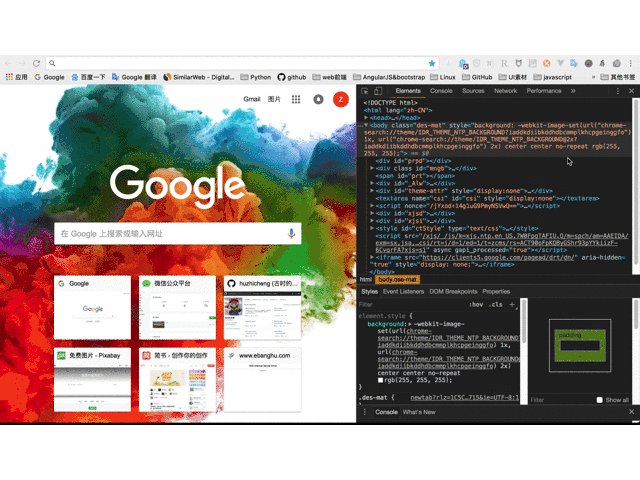
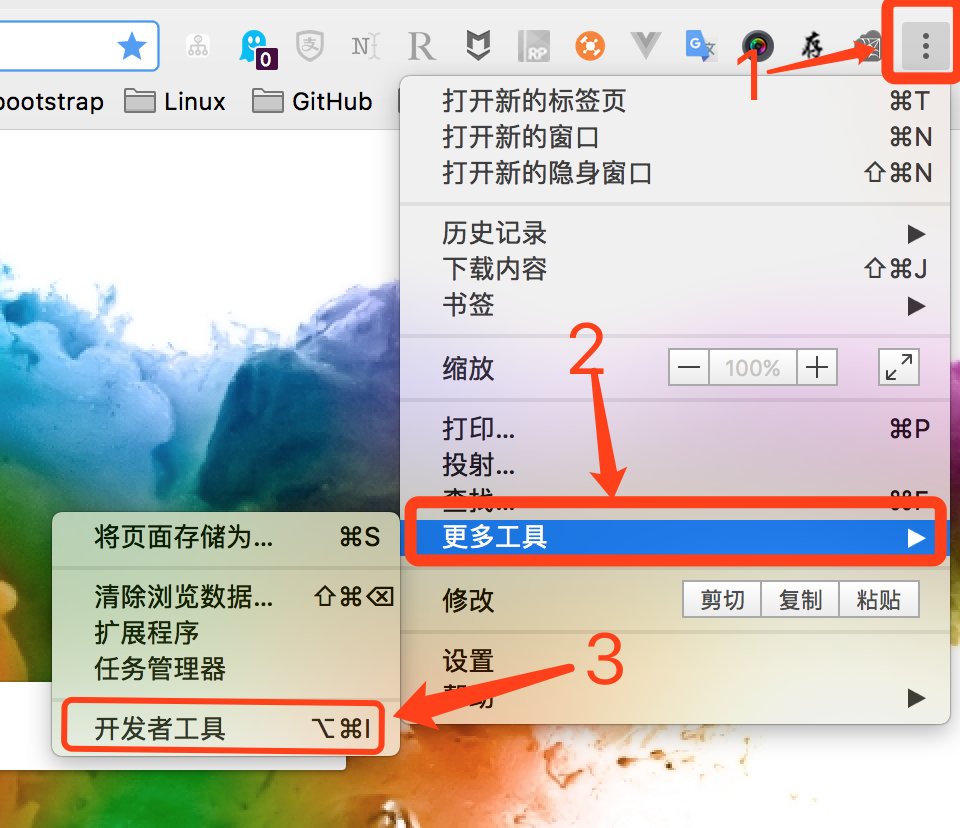 打开后的效果如下,其中绿色框部分是开发者工具的完整界面,红色框部分是Web Scraper区域,我们将在后续操作中使用。
打开后的效果如下,其中绿色框部分是开发者工具的完整界面,红色框部分是Web Scraper区域,我们将在后续操作中使用。
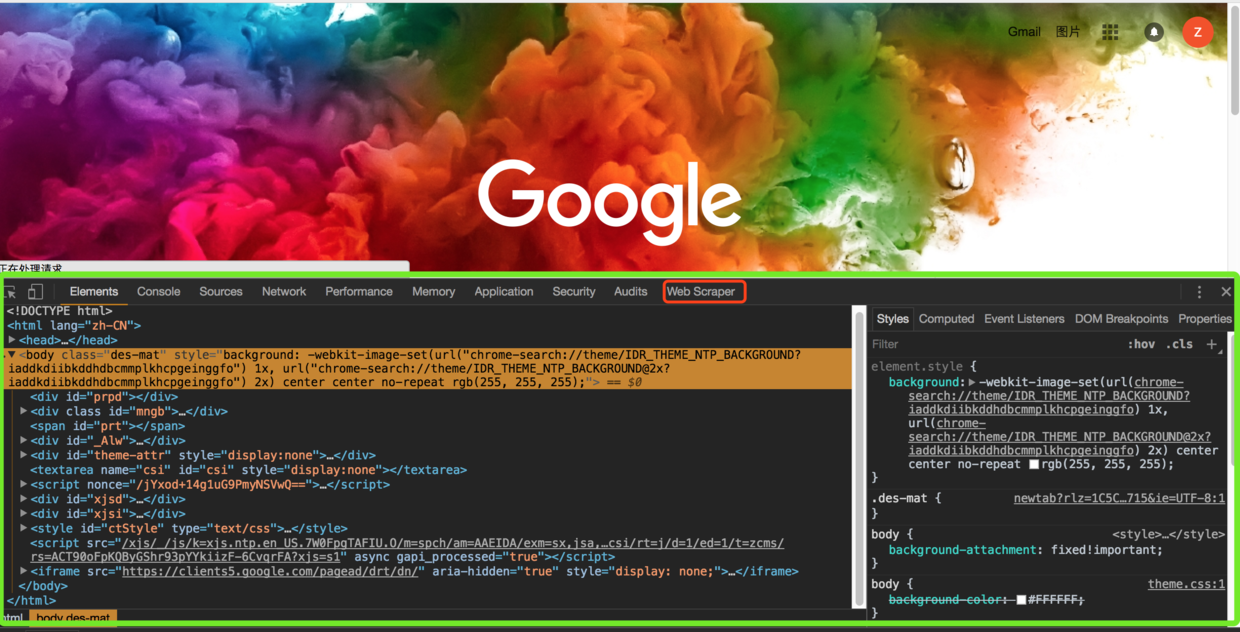 注意:如果开发者工具显示在浏览器的右侧区域,需要将其调整到浏览器底部。
注意:如果开发者工具显示在浏览器的右侧区域,需要将其调整到浏览器底部。
原理及功能说明
我们抓取数据通常是为了批量获取信息,而手动操作过于耗时甚至无法完成。例如,抓取微博热门前100条或知乎某个问题的所有答案。
基于这种需求,数据采集通常有两种方式:“我们程序员的方式”和“你们普通人的方式”。
“程序员的方式”是指开发人员根据需求编写爬虫或使用爬虫框架,如Scrapy(Python)、WebMagic(Java)、Crawler4j(Java),视需求复杂程度,编写时间从几小时到几天不等。对于复杂需求,普通人的方式可能不适用。
本文主要介绍“普通人的方式”,即使用Web Scraper工具。其界面简洁、操作简单,且支持导出Excel格式,适合非开发人员快速上手。对于简单需求,开发人员也无需自己编写爬虫,几下鼠标操作比编写代码更快捷。
数据爬取的思路可以概括为:
- 通过一个或多个入口地址获取初始数据,如文章列表页或带分页的列表页;
- 根据入口页面中的链接进入下一级页面,获取必要信息;
- 根据上一级的链接继续进入下一层,获取必要信息(可无限循环)。
接下来,我们正式认识Web Scraper工具。打开开发者工具,切换到Web Scraper标签页,界面分为三个部分:
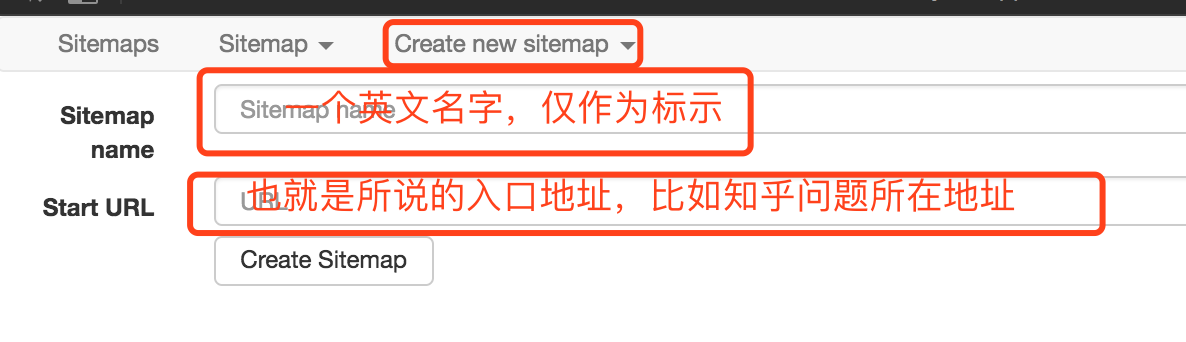
 Create new sitemap:sitemap即网站地图,可以理解为入口地址,针对一个网站或需求创建一个sitemap。例如,抓取知乎某个问题的所有回答,就创建一个sitemap,将问题地址设置为Start URL,然后点击“Create Sitemap”。
Create new sitemap:sitemap即网站地图,可以理解为入口地址,针对一个网站或需求创建一个sitemap。例如,抓取知乎某个问题的所有回答,就创建一个sitemap,将问题地址设置为Start URL,然后点击“Create Sitemap”。
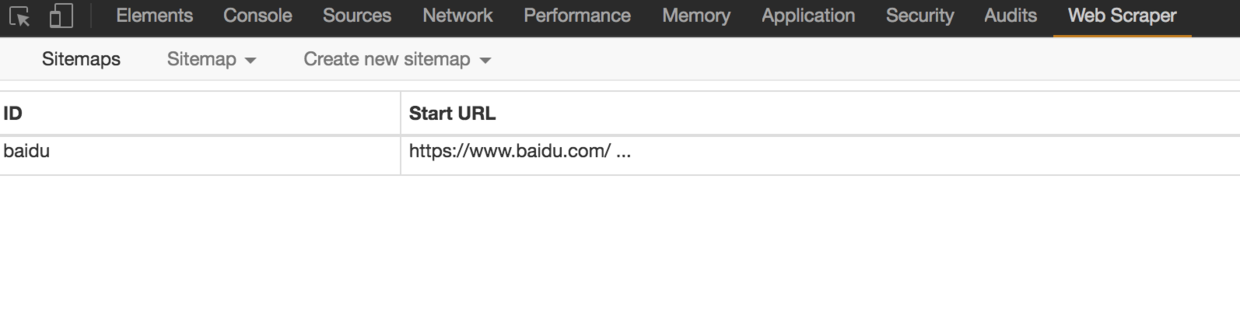
 Sitemaps:所有创建过的sitemap的集合,可以在这里查看、修改和进行数据抓取。
Sitemaps:所有创建过的sitemap的集合,可以在这里查看、修改和进行数据抓取。
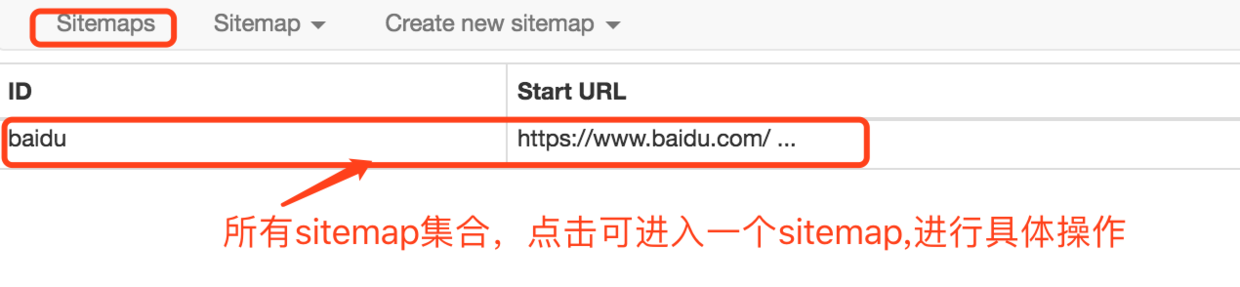 Sitemap:进入具体的sitemap,可以进行一系列操作,如下图:
Sitemap:进入具体的sitemap,可以进行一系列操作,如下图:
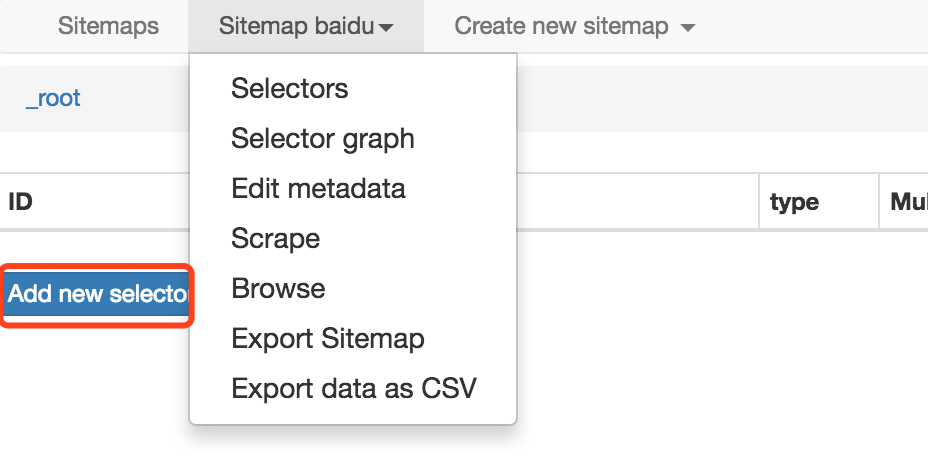 其中红色框部分的Add new selector是必不可少的步骤。selector即选择器,对应网页上包含我们要收集数据的区域。
其中红色框部分的Add new selector是必不可少的步骤。selector即选择器,对应网页上包含我们要收集数据的区域。
一个sitemap下可以有多个selector,每个selector可以包含子selector,一个selector可以只对应一个标题,也可以对应包含标题、副标题、作者信息、内容等的整个区域。
Selectors:查看所有选择器。
Selector graph:查看当前sitemap的拓扑结构图,显示根节点和选择器的层级关系。
Edit metadata:修改sitemap信息,包括标题和起始地址。
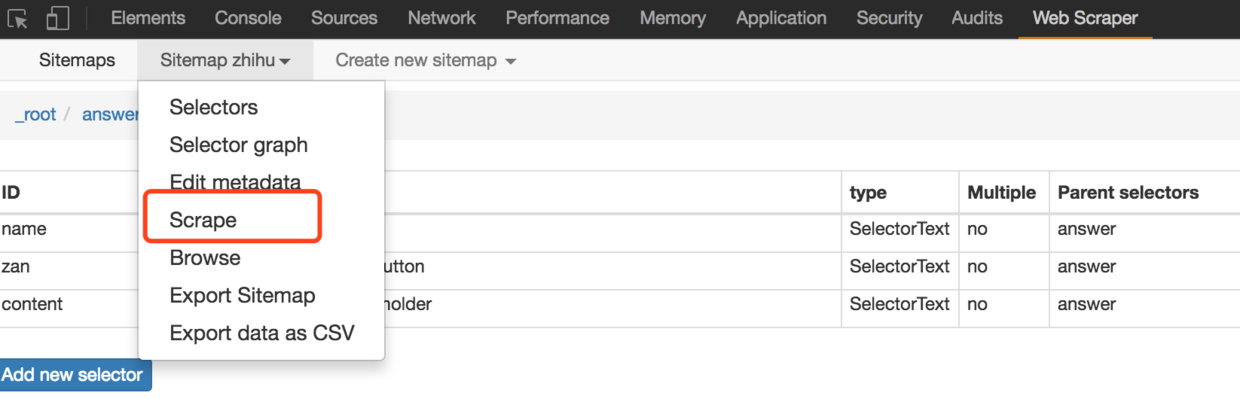
Scrape:开始数据抓取工作。
Export data as CSV:以CSV格式导出抓取的数据。
案例实践
简单试水hao123
由浅入深,以一个最简单的例子作为入门
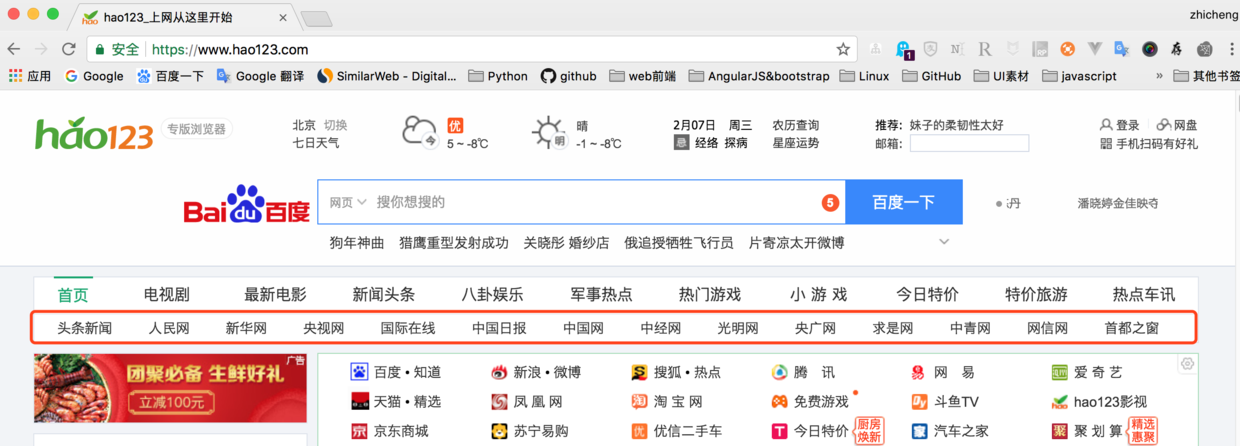 操作步骤:
操作步骤:
- 打开hao123页面,并在页面底部打开开发者工具,定位到Web Scraper标签栏;
- 点击“Create Sitemap”;
 3. 输入sitemap名称和start url,名称为hao123(不支持中文),start url为hao123网址,然后点击“Create Sitemap”;
3. 输入sitemap名称和start url,名称为hao123(不支持中文),start url为hao123网址,然后点击“Create Sitemap”;
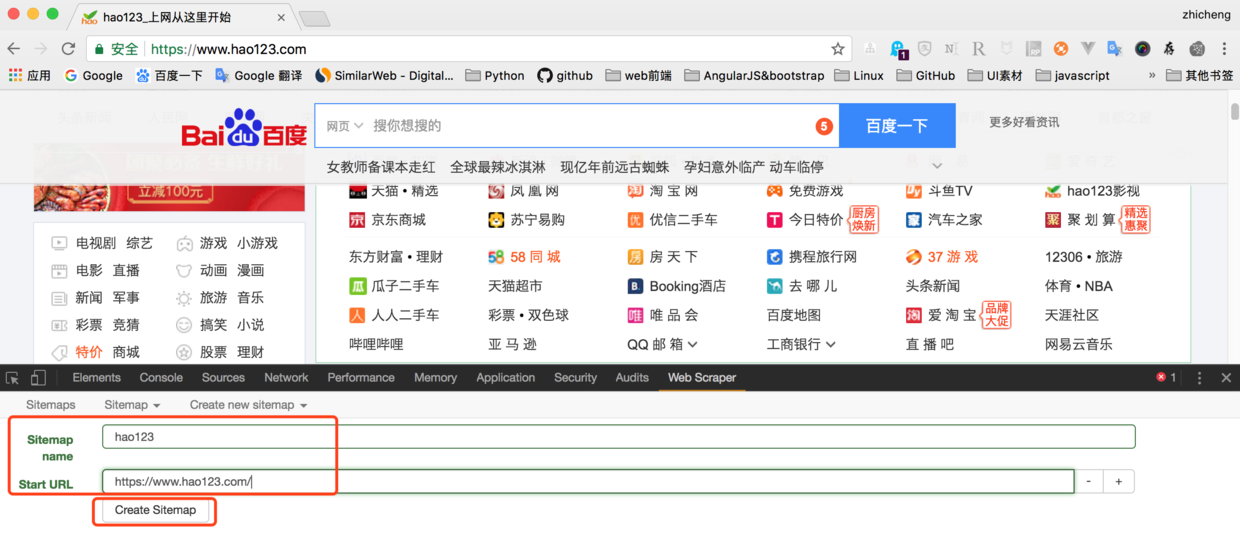 4. Web Scraper自动定位到这个sitemap,点击“Add new selector”添加选择器;
4. Web Scraper自动定位到这个sitemap,点击“Add new selector”添加选择器;
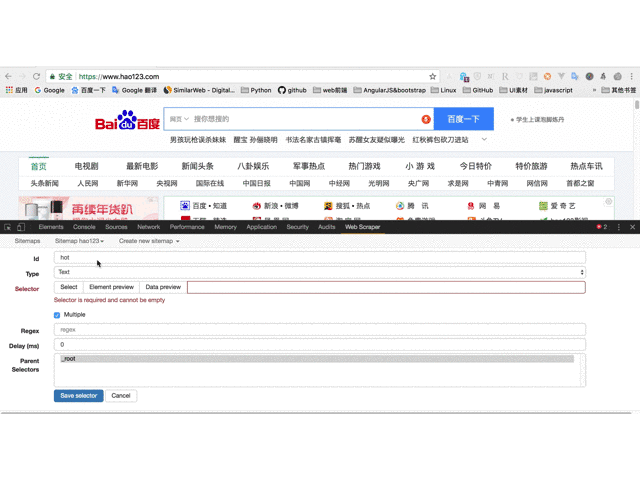
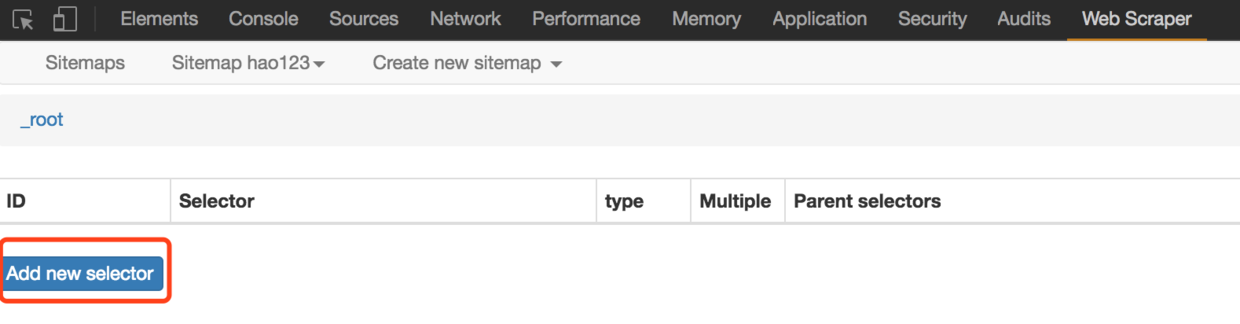 5. 给selector指定id(如hot),选择Type为Link,Link类型会自动提取名称和链接两个属性;
5. 给selector指定id(如hot),选择Type为Link,Link类型会自动提取名称和链接两个属性;
 6. 点击“Select”,在网页上移动光标,选中所需区域(如头条新闻),继续选中其他链接,确保所有相关链接变为红色,然后点击“Done selecting!”,勾选Multiple表示采集多条数据;
6. 点击“Select”,在网页上移动光标,选中所需区域(如头条新闻),继续选中其他链接,确保所有相关链接变为红色,然后点击“Done selecting!”,勾选Multiple表示采集多条数据;
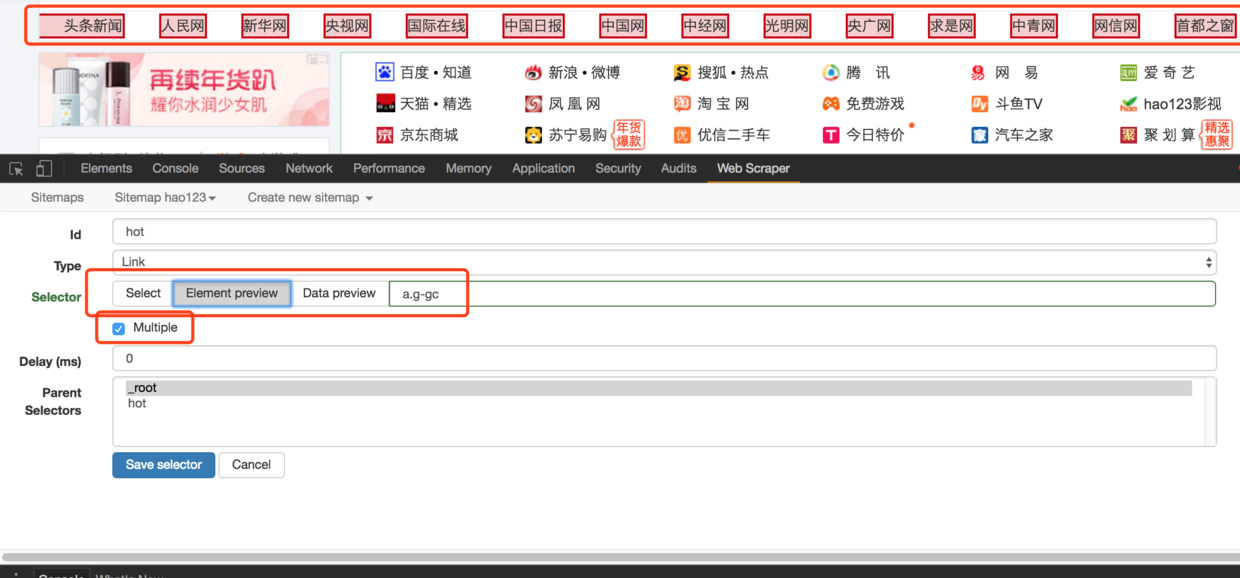 7. 保存选择器,点击“Element preview”预览选择区域,点击“Data preview”在浏览器中预览抓取的数据,文本框中的内容是xpath,可以手动编写xpath;
7. 保存选择器,点击“Element preview”预览选择区域,点击“Data preview”在浏览器中预览抓取的数据,文本框中的内容是xpath,可以手动编写xpath;
完整操作过程如下:
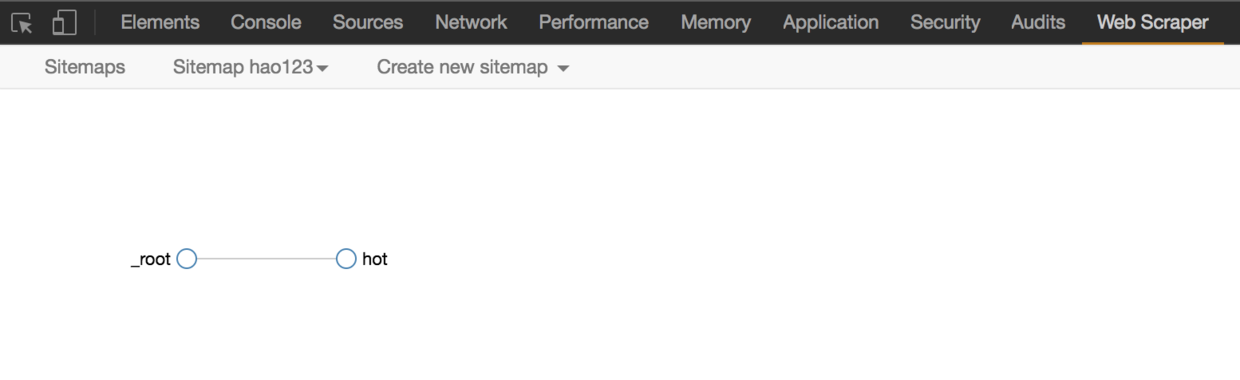
 8. 操作完成后,可以导出数据。查看Sitemap hao123下的Selector graph,了解拓扑结构图,_root是根selector,包含子selector hot;
8. 操作完成后,可以导出数据。查看Sitemap hao123下的Selector graph,了解拓扑结构图,_root是根selector,包含子selector hot;
 9. 点击“Scrape”开始抓取数据。
9. 点击“Scrape”开始抓取数据。
- 在Sitemap hao123下的Browse中,通过浏览器直接查看抓取结果;
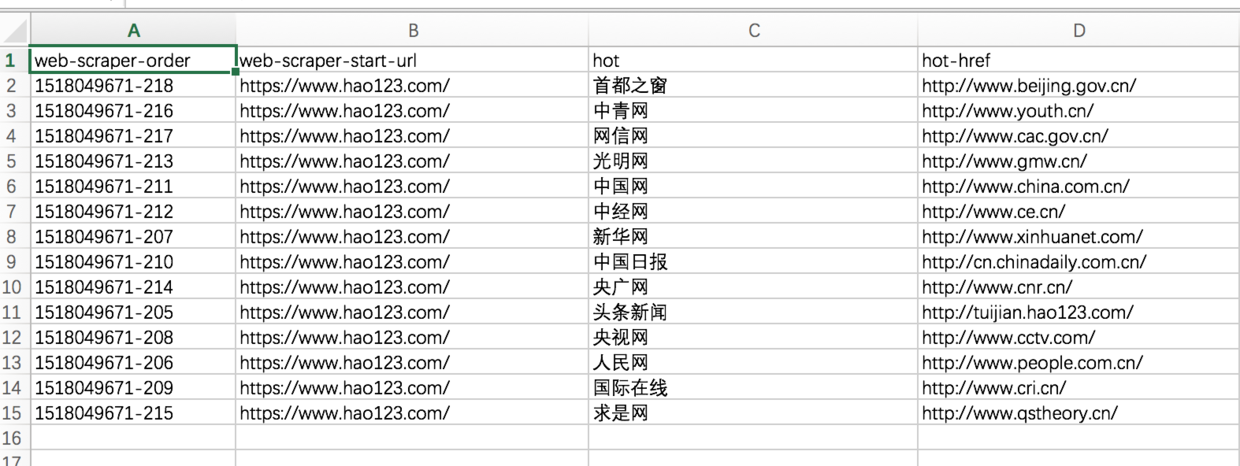
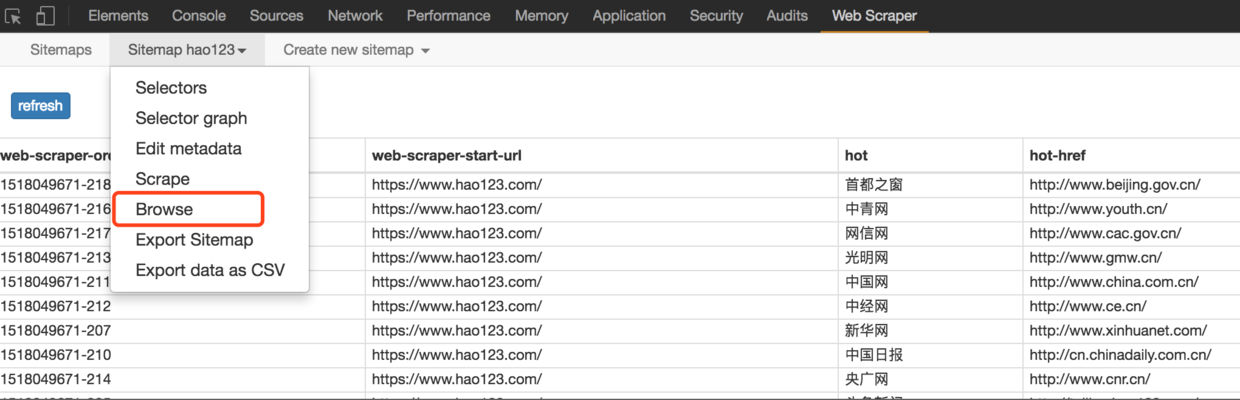 11. 最后,使用“Export data as CSV”以CSV格式导出数据,其中hot列是标题,hot-href列是链接;
11. 最后,使用“Export data as CSV”以CSV格式导出数据,其中hot列是标题,hot-href列是链接;
 赶紧尝试一下吧!
赶紧尝试一下吧!
抓取知乎问题所有回答
知乎的特点是页面向下滚动才会加载后面的回答
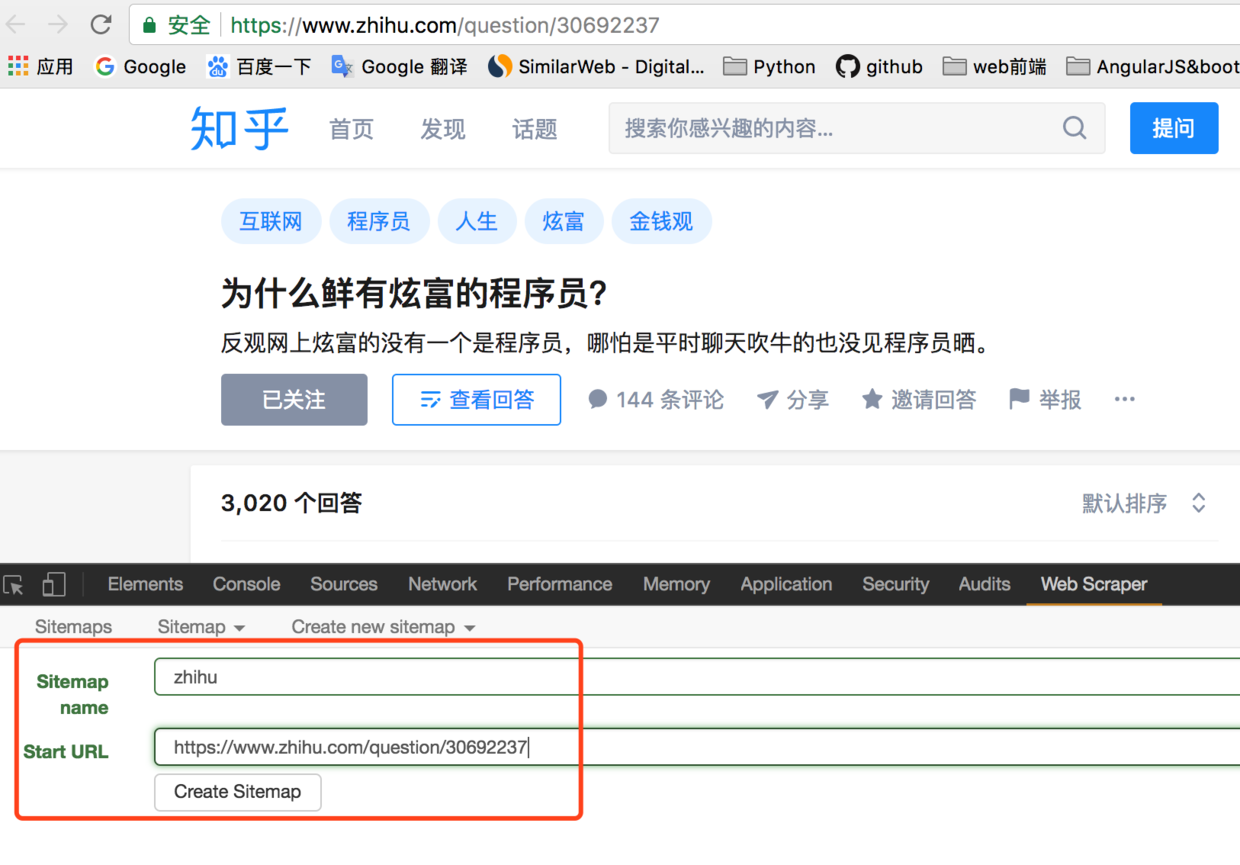
- 在Chrome中打开链接(https://www.zhihu.com/question/30692237),调出开发者工具,定位到Web Scraper标签栏;
- 点击“Create new sitemap”,填写sitemap名称和start url;
 3. 开始添加选择器,点击“Add new selector”;
3. 开始添加选择器,点击“Add new selector”;
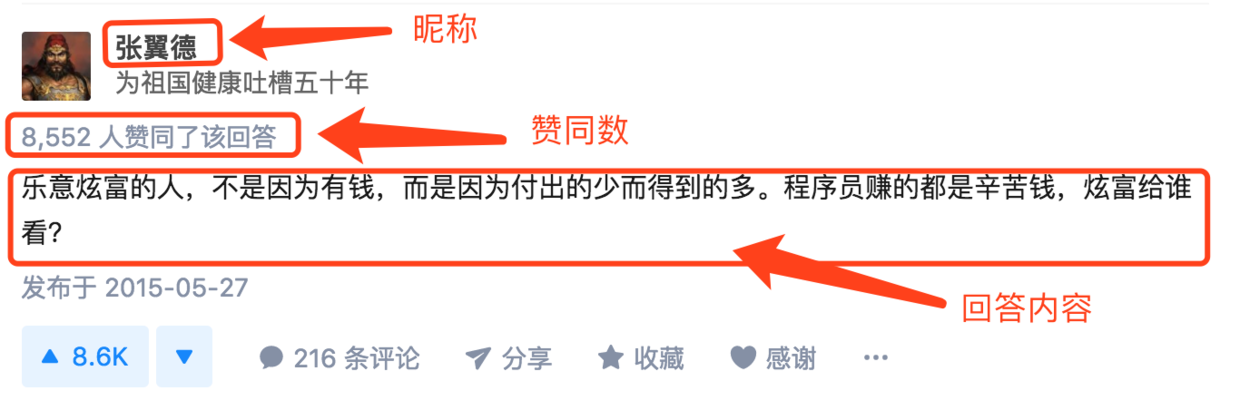
- 分析知乎问题的结构,每个回答区域包括昵称、赞同数、回答内容和发布时间等。红色框住的部分是我们要抓取的内容。抓取数据的逻辑是:由入口页进入,获取当前页面已加载的回答,找到回答区域,提取昵称、赞同数、回答内容,依次向下执行,模拟向下滚动鼠标,加载后续部分,循环往复,直到全部加载完毕;
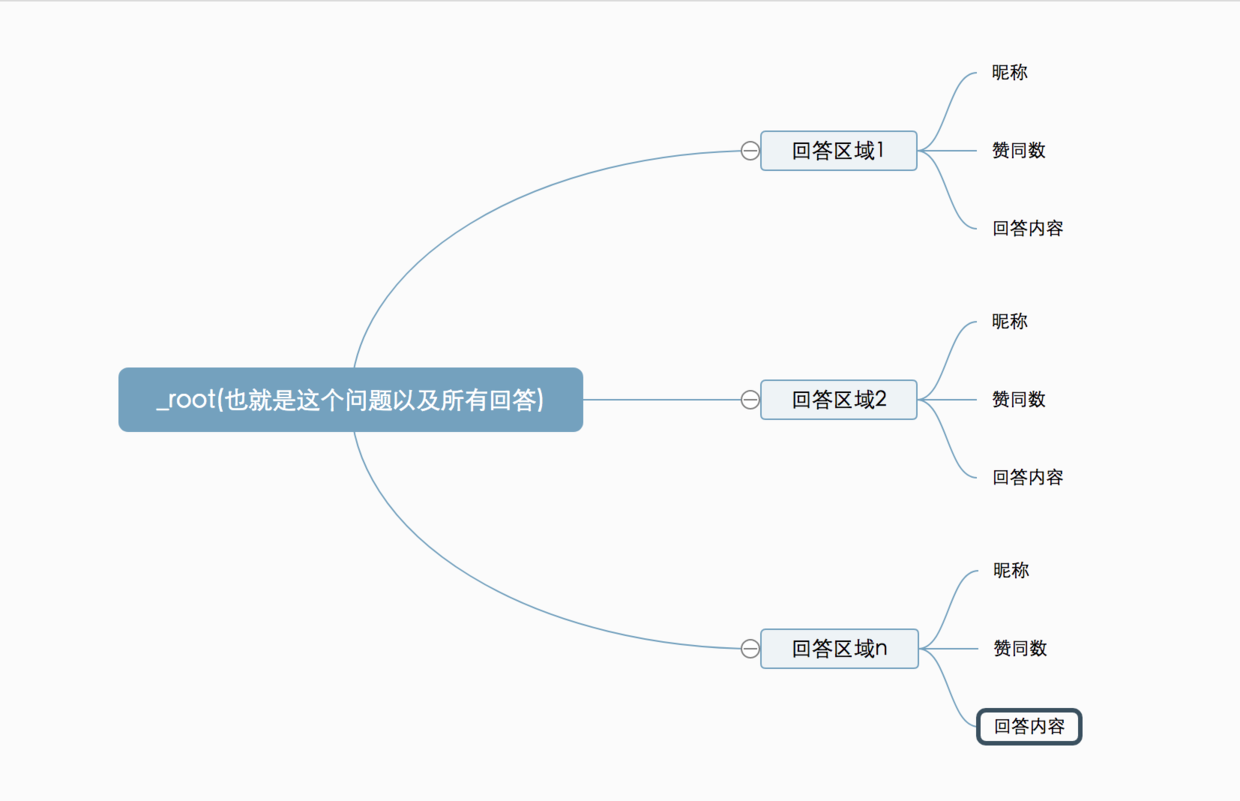
 5. 内容结构的拓扑图如下,_root根节点下包含多个回答区域,每个区域下包含昵称、赞同数、回答内容;
5. 内容结构的拓扑图如下,_root根节点下包含多个回答区域,每个区域下包含昵称、赞同数、回答内容;
 6. 根据拓扑图创建选择器,填写selector id为answer,Type选择Element scroll down。Element适用于大范围区域,包含子元素,回答区域对应Element,Element scroll down适用于下拉加载的情况;
6. 根据拓扑图创建选择器,填写selector id为answer,Type选择Element scroll down。Element适用于大范围区域,包含子元素,回答区域对应Element,Element scroll down适用于下拉加载的情况;
 7. 点击“Select”,鼠标移动到页面,让绿色框框住一个回答区域后点击鼠标,移动到下一个回答,同样框住后点击鼠标,所有回答区域变成红色框后,点击“Done selecting!”,选择Multiple,保存;
7. 点击“Select”,鼠标移动到页面,让绿色框框住一个回答区域后点击鼠标,移动到下一个回答,同样框住后点击鼠标,所有回答区域变成红色框后,点击“Done selecting!”,选择Multiple,保存;
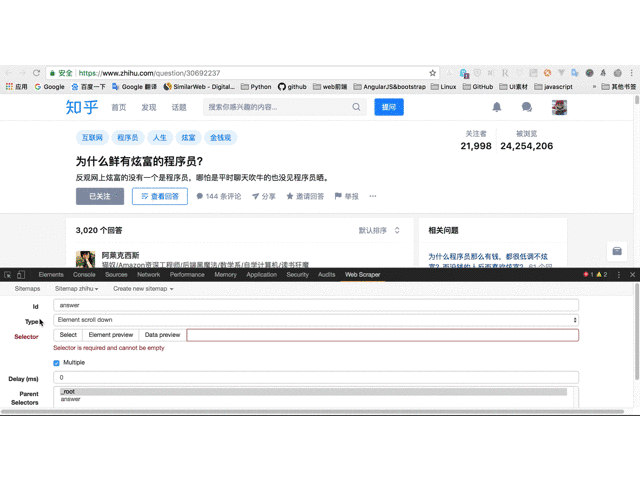 8. 点击红色区域,进入answer选择器,创建子选择器;
8. 点击红色区域,进入answer选择器,创建子选择器;
 9. 创建昵称选择器,设置id为name,Type为Text,选择昵称部分,保存;
9. 创建昵称选择器,设置id为name,Type为Text,选择昵称部分,保存;
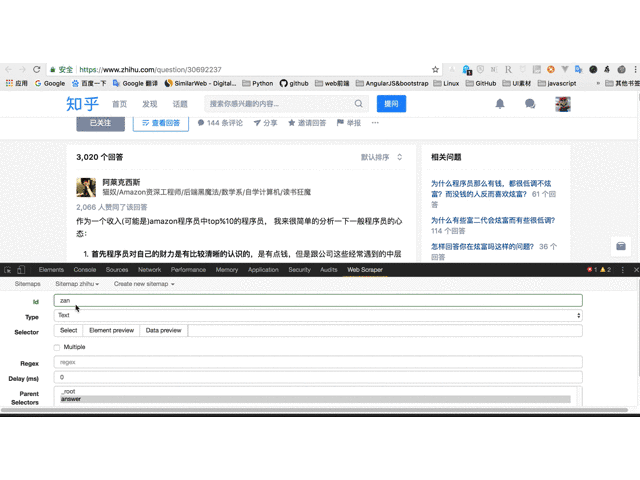
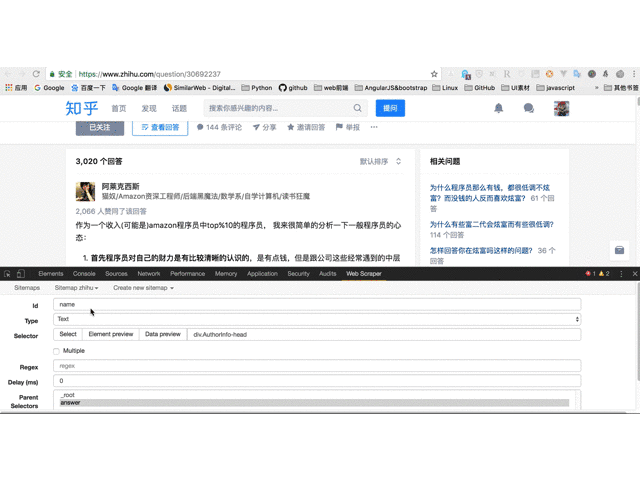 10. 创建赞同数选择器;
10. 创建赞同数选择器;
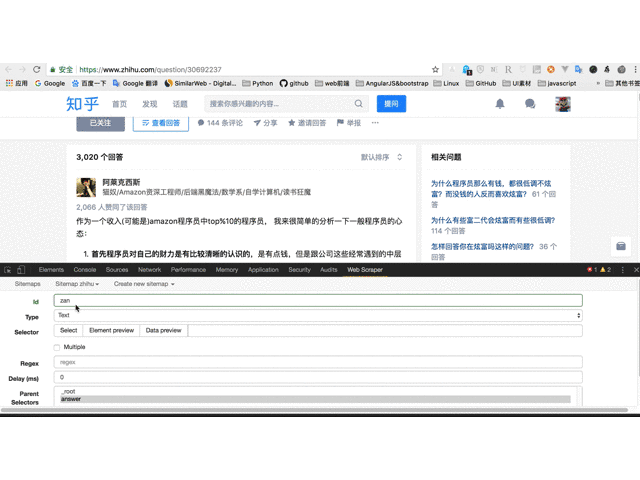
 11. 创建内容选择器,由于内容较长且有格式,从下方选择会更方便;
11. 创建内容选择器,由于内容较长且有格式,从下方选择会更方便;
 12. 执行“Scrape”操作,由于内容较多,可能需要几分钟,如果是测试,可以选择回答数较少的问题。
12. 执行“Scrape”操作,由于内容较多,可能需要几分钟,如果是测试,可以选择回答数较少的问题。
资源获取
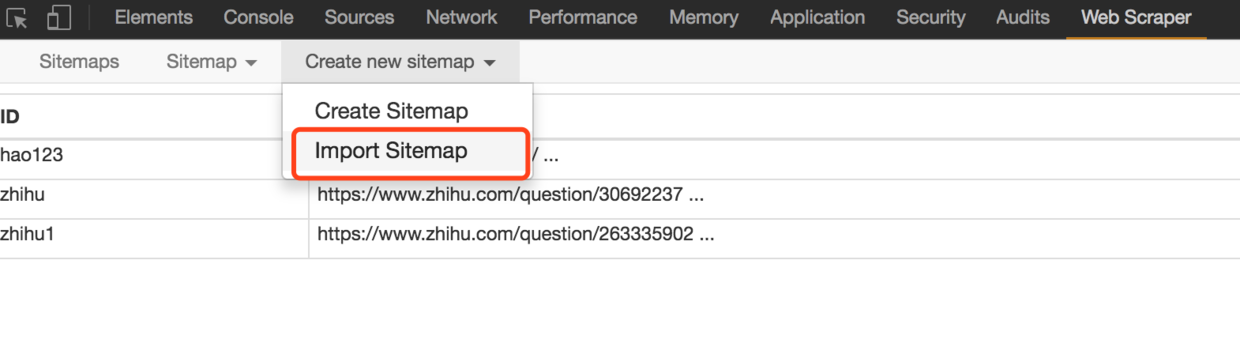
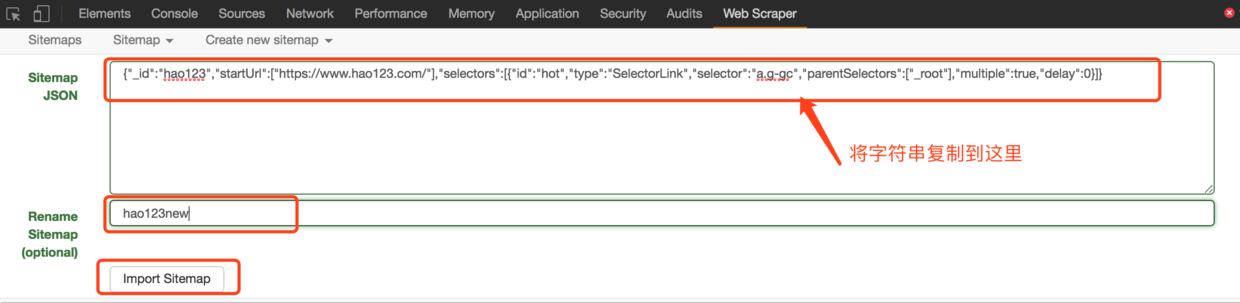
在本公众号内回复「爬虫」,获取Chrome和Web Scraper扩展程序的安装包。在本公众号内回复「sitemap」,获取本文中抓取hao123和知乎的sitemap文本。获取的sitemap是一段json文本,通过“Create new Sitemap”下的“Import Sitemap”,输入获取到的sitemap json串,起个名字,点击导入按钮即可。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:Win7设置工作组方法详解
下一篇:Word内存不足解决方法大全
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 做短视频怎么找剧本?
- 短视频剧本获取的五种实战路径 筹备短视频时找不到合适的剧本,这事儿挺常见。问题往往出在创作路径不清晰、高效方法没掌握,或者对内容来源的认知有局限。别急,下面这几种方法,都是经过验证的实战路径,总有一款适合你。 一、从生活观察中提炼原始剧本 最好的剧本,往往就藏在真实生活里。日常的对话、突发的冲突、情
- 3小时前 17:03 0
-
 正版软件
正版软件
- arc-player如何关闭视频原声-arc-player怎样关闭视频原声
- 在使用Arc Player观看视频时,如何关闭视频原声? 用Arc Player看视频,有时你可能会想关掉原声。比如,想配上自己喜欢的背景音乐,或者原声有些杂音、对白不清,影响了观看感受。那么,具体该怎么操作呢?下面就来详细说说。 一、进入视频播放界面 首先,你得打开Arc Player,找到想看的
- 3小时前 17:03 0
-
 正版软件
正版软件
- 如何加入别人的元宝派-怎样加入他人的元宝派
- 你是否渴望找到一个能让财富不断增长的途径? 元宝派或许就是你的理想之选。那么,一个现实的问题摆在面前:究竟怎么加入别人的元宝派呢? 第一步,也是基础中的基础,就是得对元宝派有充分的了解。它并非普通的社交群组,而是一个拥有独特理念与成熟发展模式的财富社群。简单来说,这里的成员通过系统性的财富规划与互助
- 3小时前 16:31 0
-
 正版软件
正版软件
- 搜狗输入法打字时选字框不显示怎么解决
- 搜狗输入法打字不显示选字框?别急,专家教你一步步排查 用搜狗输入法打字,候选词框突然“隐身”了?这确实是个挺恼人的小麻烦,直接打断了输入的流畅感。别担心,这通常不是大问题,背后无非是几个常见原因在作祟。下面咱们就按图索骥,从软件到系统,帮你把问题根源揪出来。 一、软件冲突:谁是那个“干扰项”? 电脑
- 3小时前 16:31 0
-
 正版软件
正版软件
- ps2021如何修改文字透明度
- 在PS2024中为文字添加透明效果:一份简明操作指南 想让设计作品里的文字更具层次感和设计感吗?调整文字透明度是个立竿见影的好方法。今天,我们就来详细拆解一下在Photoshop 2024中修改文字透明度的具体步骤。 整个过程其实非常直观。首先,自然是打开你的PS2024软件,并导入需要处理的图像文
- 3小时前 16:30 0
最新发布
-
 1
1
- B站免费入口官网-B站在线观看永久畅享
- 257天前
-
 2
2
- 高德地图是哪个国家开发的?
- 313天前
-
 3
3
- 动漫共和国官网入口在线看
- 238天前
-
 4
4
- 51漫画高清入口及最新章节更新
- 106天前
-
 5
5
- 拷贝漫画最新官网入口2025
- 146天前
-
 6
6
- 如何找到192.168.0.1登录入口
- 367天前
-
 7
7
- yy漫画下拉式免费阅读官网入口
- 236天前
-
 8
8
- 2020美团外卖账单报告入口详解
- 255天前
-
 9
9
- 抖音去了外地ip多久会变?ip地址怎么变位置?
- 274天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00