AI诊断真实病例准确率超医生,哈佛称医学评估标准或应重新改写
 发布于2026-05-04 阅读(0)
发布于2026-05-04 阅读(0)
扫一扫,手机访问
AI临床诊断新突破:在真实病历中,它的推理能力已比肩医生?
如今,AI在某个标准医疗测试集上刷出新高分,已经算不上什么大新闻了。真正的考验在于实战:当面对一份信息可能残缺不全、记录或许有些混乱的真实病历时,AI还能否给出可靠的诊断推理?最近的一项重磅研究给出了肯定的答案,而且是在与数百名医生的直接对比中得出的。
来自哈佛医学院、斯坦福大学等顶尖机构的研究团队,在《科学》杂志上发表了一项迄今最大规模的AI医疗对比研究。这项研究的突破性在于,它首次使用了真实的患者病历作为“考卷”,来检验AI的临床推理能力。这意味着,AI不再是在熟悉的题库里“背诵答案”,而是进入了信息更复杂、更不确定的真实临床战场。
研究人员让OpenAI的o1模型与数百名医生,在包括急诊决策、诊断、制定后续治疗方案在内的六种不同场景中同台竞技。结果令人印象深刻:AI在多项临床推理任务中的准确率,与医生持平甚至更高。
这或许预示着一个重要的转折点。随着模型能力飞速进化,传统的人工设计测试案例和选择题式的评估基准,可能正在逐渐失效。正如论文共同第一作者、哈佛医学院研究员Peter Brodeur所言:“过去可以用多项选择题来评估模型能力,但现在它们的得分长期接近满分,这对于追踪进展已经没有太大意义了。”
当然,必须清醒地认识到,这项研究结果并不意味着AI已经准备好独立行医,尤其是在生死攸关的急诊环境中。医生在解读影像、进行体格检查、观察患者细微表情等方面,依然拥有不可替代的优势。研究团队也特别强调,亟需开展前瞻性的临床试验,在真实的患者护理环境中进一步评估这项技术。
图丨相关论文(来源:Science)
“金牌标准”下的诊断对决
为了系统考察AI的临床推理能力,研究团队设计了一系列实验。在第一组实验中,他们搬出了医学界的“金牌标准”——《新英格兰医学杂志》自20世纪50年代起设立的临床病理会议病例。
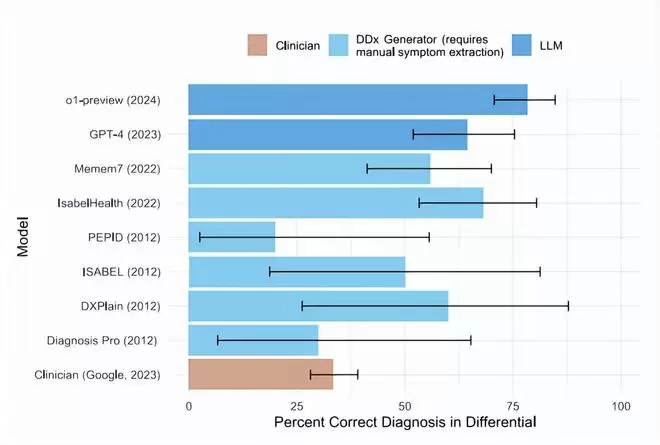
面对2012年至2024年间的143个复杂病例,o1-preview模型成功覆盖了78.3%的正确病因。更关键的是,它给出的首个诊断就是正确答案的比例达到了52%。如果算上那些“非常接近”的诊断,这个比例更是跃升至惊人的97.9%。
与GPT-4的对比则进一步凸显了其进步。在同一批病例上,GPT-4的准确率为72.9%。而在70个重叠病例中,o1-preview在24.3%的病例上表现优于GPT-4,表现落后的仅占7.1%。
另一个值得关注的细节是诊断检查的选择。在136例测试中,o1-preview选择检查项目的正确率高达87.5%。评审医生认为,AI提出的检查建议中,有11%具备额外的临床价值,而仅有1.5%的建议被判定为无帮助。
(来源:Science)
书写质量与高风险误诊识别
在临床推理的书面表达质量评估中,差距更为明显。研究团队采用了20个来自NEJM Healer课程的教学病例,并使用经过验证的R-IDEA量表进行评分。
结果如何?o1-preview在80次评分中,78次获得了满分。相比之下,GPT-4仅获得47次满分,而主治医师和住院医师获得满分的次数分别为28次和16次。在高风险误诊项的识别上,o1-preview的中位命中率达到92%。不过需要说明的是,尽管数值上高于人类医生,但这一差异在统计学上并不显著。
(来源:Science)
管理决策与防“刷题”测试
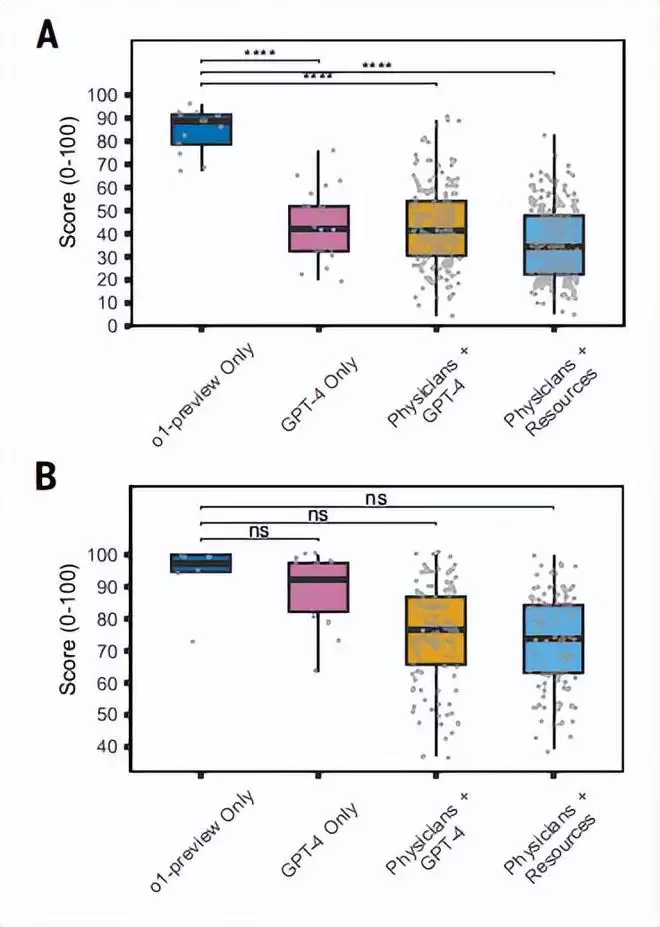
在管理决策能力的测试中,结果同样引人深思。研究团队基于五个真实病例开发了临床场景,并设置了一系列治疗决策问题。o1-preview的中位得分高达89%,远超GPT-4的42%。有趣的是,将GPT-4作为辅助工具的医生得分是41%,而仅使用传统资源制定方案的医生得分则为34%。
图丨 o1-preview、GPT-4 与临床医师在诊断推理能力方面的比较(来源:Science)
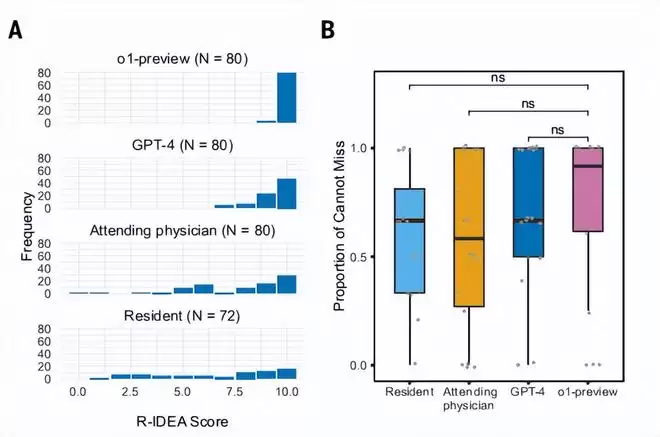
为了防止模型通过“刷题”获得优势,研究人员还增加了一道防线:使用6个从未公开发布过的标志性诊断病例进行测试。结果发现,o1-preview虽然获得了97%的中位得分,但与GPT-4的92%以及人类医师的74%相比,其统计学优势并不显著。这从侧面说明,大模型能力的提升并非在所有任务上都齐头并进。
急诊室里的真实较量
最接近真实临床环境的实验,发生在波士顿一家医院的急诊室。研究以76名真实患者为对象,设置了从早期分诊、接诊后到决定是否收入病房三个关键决策节点。
与以往研究不同,这次提供给模型的信息未经过任何人工预处理,直接来源于标准电子病历中那些可能杂乱无章的数据:生命体征、人口统计信息、对就诊原因的简要描述等。模型需要基于这些原始信息,生成诊断并提出下一步建议。
结果显示,在分诊阶段,医生的正确率在50%至55%之间,而AI在67%的病例中做出了接近甚至更准确的诊断。一个明显的趋势是:在需要快速决策且信息有限的紧急情况下,AI的优势更为突出。当提供更多细节信息后,人类专家的准确率提升至70%-79%,而OpenAI的o1模型的诊断准确率则进一步提升至近82%。
整个实验过程采用了严格的盲法设计。两位评审医生在判断答案来源是人还是AI时,猜对的比例分别仅为15.2%和3.1%。这意味着,在大多数情况下,他们根本无法区分眼前的诊断建议是出自AI还是人类同行之手。
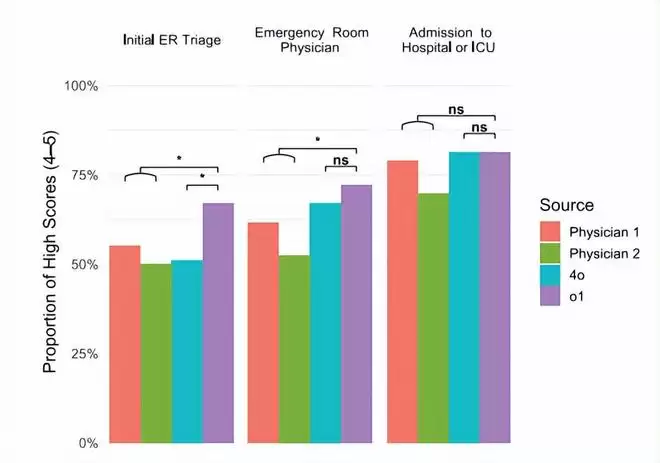
(来源:Science)
AI并非万能,协同才是未来
必须明确的是,急诊室的核心决策远不止于诊断正确性,它更关乎分诊、紧急处理和即时管理。因此,这项研究绝不意味着AI将全面取代急诊医生。
同时,这项研究也存在其局限性。实验仅测试了AI在解读文本化患者数据方面的表现,并未涉及对患者痛苦程度、外貌体征等非文本信号的解读能力。此外,研究覆盖的病例主要集中在内科和急诊领域,未来仍需在外科、专科等更广泛的临床场景中加以验证。
AI在医疗辅助诊断中的应用已呈燎原之势。今年3月美国医学协会的一项研究显示,近20%的美国医生正在使用AI辅助诊断。在英国,每天使用AI的医生比例也达到了16%。根据英国皇家内科医师学会的调查,在临床决策中将AI作为辅助诊断工具,已成为医生最常见的用途之一。
尽管表现亮眼,但AI远非万能。一方面,它自身存在出错和相应的责任风险;另一方面,也需要警惕医生可能在不经意间过度依赖AI建议,从而弱化自身的独立判断。此外,AI在诊断老年患者或非英语母语患者时,仍面临不小的挑战。
综合来看,当前AI的核心角色定位依然是“辅助”而非“替代”。它的优势在于能够快速整合海量的医学文献、诊疗指南和历史病例,在信息处理的广度与速度上为医生提供强大支持,帮助发现那些容易被遗漏的关键信息。然而,在面对非结构化的临床情境、需要进行复杂伦理权衡,以及提供不可或缺的医患共情时,医生的角色依然无可替代。
因此,人机协同或许才是最理想的未来图景:AI提供精准、实时的数据与知识支持,而医生则凭借其专业经验、整体判断和人文关怀把握最终方向。未来的关键,或许不在于比较人与AI谁更强,而在于谁能更快学会与对方高效协作。
参考资料:
1. 相关论文:https://www.science.org/doi/10.1126/science.adz4433
2.https://www.ama-assn.org/system/files/physician-ai-sentiment-report.pdf
3.https://www.rcp.ac.uk/policy-and-campaigns/policy-documents/snapshot-of-uk-physicians-artificial-intelligence-in-healthcare/
4.https://hms.harvard.edu/news/study-suggests-ai-good-enough-diagnosing-complex-medical-cases-warrant-clinical-testing
5.https://www.theguardian.com/technology/2026/apr/30/ai-outperforms-doctors-in-harvard-trial-of-emergency-triage-diagnoses
排版:刘雅坤
注:封面/首图由 AI 辅助生成
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 索尼 PS-LX3BT 入门级黑胶唱片机国行预售:动磁唱头、3.5 克唱针压力,2490 元
- 索尼PS-LX3BT黑胶唱片机国行开启预售:经典与现代的入门之选 如果你正在寻找一台能轻松踏入黑胶世界的唱机,那么最近有个新消息值得关注。索尼旗下PS-LX3BT黑胶唱片机的国行版本,目前已在京东平台启动预售,定价为2490元。官方计划在5月10日正式开启首销。 京东索尼 PS-LX3BT 黑胶唱片
- 29分钟前 0
-
 正版软件
正版软件
- 速度再翻倍 DDR6终于要来了!进入全面开发阶段
- DDR6内存全面开发启动:2028年落地,消费级普及仍需等待 自2020年DDR5内存正式登场,转眼已过去六年。按照行业迭代节奏,下一代内存标准DDR6的研发工作,如今已全面铺开。 近期有韩国媒体报道指出,三星、SK海力士及美光这三大内存巨头,已经正式邀请基板厂商加入DDR6内存的高级开发流程。这意
- 29分钟前 0
-
 正版软件
正版软件
- 消息称Anthropic看上英国企业Fractile推理芯片,有意导入
- Anthropic被曝洽谈投资英国AI芯片新锐,剑指推理成本“硬骨头” 近日,行业媒体The Information披露了一则引人注目的消息:AI领域的明星公司Anthropic,正将目光投向一家名为Fractile的英国芯片初创企业。其意图相当明确——为自身庞大的AI算力需求,寻找除英伟达GPU、
- 1小时前 21:45 0
-
 正版软件
正版软件
- AI诊断真实病例准确率超医生,哈佛称医学评估标准或应重新改写
- AI临床诊断新突破:在真实病历中,它的推理能力已比肩医生? 如今,AI在某个标准医疗测试集上刷出新高分,已经算不上什么大新闻了。真正的考验在于实战:当面对一份信息可能残缺不全、记录或许有些混乱的真实病历时,AI还能否给出可靠的诊断推理?最近的一项重磅研究给出了肯定的答案,而且是在与数百名医生的直接对
- 1小时前 21:45 0
-
 正版软件
正版软件
- 豆包回应收费后的基础功能:永久免费、不阉割
- 豆包回应收费关切:基础功能承诺永久免费,付费方案聚焦高阶需求 5月4日,一则关于豆包可能收费的消息引发了广泛讨论,并迅速登上热搜。许多用户心中不免打鼓:一旦开始收费,那些我们日常依赖的免费基础功能,会不会就此“缩水”甚至消失?针对这一核心关切,豆包方面通过APP给出了明确回应。 记者在豆包APP内直
- 1小时前 21:44 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 527天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 534天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 545天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 837天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 553天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2331天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00