一文彻底掌握正则表达式到NFA、DFA的转换方法
 发布于2026-05-20 阅读(0)
发布于2026-05-20 阅读(0)
扫一扫,手机访问
正则表达式,这个在文本处理领域几乎无处不在的工具,其核心魅力在于它用一套简洁的符号系统,精准地描述了我们想要寻找的字符串模式。无论是验证用户输入的邮箱格式,还是从海量日志中提取特定错误信息,正则表达式都扮演着关键角色。然而,你是否想过,计算机是如何理解并执行这些看似抽象的规则的呢?这背后,正是形式语言理论中两个核心概念——非确定有限自动机(NFA)和确定有限自动机(DFA)在发挥作用。
1. 正则表达式概述及其应用
简单来说,正则表达式是一套用于描述字符串模式的语法规则。它由普通字符(如字母“a”)和特殊字符(称为元字符,如“*”、“|”)组合而成,能够定义复杂的搜索、匹配和替换规则。
在IT行业的实际工作中,正则表达式堪称效率神器。系统管理员用它快速筛选服务器日志;开发者在代码中用它进行数据验证和清洗;数据分析师则依靠它从非结构化文本中提取关键信息。掌握正则表达式,意味着你拥有了一把处理文本数据的瑞士军刀。
但知其然,更要知其所以然。接下来,我们将深入正则表达式的“引擎盖”下,看看它是如何通过NFA和DFA这些理论模型,最终被计算机理解和执行的。
2. 正则表达式与NFA、DFA的转换关系
正则表达式、NFA和DFA三者之间,存在着严谨的数学等价关系。简单来说,任何一个正则表达式,都可以转化为一个等价的NFA,而这个NFA又可以进一步转化为一个等价的DFA。理解这套转换流程,是洞悉正则表达式引擎工作原理的关键。
2.1 从抽象规则到状态机:正则表达式到NFA
将正则表达式转换为NFA,本质上是一个“翻译”过程:把人类易于理解的符号语言,翻译成机器易于处理的状态转移图。NFA的特点在于其“非确定性”:对于一个状态和输入,它可能有多条路径可选,甚至可以不消耗输入字符就进行状态跳转(即ε-转移)。这种灵活性让NFA的构造变得直观。
基础组件的映射
转换过程基于一套清晰的映射规则:
- 单个字符(如
a):被映射为一条从一个状态到另一个状态的转移边,边上标记为该字符。 - 连接操作(如
ab):将代表a和b的两个小NFA首尾相连。 - 选择操作(如
a|b):创建一个新的起始状态,通过ε-转移同时指向处理a和处理b的两个NFA分支。 - 克林闭包(如
a*):为处理a的NFA添加一条从结束状态指向开始状态的ε-转移边,形成一个循环。
通过组合这些基本规则,任何复杂的正则表达式都可以被系统地构建成一个NFA。
2.2 从非确定到确定:NFA到DFA的转换
虽然NFA易于构造,但其非确定性不利于直接编程实现。这时就需要DFA登场了。DFA的每个状态对于每个输入字符,都有且只有一条确定的转移路径,没有ε-转移。这种确定性使得DFA的运行效率极高。
将NFA转换为DFA,最常用的算法是子集构造法。其核心思想是:DFA的每一个状态,都对应NFA的一个状态集合。
- 初始化:DFA的起始状态,就是NFA起始状态的ε-闭包(即从该状态出发,仅通过ε-转移所能到达的所有状态的集合)。
- 状态扩展:对于当前DFA状态(一个NFA状态集合),考虑每个可能的输入字符。计算该集合中所有NFA状态经过此输入字符能到达的状态,再求这些状态的ε-闭包。这个新的闭包就构成了一个新的DFA状态。
- 迭代:重复上述过程,为所有新生成的DFA状态进行扩展,直到没有新的状态产生为止。
这个过程可能会产生大量的DFA状态(理论上是指数级),因此后续通常需要最小化DFA的步骤,合并等价状态,以优化其规模和效率。
2.3 一个完整的转换案例
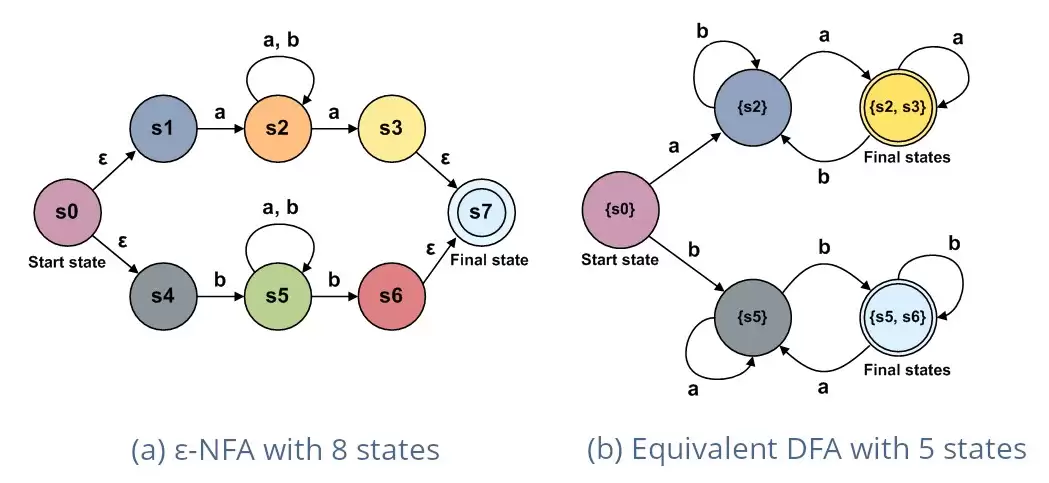
以正则表达式 (a|b)*abb 为例。首先,我们根据映射规则构造出其NFA:它会有分支处理 a 或 b,并有循环结构处理 *,最后连接上处理 abb 的线性路径。
接着,应用子集构造法。假设NFA起始状态为 {s}。读入字符 a 后,可能到达的状态集合是 {q0, q1}(这里仅为示意),这个集合就成为DFA的一个新状态。以此类推,逐步构建出完整的DFA状态转移表。最终得到的DFA,虽然状态数可能多于原NFA,但每个状态在面对输入 a 或 b 时,下一步都唯一确定。
2.4 转换的意义:从理论到实践的桥梁
掌握这套转换机制,其意义远不止于理解理论。实际上,许多编程语言的正则表达式引擎(如Perl、Python的re模块)在内部都会经历类似的转换过程,将用户输入的正则表达式先转化为NFA或DFA结构,再进行匹配。
对于开发者而言,理解这一点有助于:
- 编写高效的正则表达式:知道某些写法(如过度复杂的回溯)可能导致NFA状态爆炸或DFA最小化困难,从而避免性能陷阱。
- 深入理解编译原理:词法分析器(Lexer)的生成,本质上就是根据词法规则(正则表达式)生成DFA的过程。
- 调试复杂匹配问题:当正则表达式行为不符合预期时,在头脑中勾勒其对应的自动机状态图,往往是定位问题的有效方法。
graph LR
regex(正则表达式) -->|映射| nfa(NFA)
nfa -->|子集构造| dfa(DFA)
dfa -->|最小化| min_dfa(最小DFA)
min_dfa -->|应用| solution(高效匹配)
上图概括了从正则表达式到最终应用的核心转换与优化流程。
3. NFA和DFA:一对理论双生子
在深入转换细节前,有必要厘清NFA和DFA这对基本概念。它们是形式语言中定义“正则语言”的两种等价计算模型。
NFA:灵活但非确定
非确定有限自动机(NFA)由五个部分组成:状态集合、输入字母表、转移函数、起始状态和接受状态集。其“非确定性”体现在:
- 同一状态对同一输入,可以有多条转移路径。
- 允许ε-转移,即不消耗输入字符即可改变状态。
NFA接受一个字符串的条件是:存在至少一条路径,从起始状态开始,消耗完所有输入字符后,停留在某个接受状态。这种“存在性”判断是其非确定性的体现。
DFA:直接而确定
确定有限自动机(DFA)同样由五部分组成,但其转移函数是确定的:对任意状态和输入字符,有且仅有一个后继状态。DFA没有ε-转移。
DFA接受字符串的条件则非常直接:从起始状态开始,依次根据输入字符进行确定的状态转移,读完所有字符后,若处于接受状态,则接受该字符串。整个过程是唯一且确定的。
对比与等价性
尽管行为方式不同,但NFA和DFA在能力上是等价的,即它们能识别的语言集合完全相同(都是正则语言)。它们的区别主要体现在:
- 构造难度:为同一个语言构造NFA通常比构造DFA更简单、直观。
- 运行效率:DFA的确定性决定了其匹配速度通常快于NFA,因为不需要管理多条可能的路径或进行回溯。
- 空间占用:DFA的状态数可能远多于等价的NFA(子集构造法的结果),但经过最小化后,其效率优势往往能弥补空间开销。
理解它们的特性,就能明白为何在实践中,我们常常通过NFA来“设计”,再通过转换为DFA来“实现”以获得最佳性能。
4. 构造NFA的基石:规则与ε-转换
要手动或自动地将正则表达式转化为NFA,需要遵循一套系统的构造规则,而ε-转换在其中扮演了“粘合剂”的角色。
NFA的构造规则
构造过程是递归的,从最基本的单元开始组合:
- 基本字符:正则表达式中的单个字符
a,构造为一个具有两个状态(起始和接受)的NFA,中间有一条标记为a的转移边。 - 连接(R1R2):将R1的接受状态与R2的起始状态通过ε-转移连接,使R1结束后能无缝进入R2。
- 选择(R1|R2):创建新的起始状态和接受状态。从新起始状态出发,通过ε-转移分别指向R1和R2的起始状态;R1和R2各自的接受状态也通过ε-转移指向新的接受状态。
- 克林闭包(R*):创建新的起始状态和接受状态。首先,新起始状态通过ε-转移指向R的起始状态,也直接指向新接受状态(表示零次匹配)。其次,R的接受状态通过ε-转移指回R的起始状态(实现循环),同时也指向新接受状态。
ε-转换:无形的桥梁
ε-转换,即空转移,是上述构造规则得以实现的关键。它不匹配任何实际输入字符,其作用纯粹是在状态之间建立逻辑连接。
以构造 a(b|c)* 的NFA为例:首先构造字符 a 的NFA。然后构造 b|c 的选择结构,这需要ε-转换来创建分支。接着,对这个选择结构应用克林闭包 *,这需要增加ε-转换来形成从结束到开始的循环,以及从开始直接到结束的“跳过”路径。最后,通过ε-转换将这几部分连接起来。
ε-转换极大地简化了NFA的构图逻辑,让复杂的组合变得清晰。在编程实现中,它通常体现为对状态集合的操作(如求ε-闭包),而非显式的图形绘制。
// 伪代码示例:表示一个简单的NFA状态及其ε-转移
class NFATransition {
Symbol symbol; // 转移符号,可为ε
NFAState target;
}
class NFAState {
List transitions;
boolean isAccepting;
}
5. 转换的核心:ε-闭包与子集构造法
将带有ε-转换的NFA转换为DFA,是整个过程最具技巧性的环节,其核心在于对“ε-闭包”的反复计算。
5.1 ε-闭包:定义与计算
ε-闭包 是理解转换的钥匙。对于一个NFA状态集合S,其ε-闭包定义为:从S中任意状态出发,仅通过若干条ε-转移所能到达的所有状态的集合。计算ε-闭包是一个典型的图遍历过程(如深度优先搜索)。
在子集构造法中,我们操作的单元不再是单个NFA状态,而是其ε-闭包。DFA的起始状态,就是NFA起始状态的ε-闭包。
5.2 子集构造法:一步步构建DFA
算法可以概括为以下几步:
- 初始化:令DFA的初始状态
D0= ε-closure( NFA起始状态 )。将D0加入未处理队列。 - 处理状态:当队列非空时,取出一个DFA状态
D(它是一个NFA状态集合)。 - 计算转移:对于字母表中的每个输入字符
a:- 计算
move(D, a)= 从D中任一状态出发,经过一条标记为a的边所能到达的所有NFA状态的集合。 - 计算
U = ε-closure( move(D, a) )。这个U就是一个新的DFA状态(可能已存在)。 - 建立从DFA状态
D到状态U的转移,标记为a。 - 如果
U是新的状态集合,则将其加入未处理队列。
- 计算
- 标记接受状态:如果某个DFA状态(即NFA状态集合)中包含至少一个NFA的接受状态,则该DFA状态为接受状态。
重复步骤2和3,直到所有DFA状态都被处理完毕。最终得到的状态转移表,就定义了一个完整的DFA。
5.3 状态爆炸与优化
子集构造法最坏情况下会产生指数级数量的DFA状态(相对于原NFA状态数)。为了应对这一问题,产生了两种主要策略:
- 惰性计算/按需构造:并不一次性构造整个DFA,而是在匹配过程中,根据实际输入的字符流,动态计算和生成所需的状态转移。这节省了初始化的时间和空间。
- DFA最小化:在构造完成后,通过算法(如Hopcroft算法)合并所有等价状态,得到状态数最少的唯一最小DFA。这能显著降低最终自动机的复杂度。
6. DFA的优势与转换实践
经过一系列转换,我们最终得到了DFA。那么,它的优势究竟体现在哪里?
DFA的确定性优势
- 匹配速度极快:对于输入字符串中的每个字符,DFA只需做一次状态转移查表操作,时间复杂度是O(n)。没有回溯,没有尝试多条路径的开销。
- 实现简单稳定:DFA可以很容易地用二维数组(状态转移表)或哈希表实现,运行行为完全可预测。
- 资源消耗确定:内存占用在构造完成后即固定,不会因输入不同而有巨大波动。
正因如此,在需要高性能匹配的场景(如网络入侵检测系统IDS、高性能词法分析器),往往会选择将正则表达式编译为DFA形式。
从正则表达式到DFA的代码实践
虽然现代编程语言的正则引擎封装了这些细节,但了解其原理对深入使用大有裨益。以下是一个高度简化的概念性代码框架,展示了从正则表达式到DFA的转换流程:
# 概念性伪代码框架,展示核心步骤
def regex_to_dfa(regex_str):
# 1. 解析正则表达式,生成抽象语法树(AST)
ast = parse_regex(regex_str)
# 2. 递归应用Thompson构造法,从AST构建NFA
nfa = thompson_construction(ast)
# 3. 使用子集构造法,将NFA转换为DFA
dfa_states, dfa_transitions = subset_construction(nfa)
# 4. (可选) 最小化DFA
minimized_dfa = minimize_dfa(dfa_states, dfa_transitions)
return minimized_dfa
# 使用DFA进行匹配
def dfa_match(dfa, input_string):
current_state = dfa.start_state
for char in input_string:
if char not in dfa.alphabet:
return False # 字符不在字母表内,立即失败
current_state = dfa.transition_table[current_state][char]
if current_state is None:
return False # 无转移定义,匹配失败
return current_state in dfa.accepting_states
在实际的编译器(如Lex)或库中,步骤1和2可能合并,并且有大量的优化技巧。但万变不离其宗,其核心思想依然是:正则表达式 -> NFA -> DFA -> 最小化DFA -> 高效匹配引擎。
总结
正则表达式到NFA再到DFA的转换,是一条连接抽象模式与高效计算的坚实桥梁。从理解正则表达式的基本组件映射为NFA片段,到利用ε-转换和子集构造法将灵活的NFA“确定化”为高效的DFA,整个过程充满了算法之美。
对于开发者而言,掌握这套理论并非为了手动进行转换,而是为了建立一种深层直觉:当你写下一条复杂的正则表达式时,你能大致预判其性能特征,避免常见的陷阱(如灾难性回溯);当匹配行为不符合预期时,你能从状态机的角度去分析和调试。
正则表达式不仅仅是工具,它背后是形式语言与自动机理论的优雅体现。理解这套转换机制,无疑会让你在文本处理的战场上,从“使用者”进阶为“洞察者”。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- C++ std::sort底层使用内省排序(Introsort)
- std::sort底层采用内省排序(Introsort):小数组用插入排序,递归过深时切堆排序,兼顾性能与最坏O(nlogn)保障;主流实现(libstdc++、libc++、MSVC)均如此,但标准仅规定复杂度,未强制算法。
- 22分钟前 0
-
 正版软件
正版软件
- C++时间戳日志滚动与命名策略实现
- 正确配置需规避时区/时钟跳变/命名撕裂/重命名失败四大陷阱:log4cplus设TimeZone=UTC并重写rollover()按日志时间戳命名;spdlog禁用自动重开,用daily_logger_mt配0点滚动并在回调中flush()+drop();命名须基于日志事件时间戳而非触发时间;rename失败时需robust_rename()兜底。
- 27分钟前 0
-
 正版软件
正版软件
- PHP header() 函数实现页面跳转方法
- PHP中header("Location:...")重定向失败通常是因为响应头已发送(如存在输出、空格、BOM或错误提示),导致HTTP头无法修改;必须确保调用前无任何输出,并在header()后立即执行exit或die。
- 32分钟前 0
-
 正版软件
正版软件
- CentOS Python机器学习如何实现
- 在CentOS上搭建Python机器学习环境需遵循清晰步骤:安装并更新系统,安装Python3及pip包管理器。建议创建虚拟环境以隔离依赖,随后安装NumPy、Pandas、Scikit-learn、TensorFlow或PyTorch等核心库。最后通过运行简单代码验证环境是否正常工作,确保整个工具链畅通。
- 37分钟前 0
-
 正版软件
正版软件
- CentOS上Python安装注意事项
- 在CentOS系统上安装Python时,应优先使用系统包管理器以确保兼容性。若需特定版本而进行源码编译,务必提前安装完整的开发依赖包,并注意解决OpenSSL版本问题。严禁替换系统默认Python,编译时应使用`makealtinstall`。安装后需正确配置环境变量,并推荐使用虚拟环境隔离项目依赖。最后验证安装结果,确保环境可用。
- 37分钟前 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 254天前
-
4
- 探析Spring Boot框架的优点和特色
- 570天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 508天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 484天前
-
 7
7
-
 8
8
- Python实战教程:批量转换多种音乐格式
- 1116天前
-
9
- 如何在在线答题中实现试卷的自动批改和自动评分
- 944天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00