Python自动化实现Markdown转HTML的详细教程
 发布于2026-04-26 阅读(0)
发布于2026-04-26 阅读(0)
扫一扫,手机访问
环境配置:准备工作
动手之前,咱们先把环境搭好。Spire.Doc for Python 这个库是个不错的选择,它是个独立的文档处理组件,不依赖 Microsoft Word 就能搞定各种文本文档任务,比如今天要聊的 Markdown 转 HTML。
系统与工具要求:
- Python 版本:建议 Python 3.8 或更高版本,这样能确保和最新版库的兼容性。
- 编辑器推荐:这篇教程用 VS Code 演示,所以也推荐你用 Visual Studio Code。装上 Python 插件后,代码补全和调试功能都很完善,调用 Spire.Doc 的接口时会顺手很多。
安装步骤: 安装过程很简单,一条 pip 命令就能搞定:
pip install Spire.Doc
对了,这个组件还有免费版(Free Spire.Doc for Python),个人开发者或者小项目用起来完全没问题。
安装完成后,在脚本开头引入命名空间,就可以开始你的文档转换之旅了。
在 Python 中将单个 Markdown 文件转换为 HTML
从单个文件开始,这是最基础的操作。用 Spire.Doc for Python 来实现,步骤其实非常清晰:创建文档对象,加载 Markdown,然后保存为 HTML。
下面的 Python 代码完整展示了这个过程,你可以直接复制到 VS Code 里试试,记得把文件路径换成你自己的:
from spire.doc import *
# 创建 Document 对象
doc = Document()
# 从文件加载 Markdown
doc.LoadFromFile("全球旅游.md", FileFormat.Markdown)
# 将文档保存为 HTML
doc.Sa veToFile("markdowntohtml.html", FileFormat.Html)
doc.Close()
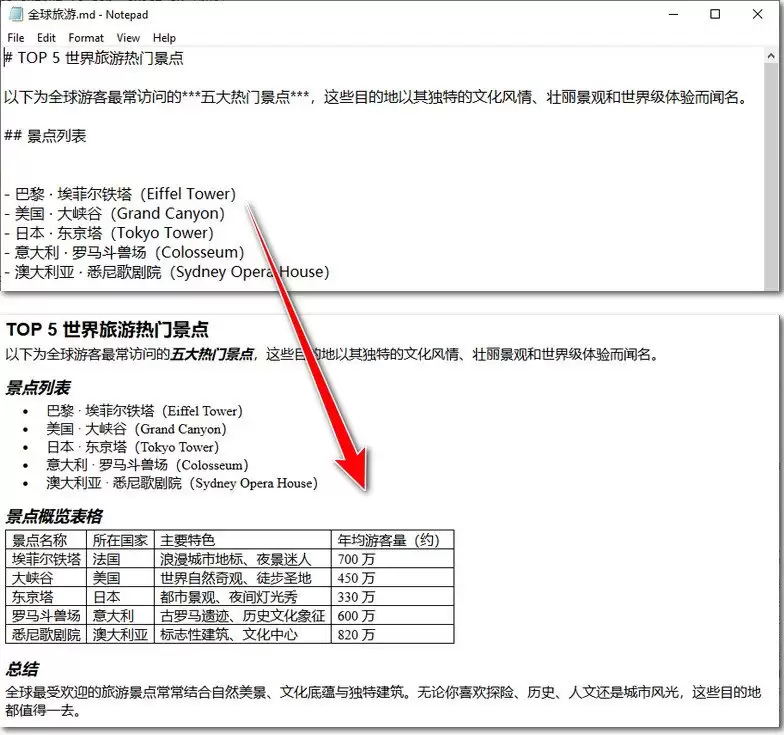
通过 Python 批量转换 Markdown 文档为 HTML
实际工作中,处理单个文件的情况可能不多,更常见的是要对付一个文件夹里几十甚至上百个技术日志或项目文档。这时候,批量转换的能力就派上用场了。
结合 Python 的 os 模块,我们可以自动扫描指定目录下的所有 .md 文件,然后为它们一一生成对应的 HTML。核心转换步骤和单个文件一样,只不过外面套了一层遍历文件的逻辑。
下面就是批量转换的代码示例:
from spire.doc import *
import os
from spire.doc import *
# 设置包含 Markdown 文件的源文件夹和 HTML 文件保存的目标文件夹
input_folder = "/input/markdown/"
output_folder = "/output/html/"
# 检查输出路径,如果不存在则自动创建,确保流程不报错
os.makedirs(output_folder, exist_ok=True)
# 遍历输入文件夹中的所有文件
for filename in os.listdir(input_folder):
# 仅处理 Markdown 后缀的文件,过滤掉其他杂质
if filename.endswith(".md"):
# 为每个文件创建一个独立的 Document 对象,避免内容叠加
doc = Document()
# 将当前遍历到的 Markdown 文件加载到对象中
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Markdown)
# 动态设置输出文件路径,将后缀名从 .md 替换为 .html
output_file = os.path.join(output_folder, filename.replace(".md", ".html"))
# 执行转换并保存到目标路径
doc.Sa veToFile(output_file, FileFormat.Html)
doc.Close()
为什么选择 Spire.Doc
除了 Markdown 转 HTML,Spire.Doc 的能耐可不止这些。同一个 Document 对象,你只需改一下 FileFormat 参数,就能轻松输出为 PDF 或者 Word 格式。这对于技术团队想要构建“一次编写,多处发布”的文档中台来说,便利性大大提升。
此外,在转换过程中,你还可以通过库提供的 API 来注入自定义的样式表,或者调整文档的各种属性,灵活性相当不错。
常见问题处理与注意事项
在实际使用 Spire.Doc 进行转换时,可能会碰到环境兼容或者特殊格式显示的问题。为了确保转换流程顺畅、输出效果完美,有几个关键点需要你额外留意:
1.中文文件转换时避免乱码困扰
处理包含中文的 Markdown 文件时,源文件最好采用 UTF-8 编码。虽然 Spire.Doc 的识别能力不弱,但在读取阶段就明确文件的编码格式,能有效避免转换后的 HTML 页面出现“烫烫烫”或者一堆问号这样的乱码。
2.数学公式与特殊表格
标准 Markdown 语法比较简单,但如果文档里包含了 LaTeX 数学公式或者结构极其复杂的嵌套表格,转换后的 HTML 渲染效果很大程度上取决于浏览器对 CSS 的支持程度。一个实用的建议是:转换完成后,针对这些复杂的 HTML 结构,引入一套成熟的样式表(比如 Bootstrap 的表格样式),这样在网页上展示时,视觉效果就有保障了。
3.图片显示问题
Markdown 里经常用相对路径引用本地图片。转换成 HTML 后,如果 HTML 文件和图片之间的相对位置发生了变化,网页上就可能显示一个难看的红叉。在进行批量转换时,比较好的做法是统一管理图片资源库,或者在转换后通过脚本批量修正 HTML 里所有
4.必要的动态库支持
虽然这个库不依赖 Microsoft Word,但在 Linux 或者 Docker 容器这类环境下运行时,系统可能会缺少一些图形渲染库(比如 libgdiplus)。如果转换过程中遇到字体解析或者图像处理报错,记得检查一下运行环境里是否已经安装了这些底层的图形依赖。
方法补充
Python 生态里能实现 Markdown 转 HTML 的库可不少,具体选哪个,得看你的需求是更看重速度,还是更看重扩展性。
下面这个表格对比了几个主流方案的核心特点,帮你快速做出选择:
| 方案 | 核心特点 | 复杂度 | 代码量/学习曲线 | 扩展灵活性 | 性能 | 适用场景 |
|---|---|---|---|---|---|---|
| markdown | 官方参考实现,社区最活跃 | 简单 | 低 | 极高(丰富的扩展机制) | 中等 | 博客系统、CMS、需要稳定支持的通用场景 |
| mistune | 性能极快,纯 Python 实现 | 中等 | 中低 | 高(插件和渲染器系统) | 最高 | 高并发 Web 应用、实时预览工具、对渲染速度有极致要求的场景 |
| markdown-it-py | 符合 CommonMark 标准,现代设计 | 中等 | 中 | 高(插件系统,与 JS 版 markdown-it 有诸多兼容插件) | 高 | 需要严格遵循标准、或希望从 JS 生态迁移的项目 |
| pypandoc | 功能最全的格式转换 | 中等 | 低(API简单) | 低(需了解 Pandoc 命令行选项) | 中等 | 需要处理多格式互转(如 md/docx/pdf)的复杂业务 |
| spire.doc | 企业级格式保真度,API 简单 | 简单 | 低 | 低 | 良好 | 企业应用、对转换质量和格式完美度有极高要求的批量处理场景 |
| markdown2 | 轻量、快速、功能全面 | 简单 | 低 | 高(支持多种额外语法) | 高 | 个人项目、快速转换、偏好轻量级开源方案 |
提示:上表总结了几种常用方案。如果你的目标不仅仅是简单的文本转换,还需要处理表格、代码高亮等复杂元素,建议你继续往下看,在“代码实战”部分,可以根据你选择的库找到支持这些高级功能的代码示例。
1. 使用markdown库
你可以把 markdown 库的高级用法封装起来,打造一个功能强大的文档转换器。
代码示例:
import markdown
from markdown.extensions.toc import TocExtension
import sys
def convert(md_file: str, html_file: str):
"""从文件读取 markdown,转换为带有目录的 html"""
with open(md_file, 'r', encoding='utf-8') as f:
text = f.read()
# 添加扩展:TOC(目录)、extra(表格)、codehilite(高亮)
extensions = [
'extra', 'toc', 'codehilite',
TocExtension(permalink="¶", title="在此处引用")
]
html = markdown.markdown(text, extensions=extensions)
# 生成完整的HTML页面
full_html = f"""
{md_file}
\n{html}\n
"""
with open(html_file, 'w', encoding='utf-8') as f:
f.write(full_html)
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python convert.py input.md output.html")
sys.exit(1)
convert(sys.argv[1], sys.argv[2])
这段代码演示了如何读取一个 Markdown 文件,利用 extra 扩展集(它包含了表格、围栏代码块等功能)和 toc(目录)扩展进行转换,最终生成一个带有 GitHub 风格样式的完整 HTML 页面。
2. 使用 mistune 库
mistune 本身追求极致的速度,如果引入 Pygments 作为代码高亮的后端,就能在速度和视觉效果之间取得很好的平衡。
代码示例:
import mistune
from pygments import highlight
from pygments.lexers import get_lexer_by_name
from pygments.formatters import HtmlFormatter
class HighlightRenderer(mistune.HTMLRenderer):
"""支持代码高亮的定制渲染器"""
def block_code(self, code, lang=None):
if lang:
lexer = get_lexer_by_name(lang, stripall=True)
formatter = HtmlFormatter()
return highlight(code, lexer, formatter)
return '' + mistune.escape(code) + '
'
def mistune_advanced_convert(markdown_text: str) -> str:
"""使用高级配置和自定义渲染器进行转换"""
renderer = HighlightRenderer()
markdown = mistune.Markdown(renderer=renderer, plugins=['table', 'footnotes'])
return markdown(markdown_text)
这个示例通过自定义一个 HighlightRenderer 渲染器,实现了对代码块的语法高亮功能。
3. 使用 markdown-it-py 库
如果你已经熟悉 Ja vaScript 生态里的 markdown-it 库,或者希望从前端项目迁移过来,那么 markdown-it-py 能提供几乎一致的开发体验。
安装:pip install markdown-it-py[plugins]
代码示例:
from markdown_it import MarkdownIt
# 使用默认 presets,启用表格、代码块、删除线等
md = MarkdownIt('commonmark') # 或 'default', 'zero' 等预设
md.enable(['table', 'strikethrough'])
markdown_text = """
| 语法 | 说明 |
|------|------|
| 表格 | 支持 `table` 扩展 |
"""
html = md.render(markdown_text)
MarkdownIt 提供的预设(比如 commonmark, default 等)能让你快速适配不同的 Markdown 风格。
4. 使用 pypandoc 库
如果你的自动化任务涉及多种文档格式之间的复杂转换,那么 pypandoc 无疑是功能最强大的工具。
安装:pip install pypandoc。
准备:它需要 pandoc 作为后端引擎,可以通过以下方式安装:
- 命令行:
brew install pandoc(macOS) |sudo apt install pandoc(Ubuntu) | 从官网下载 (Windows)。 - Python代码自动下载:
pypandoc.download_pandoc()。
代码示例:
import pypandoc
# 单文件转换
output = pypandoc.convert_file('input.md', 'html', outputfile='output.html')
# 批量目录转换
from pathlib import Path
for md_file in Path('docs/').glob('*.md'):
pypandoc.convert_file(str(md_file), 'html', outputfile=md_file.with_suffix('.html'))
这段代码展示了如何使用 pypandoc 高效地处理单个文件或整个目录的批量文档转换。
进阶技巧:自动化与安全
为了提升效率并应对自动化场景,这里有一些实践建议:
- 批量转换:使用
glob或pathlib遍历文档目录,对每个文件执行转换操作。pypandoc在这方面尤其擅长。 - 性能优化:对于高频率、低延迟的场景,优先考虑
mistune或markdown-it-py。如果是企业级的大批量处理,spire.doc这类商业库值得考虑。 - 样式与高亮:为生成的 HTML 编写 CSS 样式,并结合
codehilite(用于python-markdown)、Pygments(用于mistune)等工具来实现代码高亮。 - 网络安全:这一点至关重要:当处理来自用户输入的 Markdown 内容时,务必进行清理(Sanitization),以防止跨站脚本攻击(XSS)。
markdown-it-py可以通过配置来限制允许使用的 HTML 标签。
总结
总的来说,本文详细介绍了如何利用 Spire.Doc for Python 高效地将 Markdown 转换为 HTML,无论是处理单个文件还是批量转换多个文件,这个组件都能轻松胜任。其官网还提供了将 Markdown 转为 Word 或 PDF 的教程,有兴趣的话可以去看看。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Composer提示无法读取 auth.json 中的凭证_检查文件编码与权限【认证排查】
- Composer认证排查:当auth.json“沉默”失效时,如何精准定位问题? 你是否遇到过这种情况:composer install 时,明明配置了 auth.json,系统却依然提示需要认证,或者干脆静默地回退到了匿名访问?问题往往就出在这个小小的认证文件上。今天,我们就来深入聊聊几个最隐蔽、
- 20分钟前 0
-
 正版软件
正版软件
- VSCode编辑器字体连字失效_排查CSS设置与字体兼容性
- VSCode连字需同时满足编辑器配置启用("editor.fontLigatures": true)和字体本身支持;字体名须严格匹配系统注册名,且Linux下可能存在OpenType渲染链问题。 连字功能在 VSCode 中根本没生效,先确认设置项是否开启 想让VSCode显示漂亮的连字效果?这事儿
- 20分钟前 0
-
 正版软件
正版软件
- VSCode插件本地存储_查看已安装插件的源码与配置
- VSCode插件默认存于用户数据目录的extensions文件夹:Windows为%USERPROFILE%.vscode\extensions,macOS/Linux为$HOME/.vscode/extensions;可通过命令面板运行“Developer: Open Extensions Fol
- 21分钟前 0
-
 正版软件
正版软件
- Composer如何使用Private Packagist_Composer Private Packagist使用策略
- Private Packagist 配置实战:避开那些“静默失败”的坑 Token配置:全局命令是唯一正解,别在文件里手写 只修改项目里的 composer.json,却忘了配认证令牌?那结果必然是失败。Private Packagist 不接受匿名访问,而且它也不认你在项目目录下手动创建的 aut
- 21分钟前 0
-
 正版软件
正版软件
- VSCode怎么使用Markdown All in One_VSCode如何用插件增强Markdown快捷键和目录生成【攻略】
- VSCode Markdown All in One 插件:那些“静默失败”的坑与解决之道 简单概括一下核心问题:Markdown All in One 的快捷键失灵,多半是 VSCode 默认快捷键冲突,加上插件没开启键盘覆盖;用 Ctrl+K Ctrl+T 生成目录失败,往往是标题格式不规范惹的
- 22分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 230天前
-
4
- 探析Spring Boot框架的优点和特色
- 546天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 484天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 460天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1092天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 920天前
-
 9
9
- 解决Python安装失败的问题
- 470天前
相关推荐
- Composer如何管理不同 PHP 环境下的依赖隔离_使用不同的 json 配置文件【环境管理】
- 如何在WebStorm中配置Jest进行前端单元测试?
- VSCode插件开发调试_在扩展开发主机中测试新功能
- Java环境配置及Java的运行
- VSCode代码逻辑错误自动检测_基于静态分析的预警功能
- Composer如何快速同步团队间的依赖版本_严格提交 composer.lock【团队规范】
- Composer如何统计项目中不用的依赖包_利用分析工具精简代码【瘦身指南】
- Composer如何快速同步生产环境包_使用--no-dev选项安装【生产规范】
- VSCode如何开启平滑滚动效果 - 提升长代码阅读体验的隐藏开关设置
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00