SpringBootCaffeine+Redisson配置二级缓存实践
 发布于2026-05-06 阅读(0)
发布于2026-05-06 阅读(0)
扫一扫,手机访问
问题说明
在高性能服务架构的设计中,缓存扮演的角色有多关键?相信每一位后端开发者都深有体会。通常,我们会把热点数据丢进Redis或MemCache这类远程缓存里,只有缓存没命中时,才会去查询数据库。这套经典玩法,既能大幅提升访问速度,又能有效给数据库“减负”。
不过,技术架构总是在演进。在某些对性能极其敏感的场景下,光靠远程缓存可能已经不够“快”了。于是,本地缓存(比如Gua va Cache或Caffeine)被引入进来,与远程缓存形成合力,共同将服务的响应性能推向新的高度。这就催生了一种典型的二级缓存架构:本地缓存作为反应最快的一级缓存,远程缓存作为容量更大、更可靠的二级缓存。
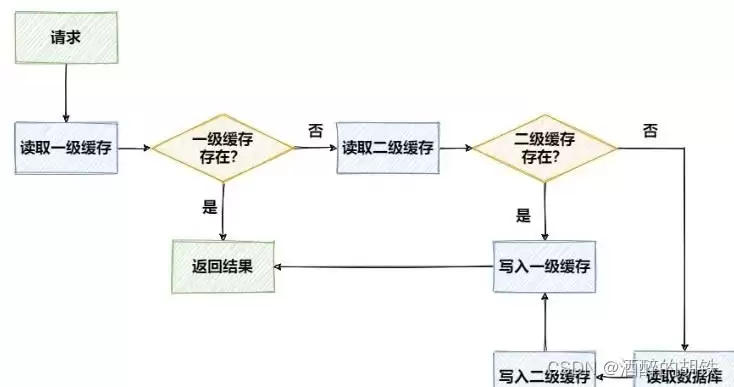
准备
要搭建这套体系,首先得把基础组件整合进来。这里以SpringBoot项目为例,需要集成Redisson作为远程缓存,并重写其CacheName的解析逻辑以支持多参数。同时,引入Caffeine作为本地缓存的核心依赖。
com.github.ben-manes.caffeine caffeine
配置文件
引入本地缓存的核心目的,是为了应对高并发场景下对Redis的频繁查询冲击。来看一个具体的配置:我们设定了expireAfterWrite策略,即最后一次写入或访问后,经过30秒固定时间过期。这意味着,假设一个页面被频繁刷新,在30秒内,无论刷新多少次,请求都会命中本地缓存。而且,即便在第29秒重新获取了数据,这个30秒的过期计时也会重新开始计算。
通过@EnableCaching注解来开启Spring的缓存功能,这个注解可以加在配置类上,也可以直接放在应用启动类上。
package com.example.redisson.config;
import com.example.redisson.manager.PlusSpringCacheManager;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.AutoConfiguration;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import ja va.util.concurrent.TimeUnit;
/**
* 缓存配置
*
* @author Lion Li
*/
@Configuration
@EnableCaching
public class CacheConfig {
/**
* caffeine 本地缓存处理器
*/
@Bean
public Cache caffeine() {
return Caffeine.newBuilder()
// 设置最后一次写入或访问后经过固定时间过期
.expireAfterWrite(30, TimeUnit.SECONDS)
// 初始的缓存空间大小
.initialCapacity(100)
// 缓存的最大条数
.maximumSize(1000)
.build();
}
/**
* 自定义缓存管理器 整合spring-cache
*/
@Bean
public CacheManager cacheManager() {
return new PlusSpringCacheManager();
}
}
装饰器
实现二级缓存的关键,在于如何优雅地让两者协同工作。这里采用装饰器模式对原有的Cache进行包装,有几个细节需要特别注意:
- Redisson的
put方法会自动加上cacheNames前缀。 - 而Caffeine本身并不使用
cacheNames,它的get- 为了解决不同
cacheNames下可能存在的key冲突问题,代码中增加了getUniqueKey方法,其核心逻辑是将cacheNames(通过getName()获得)与原始key拼接,形成一个全局唯一的键。 - 为了解决不同
简单来说,一个CacheName就对应一个被装饰的Cache对象。
package org.dromara.common.redis.manager;
import cn.hutool.core.lang.Console;
import org.dromara.common.core.utils.SpringUtils;
import org.springframework.cache.Cache;
import ja va.util.concurrent.Callable;
/**
* Cache 装饰器模式(用于扩展 Caffeine 一级缓存)
*
* @author Lion Li
*/
public class CaffeineCacheDecorator implements Cache {
private static final com.github.benmanes.caffeine.cache.Cache
CAFFEINE = SpringUtils.getBean("caffeine");
private final Cache cache;
public CaffeineCacheDecorator(Cache cache) {
this.cache = cache;
}
@Override
public String getName() {
return cache.getName();
}
@Override
public Object getNativeCache() {
return cache.getNativeCache();
}
public String getUniqueKey(Object key) {
return cache.getName() + ":" + key;
}
@Override
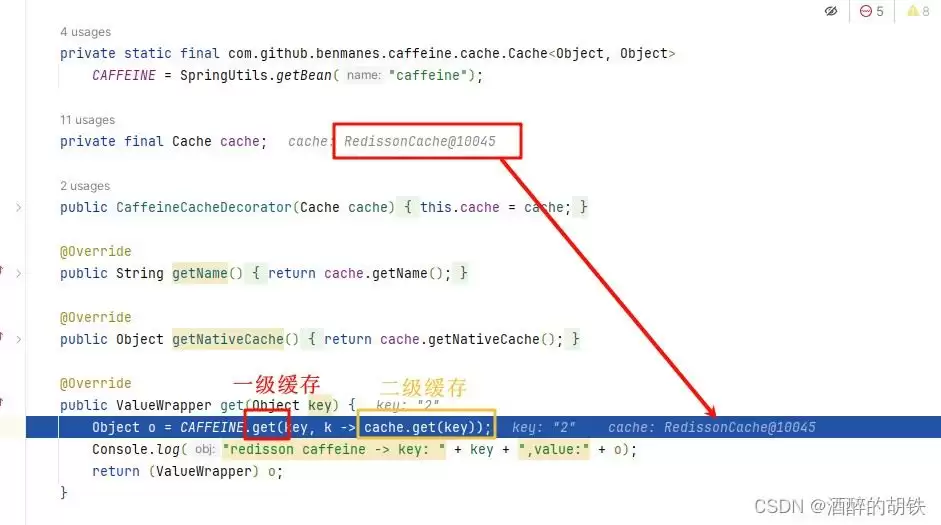
public ValueWrapper get(Object key) {
Object o = CAFFEINE.get(getUniqueKey(key), k -> cache.get(key));
Console.log("redisson caffeine -> key: " + getUniqueKey(key) + ",value:" + o);
return (ValueWrapper) o;
}
@SuppressWarnings("unchecked")
public T get(Object key, Class type) {
Object o = CAFFEINE.get(getUniqueKey(key), k -> cache.get(key, type));
Console.log("redisson caffeine -> key: " + getUniqueKey(key) + ",value:" + o);
return (T) o;
}
@Override
public void put(Object key, Object value) {
cache.put(key, value);
}
public ValueWrapper putIfAbsent(Object key, Object value) {
return cache.putIfAbsent(key, value);
}
@Override
public void evict(Object key) {
evictIfPresent(key);
}
public boolean evictIfPresent(Object key) {
boolean b = cache.evictIfPresent(key);
if (b) {
CAFFEINE.invalidate(getUniqueKey(key));
}
return b;
}
@Override
public void clear() {
cache.clear();
}
public boolean invalidate() {
return cache.invalidate();
}
@SuppressWarnings("unchecked")
@Override
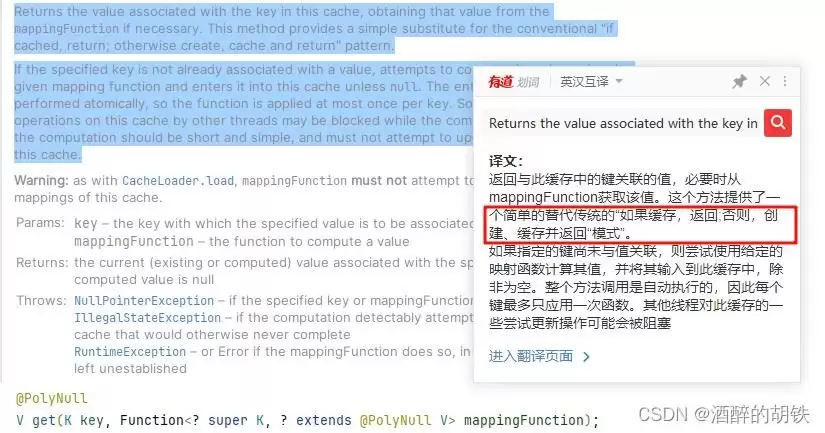
public T get(Object key, Callable valueLoader) {
Object o = CAFFEINE.get(getUniqueKey(key), k -> cache.get(key, valueLoader));
Console.log("redisson caffeine -> key: " + getUniqueKey(key) + ",value:" + o);
return (T) o;
}
}
修改自定义PlusSpringCacheManager,注入装饰器
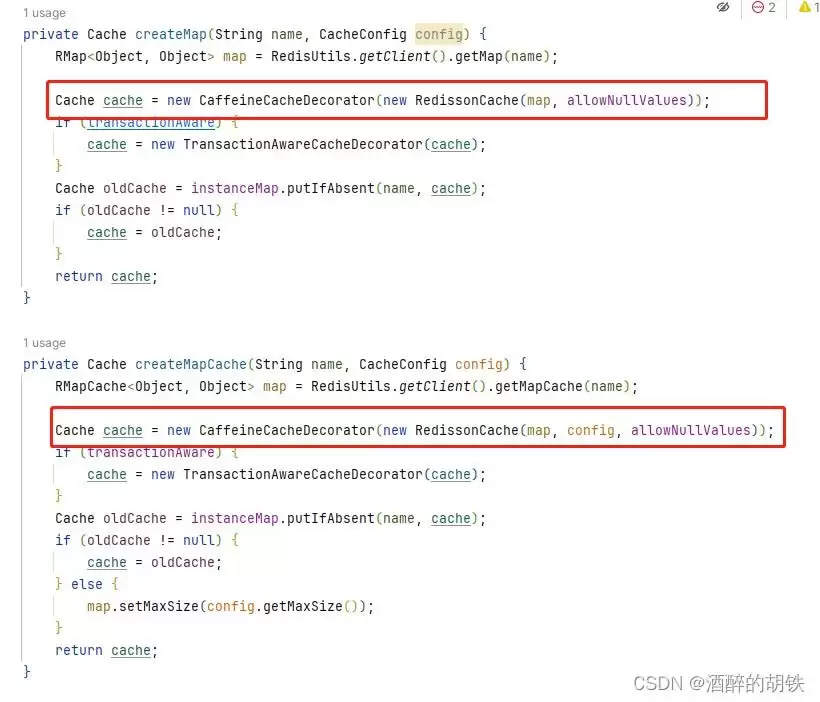
使用
配置完成后,在业务代码中的使用方式就非常直观了。直接使用Spring标准的@Cacheable注解即可。
@Cacheable(cacheNames = "demo:cache#60s#10m#20", key = "#key", condition = "#key != null")
@GetMapping("/test1")
public R test1(String key, String value) {
System.out.println("test1-->调用方法体");
return R.ok("操作成功", value);
}
这里有个关键点:@Cacheable注解在方法执行前就会触发get操作,因此能够顺利激活我们设计好的二级缓存链路。而@CachePut注解是执行方法后再放入缓存,因此其逻辑略有不同。
从上面的调用流程示意图可以清晰看到,请求会先查询一级本地缓存,如果未命中,则继续查询二级远程缓存。这正好印证了查看源码得出的结论:数据获取遵循“先本地,后远程”的优先级顺序。
缓存工具类
为了更方便地操作缓存,通常会封装一个工具类。下面这个工具类提供了对缓存组的键、值进行增删改查的通用方法。
package com.example.redisson.utils;
import lombok.AccessLevel;
import lombok.NoArgsConstructor;
import org.redisson.api.RMap;
import org.springframework.cache.Cache;
import org.springframework.cache.CacheManager;
import ja va.util.Set;
/**
* 缓存操作工具类 {@link }
*
* @author Michelle.Chung
* @date 2022/8/13
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
@SuppressWarnings(value = {"unchecked"})
public class CacheUtils {
private static final CacheManager CACHE_MANAGER = SpringUtils.getBean(CacheManager.class);
/**
* 获取缓存组内所有的KEY
*
* @param cacheNames 缓存组名称
*/
public static Set
总结
总的来说,通过装饰器模式整合Caffeine与Redisson,是实现SpringBoot项目二级缓存的一个清晰且有效的方案。它既保留了Spring Cache标准API的简洁性,又通过本地缓存极大提升了高频访问数据的读取性能。希望这套实践思路和具体代码,能为大家在构建高性能服务时提供一个可靠的参考。
您可能感兴趣的文章:
- SpringBoot+Caffeine+Redis实现多级缓存的方法
- SpringBoot 集成Caffeine实现一级缓存及常遇到场景
- SpringBoot整合Caffeine实现本地缓存的实践分享
- SpringBoot整合Caffeine使用示例
- SpringBoot使用Caffeine实现内存缓存示例详解
- 利用Springboot+Caffeine实现本地缓存实例代码
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
上一篇:Android字体字重设置全攻略
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- CentOS Java编译失败如何快速定位问题
- CentOS Ja va编译失败快速定位 在CentOS上编译Ja va项目时遇到报错,这事儿确实让人头疼。错误信息五花八门,但追根溯源,问题往往出在几个常见环节。下面这份从环境到代码的排查指南,能帮你快速锁定症结所在。 一 快速检查清单 遇到编译失败,先别急着逐行看代码。按照下面这个清单走一遍,十
- 12分钟前 0
-
 正版软件
正版软件
- 怎么通过 Collections.binarySearch() 在自定义对象数组列表中进行高效模糊匹配
- 怎么通过 Collections.binarySearch() 在自定义对象数组列表中进行高效模糊匹配 开门见山地说,Collections.binarySearch() 这个工具本身并不支持模糊匹配。它的设计初衷就是进行精确的二分查找,并且要求列表必须已经按照严格一致的排序规则升序排列。那么,如果
- 13分钟前 0
-
 正版软件
正版软件
- 怎么利用 Math.atan2() 结合坐标变量计算目标物体的真实方位角并处理象限判定
- Math.atan2(y, x):计算真实方位角的最优解 在需要计算目标方向或角度的场景里,Math.atan2(y, x)堪称是那个最直接、最可靠的“瑞士军刀”。它最大的魅力在于,能够根据纵轴偏移量(y)和横轴偏移量(x)的顺序,自动处理好所有象限和坐标轴上的特殊情况,最终给出一个范围在-180°
- 13分钟前 0
-
 正版软件
正版软件
- 怎么利用 ZoneId 处理不同时区的日期与时间转换
- 怎么利用 ZoneId 处理不同时区的日期与时间转换 ZoneId 是什么,它和 TimeZone 有什么区别 简单来说,ZoneId 是 Ja va 8 新时间 API 的“时区身份证”。它唯一标识一个时区,比如 "Asia/Shanghai" 或 "America/New_York"。这里有个关
- 13分钟前 0
-
 正版软件
正版软件
- CentOS Java编译环境的优化策略
- CentOS Ja va编译环境的优化策略 一 基础环境优化 一个稳固的地基,决定了上层建筑能有多高。对于Ja va编译环境而言,基础环境的配置就是那个地基。这一步没做好,后续的编译过程很可能磕磕绊绊,甚至反复失败。 安装编译与图形依赖:首先,得把“工具箱”备齐。执行 sudo yum groupi
- 14分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 240天前
-
4
- 探析Spring Boot框架的优点和特色
- 556天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 494天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 470天前
-
 7
7
-
 8
8
- Python实战教程:批量转换多种音乐格式
- 1102天前
-
9
- 如何在在线答题中实现试卷的自动批改和自动评分
- 929天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00