Excel中match函数的实用技巧
 发布于2025-11-24 阅读(0)
发布于2025-11-24 阅读(0)
扫一扫,手机访问
match函数用于查找值在向量中的位置,返回索引,R中用match(),Python常用pandas或numpy模拟;可快速定位元素、对齐数据,如match(c("apple", "banana"), c("orange", "apple", "grape", "banana"))返回c(2, 4),提升数据处理效率。
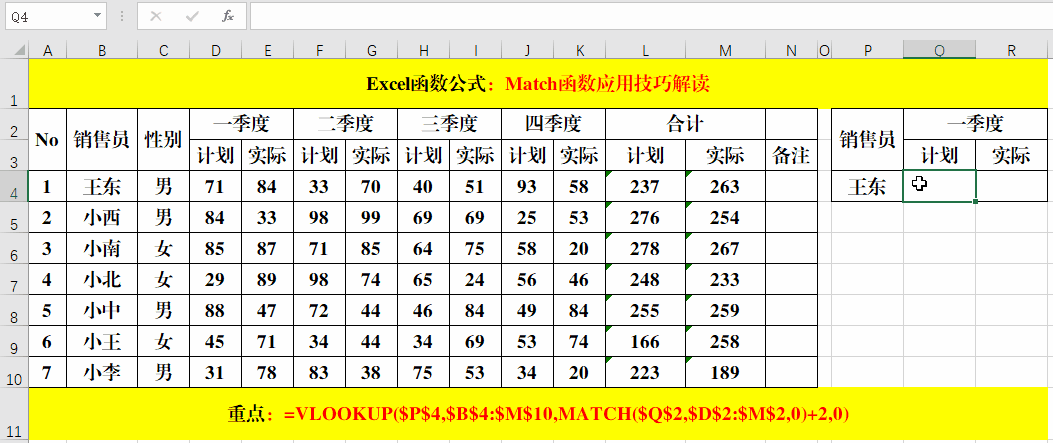
在数据科学中,match函数虽然看似简单,但在数据清洗、特征对齐和索引查找等任务中非常实用。它主要用于查找一个值或一组值在向量中的位置,返回匹配元素的索引。不同语言中实现略有差异,比如R语言有内置的match()函数,而Python中通常通过pandas的map()、isin()或numpy.where()模拟类似功能。掌握其使用技巧,能显著提升数据处理效率。
快速查找元素位置
当你需要确定某些值在另一个数组或列中的位置时,match函数可以快速完成任务。例如,在R中:
match(c("apple", "banana"), c("orange", "apple", "grape", "banana"))返回结果是 c(2, 4),表示“apple”在第2位,“banana”在第4位。如果值不存在,默认返回NA。这一特性可用于构建映射表或检查数据完整性。
实现高效的数据对齐
在合并两个数据集但缺少直接键字段时,可以用match函数进行间接对齐。比如,你有一个用户ID列表和另一个包含用户姓名与ID对应关系的表格,可以通过match()将姓名按顺序对应回ID位置,避免使用耗时的循环或合并操作。
示例(R语言):
user_names <- c("Alice", "Bob", "Charlie")lookup_table <- data.frame(name = c("Bob", "Alice", "David"), id = c(101, 102, 103))
indices <- match(user_names, lookup_table$name)
result_ids <- lookup_table$id[indices]
这样就能得到每个用户名对应的ID,即使顺序不一致也能正确匹配。
处理缺失值与重复项
match函数只返回第一次匹配的位置,这对于处理重复值很重要。如果你的数据中有重复标签或ID,match()只会返回首个匹配索引,其余忽略。这在去重或建立唯一映射时很有用。
同时,利用其返回NA的特性,可以快速识别哪些值未在目标向量中出现。结合is.na()判断,能有效筛选出异常或缺失条目:
上述代码可标记出所有不在合法分类中的记录,便于后续清洗。
替代merge提升性能
当仅需从一个查找表提取单个字段时,使用match()比merge()更轻量、更快。尤其在处理大型数据框且只关心一列映射时,match配合向量化索引访问能大幅减少内存开销和运行时间。
例如,在Python pandas中虽无直接match,但可通过以下方式模拟:
mapping = pd.Series(df2.index.values, index=df2.name)
indices = mapping[df1.names].values
df1['id'] = df2['id'].iloc[indices]
这种方法本质就是match逻辑的实现,执行效率高于全表join。
基本上就这些。合理使用match函数,不仅能简化代码逻辑,还能在数据预处理阶段显著提升响应速度。关键是理解其返回索引的本质,并灵活结合其他向量化操作使用。不复杂但容易忽略。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
下一篇:上海停车app预约教程详解
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- Linux系统安装Kubernetes Dashboard 可视化管理面板教程【详解】
- 默认部署KubernetesDashboard后服务类型为ClusterIP,无法从外部访问。需将Service类型改为NodePort并指定30000-32767范围内的端口,才能通过浏览器直接访问。登录失败常因缺少权限绑定、token过期或命名空间错误。临时调试可使用port-forward,但生产环境不推荐。部署前需确保集群基础配置正确,避免后续问题。
- 昨天 05-06 16:25 0
-
 正版软件
正版软件
- Mac怎么清理磁盘空间中的“可清除”部分
- Mac“可清除”空间未自动释放时,可通过系统设置主动清理。开启iCloud照片与邮件优化,利用终端删除TimeMachine本地快照,启用系统自动管理功能清理缓存与废纸篓。还可通过终端命令刷新储存空间数据,或在安全模式下强制清理系统缓存。按顺序尝试这些方法,通常能有效释放被占用的空间。
- 昨天 05-06 16:25 0
-
 正版软件
正版软件
- Mac怎么添加法语/德语/日语等小语种输入法 苹果设置
- 在Mac上添加小语种输入法,需进入系统设置的键盘选项,在输入源中添加目标语言。添加后,建议启用菜单栏图标以显示当前输入法,并设置快捷键以便在不同语言间快速切换。整个过程直观便捷,能有效提升多语言输入效率。
- 昨天 05-06 16:25 0
-
 正版软件
正版软件
- 如何解决 Win11 系统由于输入法候选框遮挡关键 UI 导致的交互问题
- Windows11输入法候选框遮挡界面时,可尝试五种方法解决:启用微软拼音兼容性模式以稳定显示;关闭全屏或非焦点状态下的输入法界面显示;禁用全局输入法切换快捷键避免误触;针对特定应用关闭全屏优化与硬件加速;重置微软拼音输入法位置与UI配置恢复默认。
- 昨天 05-06 16:24 0
-
 正版软件
正版软件
- 如何在 Windows 11 任务管理器中显示 NPU 频率 监控 AI 硬件占用率方法
- 自Windows11Build26300.8142预览版起,任务管理器新增了多项NPU监控功能。用户可在进程页面添加“NPU使用率”和“NPU引擎”列,或在详细信息页面启用“NPU专用内存”等列,以查看各进程的AI硬件占用情况。性能页面则提供全局NPU活动状态,包括实时使用率与引擎类型。此外,可通过PowerShell查询设备信息,或启用“隔离”列辅助判断A
- 昨天 05-06 16:23 0
最新发布
-
 1
1
- 《抖音》充值抖币官网入口
- 522天前
-
 2
2
- 大麦网官网订票入口
- 416天前
-
 3
3
- 直接点击打开漫蛙网页版
- 532天前
-
 4
4
- 天堂漫画免费入口及最新观看链接
- 204天前
-
 5
5
- 喵趣漫画官网
- 524天前
-
 6
6
- B站免费入口长期可用指南
- 265天前
-
 7
7
- 中国裁判文书网官网入口查询
- 192天前
-
 8
8
- 58动漫网入口及永久访问方法
- 149天前
-
 9
9
- B站免费入口永久有效网址推荐
- 238天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00