如何在 Go 中并发处理 SQL 查询结果集
 发布于2026-04-21 阅读(0)
发布于2026-04-21 阅读(0)
扫一扫,手机访问
Go 中高效处理大批量 SQL 结果集的并发模式
处理数据库查询结果时,一个常见的性能瓶颈是如何高效地处理返回的大量数据。比如,当你需要处理 20 万行用户数据,并对每一行执行一些相对耗时的操作(比如调用外部 API 或进行复杂计算)时,如果单线程顺序处理,效率显然不够看。
那么,一个很自然的想法是:能不能用多个 goroutine 并发地从 sql.Rows 里读取数据呢?答案是:绝对不能。
为什么 sql.Rows 不能并发读取?
这里有一个关键的技术限制需要明确:Go 标准库 database/sql 中的 sql.Rows 对象是非线程安全的。这意味着,它的 Next() 和 Scan() 方法必须在同一个 goroutine 中被串行调用。如果多个 goroutine 同时尝试调用这些方法,程序会直接 panic 或者产生不可预知的行为。
不过,别急着失望。性能瓶颈往往并不在“从数据库连接中读取字节流”这一步——数据库驱动和网络 I/O 通常已经做了缓冲。真正的耗时大户,是读取数据之后的那些业务逻辑。既然如此,思路就可以转变一下:我们让一个“专线”负责安全地读取数据,然后把读取到的“货物”分发给多个“车间”去并行加工。
这就是经典的生产者-消费者模型在 Go 中的完美应用场景。
生产者-消费者模型:顺序读取,并发处理
这个模型的核心分工非常清晰:
- 生产者(1 个 goroutine):专职负责与
sql.Rows打交道。它顺序调用rows.Next()和rows.Scan(),将每一行数据解析成结构体,然后像扔快递包裹一样,发送到一个带缓冲的通道(channel)里。 - 消费者(N 个 goroutine):一群工作 goroutine 守在这个通道的另一端,不断地从通道里接收“包裹”(即解析好的结构体),然后各自独立、互不干扰地执行那些耗时的业务逻辑。
这样一来,既严格遵守了 sql.Rows 的并发安全规则,又充分利用了多核 CPU 的并行计算能力,实现了读取与处理的速度解耦。
下面是一个完整、健壮且可直接运行的代码示例,它清晰地展示了这一模式的实现细节:
package main
import (
"database/sql"
"fmt"
"log"
_ "github.com/lib/pq" // 示例使用 PostgreSQL 驱动
)
type User struct {
ID int64
Name string
Email string
}
// 处理单行数据的业务逻辑(模拟耗时操作)
func processUser(u User) error {
// ✅ 此处可安全执行 HTTP 请求、写入文件、调用外部服务等
fmt.Printf("Processing user %d: %s\n", u.ID, u.Name)
return nil
}
func main() {
// 假设 db 已初始化
// db, err := sql.Open("postgres", "...")
// if err != nil { log.Fatal(err) }
// 1. 执行查询(注意:务必检查 err)
rows, err := db.Query("SELECT id, name, email FROM users LIMIT 200000")
if err != nil {
log.Fatal("Query failed:", err)
}
defer rows.Close() // ⚠️ 关键:确保关闭 rows
// 2. 创建带缓冲的通道,容量建议 ≥ 消费者数量 × 2(避免阻塞生产者)
ch := make(chan User, 1000)
// 3. 启动 N 个消费者 goroutine(例如 4 个)
const workers = 4
for i := 0; i < workers; i++ {
go func() {
for user := range ch {
if err := processUser(user); err != nil {
log.Printf("Error processing user %d: %v", user.ID, err)
}
}
}()
}
// 4. 生产者:单 goroutine 顺序读取并发送
for rows.Next() {
var u User
if err := rows.Scan(&u.ID, &u.Name, &u.Email); err != nil {
log.Printf("Scan error: %v", err)
continue // 或 break + rows.Close()
}
ch <- u // 发送至通道
}
// 5. 检查 rows.Err() —— 忽略此步可能导致静默错误!
if err := rows.Err(); err != nil {
log.Fatal("Rows iteration error:", err)
}
// 6. 关闭通道,通知所有消费者退出
close(ch)
}
实现时必须注意的几个关键点
上面的代码骨架虽然清晰,但魔鬼藏在细节里。要写出生产级可用的代码,下面这几个坑一定要避开:
- ✅ 必须调用 rows.Close():即使使用了
defer,也要确保其作用域能覆盖整个迭代过程,及时释放数据库连接资源。 - ✅ 务必检查 rows.Err():
rows.Next()循环结束后,一定要显式检查一下rows.Err()。因为循环可能因底层 I/O 错误而终止,不检查这个错误会导致问题被静默忽略。 - ✅ 通道应显式 close():消费者 goroutine 使用
for range ch来接收数据,这种方式依赖于通道被关闭来正常退出循环。如果忘记关闭通道,这些 goroutine 会一直阻塞等待,造成 Goroutine 泄漏。 - ⚠️ 合理设置通道缓冲区大小:如果通道没有缓冲,或者缓冲区太小,而消费者的处理速度又跟不上生产者的读取速度,生产者 goroutine 就会在发送时被阻塞,反过来拖慢整个数据库读取流程。通常建议缓冲区容量至少设置为消费者数量的 2 倍以上,具体数值需要在内存占用和处理延迟之间做权衡。
- ? 结构体字段需导出:用于
rows.Scan的结构体,其字段名必须首字母大写(即可导出),因为sql包内部是通过反射来设置字段值的,无法操作未导出的私有字段。 - ? 处理需要聚合结果的场景:如果业务逻辑需要汇总结果(比如统计总数、写入另一个表),可以在消费者中通过
sync.WaitGroup或额外的结果收集通道来汇总。但要注意,并发写入共享资源(如一个map或slice)时,必须使用锁(sync.Mutex)或其它同步机制来保证数据安全。
总的来说,“顺序读取 + 并发处理”这套模式,在实践中已经被反复验证过其有效性。它巧妙地绕开了 Go 标准库的并发限制,将 I/O 密集型的数据读取与 CPU 密集型的业务处理分离开来,是处理海量 SQL 结果集时值得信赖的标准范式。下次当你面对成千上万行数据需要处理时,不妨试试这个方案。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- html中CSS:hover选择器改变子元素、同级元素、就近元素的样式
- 想让网页元素在鼠标滑过时有反馈?以前我们习惯用Ja vaScript的mouseover和mouseout事件来监听。但其实,很多简单的交互效果,用CSS的:hover选择器就能轻松搞定,而且性能往往更优。 :hover选择器的妙处在于,它不仅能改变当前元素的状态,还能“遥控”其子元素、同级元素或相
- 11分钟前 0
-
 正版软件
正版软件
- Laravel 500错误排查指南:调试与PostgreSQL迁移技巧
- 本文系统讲解Laravel应用出现HTTP500错误时的标准化排查路径,涵盖调试模式开启、日志分析、权限配置、PHP扩展检查、Composer缓存清理及跨版本数据库迁移中的隐性风险(如bootstrap/cache/config.php残留旧配置),助开发者快速定位并解决生产环境“黑盒式”崩溃。
- 12分钟前 0
-
 正版软件
正版软件
- ajax实现excel报表导出
- 利用AJAX实现Excel报表导出【解决乱码问题】 在项目开发里,导出Excel报表是个挺常见的需求。但场景一旦复杂起来,常规方法就容易碰壁。比如,接口需要Token认证,直接用A标签就行不通;页面交互复杂,表单提交的方式也不适用。这时候,前端采用AJAX请求、后端返回文件流的方案,就成了一个自然而
- 12分钟前 0
-
 正版软件
正版软件
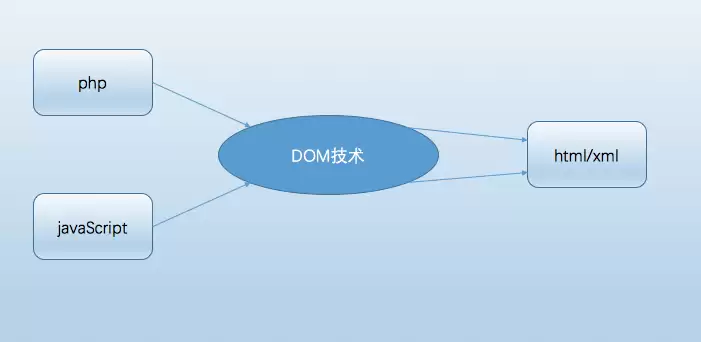
- Ajax对xml信息的接收和处理操作实例分析
- Ajax对xml信息的接收和处理操作实例分析 今天我们来拆解一个经典的前端技术组合应用:如何通过Ajax接收XML信息,并利用DOM技术对其进行处理。这个流程,其实是现代Web应用中数据交互的一个非常典型的范式。 核心角色分工 整个过程可以看作一场精密的“接力赛”: Ajax负责从服务器端请求并接收
- 14分钟前 0
-
 正版软件
正版软件
- ASP.NET MVC+EntityFramework图片头像上传功能实现
- 1,先展示一下整体的效果 2,接下来展示用户添加以及上传头像代码、添加用户界面 要搞定头像上传,前端的表单设计是关键第一步。下面这段代码,就清晰地区分了文件选择和最终保存的路径。 @Html.LabelFor(model => model.img, “头像:”, htmlAttributes: ne
- 15分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 225天前
-
4
- 探析Spring Boot框架的优点和特色
- 541天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 479天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 455天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1087天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 915天前
-
 9
9
- 解决Python安装失败的问题
- 465天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00