浅析Python闭包如何捕获自由变量
 发布于2026-05-06 阅读(0)
发布于2026-05-06 阅读(0)
扫一扫,手机访问
一、从一个计数器开始
很多朋友在学习作用域时,都遇到过下面这段让人困惑的代码:
def make_counter():
count = 0
def counter():
count += 1 # 这里会报错
return count
return counter
c = make_counter()
print(c()) # UnboundLocalError: local variable 'count' referenced before assignment
这可不是什么bug——恰恰相反,这是Python作用域规则在“说话”。报错的根源就藏在count += 1这行看似简单的代码里,而理解它,几乎是理解闭包本质的必经之路。
要彻底搞懂这段代码,我们得先理清Python的作用域规则,以及闭包到底是怎么工作的。
二、LEGB 规则:名字查找的顺序
在Python的世界里,每当需要查找一个变量名时,解释器都会遵循一个固定的顺序,我们称之为LEGB法则:
- L(Local):当前函数内部定义的变量
- E(Enclosing):外层嵌套函数中的变量
- G(Global):模块级全局变量
- B(Built-in):Python内置的名字,比如
len、print
用一段代码来验证这个顺序,会非常直观:
x = "global" # G 层
def outer():
x = "enclosing" # E 层
def inner():
x = "local" # L 层
print(x) # -> local(找到了就停)
inner()
outer()
每一层都可以定义和上层同名的变量,它们彼此独立,互不干扰。Python之所以这样设计,是因为名字查找发生在运行时,而非编译时——解释器执行到哪一行,才去对应的作用域里寻找变量。
LEGB规则可以这样可视化理解:
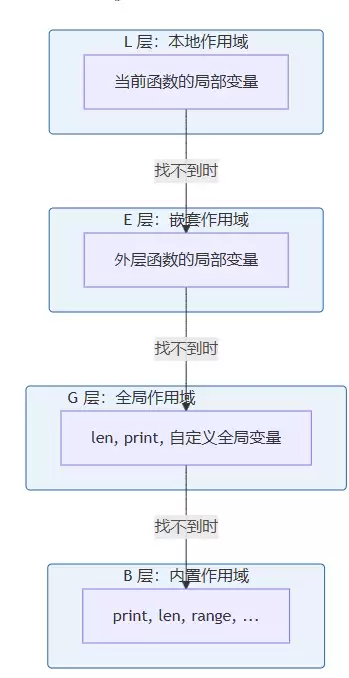
查找过程就像从圆心向外扩散,由内而外,找到即止。
三、global关键字:打破 E 层
现在回到开头那个报错的计数器。问题出在count += 1这行,它实际上等价于:
count = count + 1
Python解释器看到这行代码时,发现等号左边出现了count,就立刻判定count应该是当前作用域(L层)的局部变量。但麻烦来了:count实际上定义在make_counter()的作用域里(E层),并不在counter()的局部作用域里。Python拒绝在E层为L层创建同名变量,于是UnboundLocalError就出现了。
一个直接的解决思路是,把count提升到全局作用域:
count = 0
def make_counter():
global count # 声明接下来访问全局的 count
count += 1
return count
print(make_counter()) # 1
print(make_counter()) # 2
但global有个致命的缺陷:它让count变成了模块级的全局变量。这意味着,如果你创建多个make_counter()实例,它们将共享同一个count,计数器之间的状态隔离被完全破坏了。
四、nonlocal关键字:访问 E 层变量
nonlocal可以看作是global的近亲,但作用域完全不同。它允许在L层函数中修改E层(即嵌套外层)的变量:
def make_counter():
count = 0
def counter():
nonlocal count # 声明:接下来对 count 的赋值操作,作用于外层的 count
count += 1
return count
return counter
c = make_counter()
print(c()) # 1
print(c()) # 2
print(c()) # 3
关键在于,nonlocal不会在L层创建新变量,也不涉及G层——它直接作用于最近一层外层函数的变量。
这里简单对比一下global和nonlocal:
| 关键字 | 作用层 | 行为 |
|---|---|---|
global | 模块级 G 层 | 读写全局变量,多个函数共享 |
nonlocal | 嵌套外层 E 层 | 读写外层函数变量,多个闭包独立 |
五、闭包的完整执行流程
理解了nonlocal,我们再完整地看一遍闭包的执行流程。还是最初报错的代码,但这次我们先不加任何关键字:
def make_counter():
count = 0 # <- E 层变量
def counter():
print("count 当前值:", count) # 读 E 层变量 - 没问题
return count # 读 E 层变量 - 没问题
return counter
看到了吗?单纯的读操作(不加nonlocal)是不会报错的——Python允许读取外层变量。只有写操作(比如count = something或count += something)才会触发UnboundLocalError,因为等号左边让Python误以为你要创建一个新的L层变量。
当Python看到nonlocal count这行声明时,在编译期(生成字节码的阶段)就已经把这件事记录下来了:
import dis
def make_counter():
count = 0
def counter():
nonlocal count
count += 1
return count
return counter
# counter 函数的字节码
dis.dis(counter := make_counter())
关键字节码如下:
5 2 LOAD_GLOBAL 0 (count)
4 LOAD_CONST 1 (1)
6 BINARY_OP 0 (+)
8 STORE_FAST 0 (count)
10 LOAD_FAST 0 (count)
12 RETURN_VALUE
注意LOAD_GLOBAL 0 (count)这一行,这就是nonlocal的实现方式。如果没有nonlocal声明,这行会变成LOAD_FAST(试图读取L层变量),紧接着的STORE_FAST就会因为变量未定义而触发UnboundLocalError。
六、闭包变量的生命周期
闭包有一个容易被忽略但至关重要的特性:闭包变量的生命周期和闭包函数本身一样长。
def make_multiplier(factor):
# factor 绑定在 make_multiplier 的局部作用域里
def multiply(value):
return value * factor
return multiply
doubler = make_multiplier(2)
# make_multiplier() 已经执行完毕退出了
# 但 doubler 仍然持有 factor=2
print(doubler(5)) # 10
print(doubler(100)) # 200
factor原本是make_multiplier()的局部变量。按照常规,函数执行完毕,其局部变量就该被销毁了。但doubler还在引用它,所以Python的垃圾回收机制检测到factor仍有外部引用,就把它保留下来,并通过一个叫做cell的对象包装后,存入doubler.__closure__属性中。
这就是为什么我们能通过doubler.__closure__[0].cell_contents读取到2——cell对象就是闭包变量在内存中的载体。
>>> doubler.__closure__ (| ,) >>> doubler.__closure__[0].cell_contents 2 |
再看一个复杂点的例子,验证多个闭包如何共享同一个外层变量:
def processor(initial=0):
total = initial
def add(x):
nonlocal total
total += x
return total
def subtract(x):
nonlocal total
total -= x
return total
return add, subtract
add, subtract = processor(100)
print(add(30)) # 130,total = 100 + 30
print(subtract(20)) # 110,total = 130 - 20
print(add(10)) # 120,total = 110 + 10
add和subtract这两个闭包函数,指向的是同一个cell对象。因此,修改total对两个函数都生效。这种“共享状态”的特性,在事件处理器、回调函数等场景中非常有用。
七、闭包的典型应用场景
场景一:函数工厂(最常见用法)
根据不同的参数,动态生成具有特定功能的函数:
def power_factory(exp):
def power(base):
return base ** exp
return power
square = power_factory(2)
cube = power_factory(3)
print(square(5)) # 25
print(cube(5)) # 125
exp这个参数被捕获在各自的闭包里,square和cube拥有独立的exp值,互不干扰。相比为每种指数都写一个专门的函数,函数工厂的方式显然更灵活、更优雅。
场景二:带记忆的递归函数
def memoized_fibonacci():
cache = {} # E 层变量
def fib(n):
if n in cache:
return cache[n]
if n <= 1:
result = n
else:
result = fib(n-1) + fib(n-2)
cache[n] = result
return result
return fib
fib = memoized_fibonacci()
print(fib(100)) # 354224848179261915075
print(fib(200)) # 280571172992510140037611908417314019
cache字典在闭包中持久化,每次递归调用都能访问同一个缓存。这巧妙地避免了普通递归中,子问题被重复计算的巨大开销。
场景三:装饰器(闭包的直接应用)
装饰器本质上就是闭包的一个经典应用:
import functools
import time
def timing_decorator(fn):
@functools.wraps(fn)
def wrapper(*args, **kwargs):
# fn 和 elapsed_time 都是闭包变量
start = time.perf_counter()
result = fn(*args, **kwargs)
elapsed = time.perf_counter() - start
print(f"{fn.__name__} 耗时 {elapsed:.4f}s")
return result
return wrapper
wrapper函数捕获了两个自由变量:fn(被装饰的函数)和用于计时的变量。timing_decorator返回的wrapper闭包里,装着对被装饰函数的引用。当你调用被装饰后的函数时,实际执行的是这个wrapper。
八、闭包的常见错误:迟绑定
这是闭包概念里最隐蔽的一个坑。当闭包在循环中被创建时,所有闭包实例捕获的其实是同一个变量,而这个变量的值,是以闭包被调用时的值为准,而不是创建时的值:
def create_multipliers():
multipliers = []
for i in range(5):
multipliers.append(lambda x: x * i) # i 是自由变量
return multipliers
fns = create_multipliers()
# 全部返回 4*4=16,而不是 0*4, 1*4, 2*4, 3*4, 4*4
print([fn(4) for fn in fns]) # [16, 16, 16, 16, 16]
问题在于,循环结束时i = 4,而所有闭包引用的是同一个i。所以当它们被调用时,拿到的都是最终的4,结果自然都是4 * 4 = 16。
解决方法:利用默认参数在闭包创建时立即捕获当前值:
def create_multipliers_fixed():
multipliers = []
for i in range(5):
multipliers.append(lambda x, i=i: x * i) # i=i 把当前值绑定为默认值
return multipliers
fns = create_multipliers_fixed()
print([fn(4) for fn in fns]) # [0, 4, 8, 12, 16]
在lambda x, i=i: ...中,右边的i是自由变量,在定义时取值为当前的循环变量;左边的i是默认参数,被绑定到lambda的局部作用域。每次循环迭代,当前i的值都被“冻结”进默认参数,之后循环变量再怎么变化,也影响不到已经绑定好的值了。
使用functools.partial也能达到同样的效果:
import functools
def create_multipliers_partial():
multipliers = []
for i in range(5):
multipliers.append(functools.partial(lambda x, i: x * i, i=i))
return multipliers
九、__closure__与自由变量的深度解析
我们可以通过__code__.co_freevars属性,直接查看一个函数捕获了哪些自由变量:
def outer(x):
def inner(y):
# z 从更外层捕获
def deeper(z):
return x + y + z
return deeper
return inner
# 查看各层函数的自由变量
outer_fn = outer(10)
inner_fn = outer_fn(20)
deeper_fn = inner_fn(30)
>>> outer_fn.__code__.co_freevars
('x',)
>>> inner_fn.__code__.co_freevars
('x', 'y')
>>> deeper_fn.__code__.co_freevars
('x', 'y', 'z')
# __closure__ 的顺序和 co_freevars 一一对应
>>> deeper_fn.__closure__
(, , | )
>>> deeper_fn.__closure__[0].cell_contents, \
deeper_fn.__closure__[1].cell_contents, \
deeper_fn.__closure__[2].cell_contents
(10, 20, 30)
| | |
co_freevars是字节码层面的元信息,告诉解释器哪些名字是自由变量;而__closure__则是这些自由变量对应的cell对象序列,两者的顺序是完全一致的。
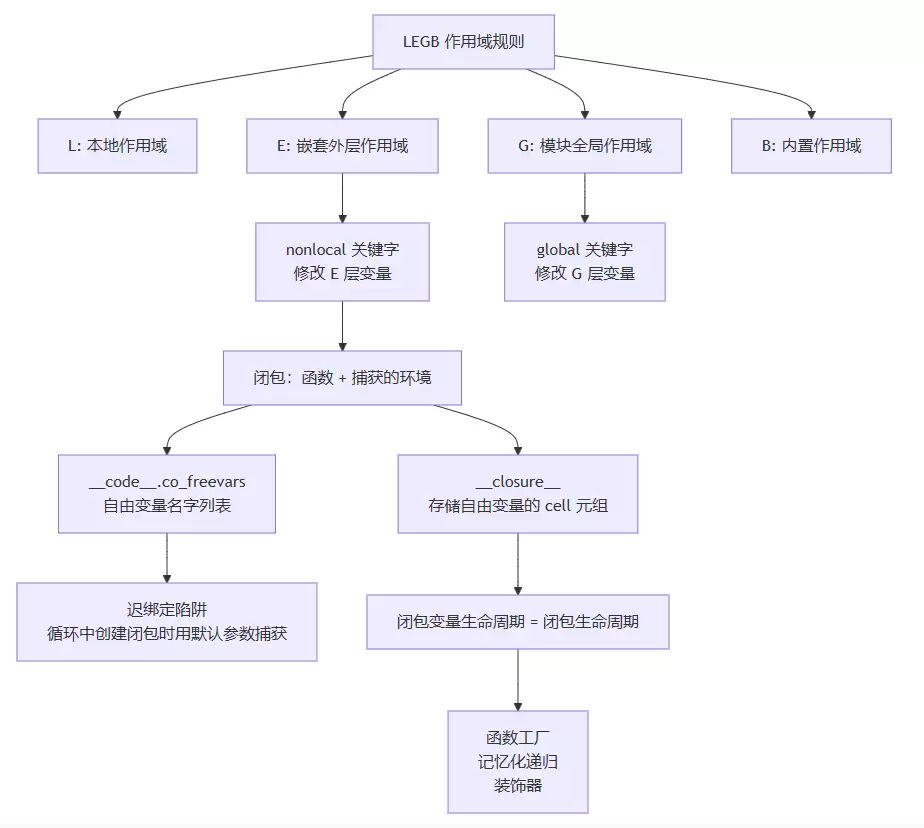
十、知识点总结
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- CentOS Java编译失败如何快速定位问题
- CentOS Ja va编译失败快速定位 在CentOS上编译Ja va项目时遇到报错,这事儿确实让人头疼。错误信息五花八门,但追根溯源,问题往往出在几个常见环节。下面这份从环境到代码的排查指南,能帮你快速锁定症结所在。 一 快速检查清单 遇到编译失败,先别急着逐行看代码。按照下面这个清单走一遍,十
- 12分钟前 0
-
 正版软件
正版软件
- 怎么通过 Collections.binarySearch() 在自定义对象数组列表中进行高效模糊匹配
- 怎么通过 Collections.binarySearch() 在自定义对象数组列表中进行高效模糊匹配 开门见山地说,Collections.binarySearch() 这个工具本身并不支持模糊匹配。它的设计初衷就是进行精确的二分查找,并且要求列表必须已经按照严格一致的排序规则升序排列。那么,如果
- 13分钟前 0
-
 正版软件
正版软件
- 怎么利用 Math.atan2() 结合坐标变量计算目标物体的真实方位角并处理象限判定
- Math.atan2(y, x):计算真实方位角的最优解 在需要计算目标方向或角度的场景里,Math.atan2(y, x)堪称是那个最直接、最可靠的“瑞士军刀”。它最大的魅力在于,能够根据纵轴偏移量(y)和横轴偏移量(x)的顺序,自动处理好所有象限和坐标轴上的特殊情况,最终给出一个范围在-180°
- 13分钟前 0
-
 正版软件
正版软件
- 怎么利用 ZoneId 处理不同时区的日期与时间转换
- 怎么利用 ZoneId 处理不同时区的日期与时间转换 ZoneId 是什么,它和 TimeZone 有什么区别 简单来说,ZoneId 是 Ja va 8 新时间 API 的“时区身份证”。它唯一标识一个时区,比如 "Asia/Shanghai" 或 "America/New_York"。这里有个关
- 13分钟前 0
-
 正版软件
正版软件
- CentOS Java编译环境的优化策略
- CentOS Ja va编译环境的优化策略 一 基础环境优化 一个稳固的地基,决定了上层建筑能有多高。对于Ja va编译环境而言,基础环境的配置就是那个地基。这一步没做好,后续的编译过程很可能磕磕绊绊,甚至反复失败。 安装编译与图形依赖:首先,得把“工具箱”备齐。执行 sudo yum groupi
- 14分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 240天前
-
4
- 探析Spring Boot框架的优点和特色
- 556天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 494天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 470天前
-
 7
7
-
 8
8
- Python实战教程:批量转换多种音乐格式
- 1102天前
-
9
- 如何在在线答题中实现试卷的自动批改和自动评分
- 929天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00