DeepSeek上线专家模式:国产AI激战正酣,V4能否复刻去年春节炸场?
 发布于2026-04-25 阅读(0)
发布于2026-04-25 阅读(0)
扫一扫,手机访问
国产大模型DeepSeek再次迎来重要更新
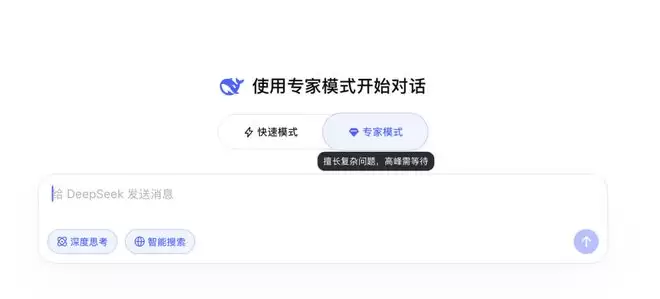
新一轮的消息来了。4月8日,细心的用户在访问DeepSeek时发现,输入框上方悄然出现了“快速模式”与“专家模式”两个选项。根据网页说明,快速模式主打日常对话,响应迅捷,同时支持图片和文件中的文字识别;而专家模式则专为处理复杂问题而生。这是DeepSeek首次在正式页面中,向公众明确引入这种分层服务模式。
这一改动,无疑让业界对DeepSeek V4版本的期待值再度拉满。综合外媒报道与各路社区讨论来看,几乎可以确定,DeepSeek有极大概率会在今年4月正式推出V4模型。
宕机风波背后的更新预兆
其实,早前的一些迹象已经透露出端倪。回顾3月29日至31日,DeepSeek的服务连续三天出现不同程度的异常,波及网页对话、App及API接口。三次故障分别持续了约1小时48分、10小时13分和1小时3分。最严重的一次发生在29日夜间10点,一直持续到次日早上7点,出现了长达8小时的大规模访问异常,不少用户遭遇了页面卡顿、反复提示“服务器繁忙”,甚至服务完全中断的情况。
外界普遍将这次大规模宕机与V4版本的更新部署联系起来。对于这种猜测,DeepSeek内部人士并未直接证实,而是向澎湃新闻记者给出了一个充满遐想的回应:“非常期待。”话虽简短,意味却深长。
技术论文与长文本测试,铺垫已久
技术上的铺垫其实早就开始了。今年1月12日,DeepSeek与北京大学合作发表了一篇题为《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》的论文,公司创始人梁文锋的名字位列作者之中。这篇论文的核心,直指当前大语言模型普遍存在的“记忆力”短板,并提出了一套名为“条件记忆”的新解决方案。
紧接着在2月13日,有消息透露,DeepSeek的网页和App端正在内测全新的长文本模型结构,上下文支持能力高达1M(约100万字)。不过,当时的API服务仍维持在V3.2版本,仅支持128K上下文。这一动作曾让市场猜测,DeepSeek或许会复刻去年春节的“炸场”效应,在龙年春节再次发布重磅模型。
然而,尽管春节期间的AI市场热闹非凡,DeepSeek却始终按兵不动,让外界的期待暂时落了空。
V4使命:在深水区复刻轰动
那么,即将到来的V4究竟承载着怎样的期待?根据多家券商研报分析,DeepSeek V4的亮点将聚焦于“国产化”与“技术创新”。野村证券的分析指出,作为去年凭借DS-V3/R1系列搅动全球AI产业链的玩家,DeepSeek的全新技术布局,不仅意在推动国内AI产业链创新周期加速,更旨在从算法与工程层面,实质性缩小中美大模型产业的技术差距。
不过,业内也有清醒的认识。此次V4的发布,对DeepSeek而言挑战不小。想要复刻去年春节那般现象级的轰动,技术难度远超以往。原因很简单:当下的国产大模型赛道,早已不是蓝海,而是卷入了各方巨头林立、竞争白热化的“深水区”。
竞争格局:从价格战到价值战
就在同一天,4月8日,另一家巨头智谱正式发布了GLM-5.1模型。值得关注的是,在年内已经涨价超过80%的基础上,智谱GLM的定价再度上调了10%。调价后,其在编程场景的缓存命中Token价格,已经接近国际头部厂商Anthropic旗下Claude Sonnet 4.6的水平。
这标志着一个关键的转折点:国产大模型首次在核心应用场景实现了与海外领先产品的价格对标。回想一年前,国内厂商还在以“降价90%以上”的惨烈策略争夺市场份额。如今,风向已然转变——国产模型不再单纯依赖价格优势,而是开始凭借性能提升带来的溢价,去锚定国际基准。这无疑是一场从“价格战”到“价值战”的深刻演变。
性能数据也支撑了这一转变。数据显示,GLM-5.1在编程能力上继续保持领先,在SWE-bench Pro、Terminal-Bench、NL2Repo三大代码评测基准的综合平均分中,取得了全球第三、国产第一、开源第一的成绩。此外,它还有一个显著特点:区别于当前主流模型以分钟级交互为主,GLM-5.1能够在单次任务中持续、自主地工作长达8小时。
路径分化:Agent与自我进化
竞争不止于性能与定价,技术路径也在分化。早在3月18日,MiniMax就发布了新一代Agent旗舰大模型M2.7,首次清晰地展示了“模型自我进化”的独特技术路线。该模型通过构建一套名为Agent Harness的体系,让模型自身深度参与到训练与优化流程中。据称,在部分研发场景下,该模型可承担30%至50%的工作量,并在内部评测集上实现了约30%的效果提升。
在核心能力上,M2.7在SWE-bench Pro中取得了56.22%的成绩,已接近国际一线水平;同时在VIBE-Pro、Terminal Bench2等更贴近真实工程的测试中表现突出,支持端到端的项目交付与复杂系统理解。在办公场景,其在GDPval-AA的ELO得分达到1495,为开源模型中最高,其Office文档处理与多轮编辑能力也得到了显著增强。
市场回应:资本用脚投票
市场的反应是最直接的信号。截至4月8日港股午间收盘,智谱股价大涨14.06%,报收888.5港元,市值达到3961亿港元。MiniMax股价也上涨了6.9%,报收1015港元,市值维持在3183亿港元的高位。资本的这番“用脚投票”,清晰地表明了市场对国产大模型技术突破与商业价值提升的认可与期待。
可以说,DeepSeek V4的即将登场,并非一场孤立的发布,而是整个国产大模型产业进入新阶段的标志性事件之一。当厂商们纷纷告别低价厮杀,转向核心技术突破与价值深耕时,一场真正关乎未来格局的较量,才刚刚开始。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 下坠的中产,正在批量逃离“陪读天堂”
- 孩子从清迈回到广州上学的第6个月,李女士做了一个梦。梦里,有清迈一如既往的鸟叫声,贯穿了儿子曾经上课的蒙特梭利学校手工课教室,儿子在室外看着她,忽然哇哇大哭:“妈妈,我想回学校。” “然后我就带着孩子从广州回到了清迈。”李女士说。 2024年,李女士带着3岁的儿子前往泰国上学,后因夫妻异地短暂回到广
- 15分钟前 0
-
 正版软件
正版软件
- 全球89%消费者计划持续购买二手商品;2025年全球智能眼镜市场出货量同比增长44.2%;印尼计划提高可再生能源生产
- 新兴市场动态 先说个核心判断:新兴市场的政策风向正在发生一些微妙而关键的转变。这不,东南亚和拉美就有几个动作值得仔细咂摸。 1、印尼计划提高可再生能源生产 联合早报最新消息,印度尼西亚政府正在下一盘“节能增效”的大棋。为了缓冲中东冲突对本国经济的冲击,他们打算从能源开支里省出80万亿印尼盾(约合60
- 18分钟前 0
-
 正版软件
正版软件
- 桌面CNC能复制3D打印的神话吗?
- 桌面CNC,这个一度沉寂的赛道,如今正悄然升温。 一个明显的信号是,回顾2025年全球众筹市场,在为数不多的、金额突破千万美金的七个明星项目中,竟有两个席位被略显冷门的桌面CNC产品占据。 其中,中国品牌造物时代旗下的Makera Z1,以高达1024.51万美元的成绩,一举刷新了CNC品类的全球众
- 19分钟前 0
-
 正版软件
正版软件
- 美团和滴滴,巴西争论不休
- 3月31日,巴西经济防御行政委员会(Cade)总秘书处的一纸公告,将一场酝酿已久的商战推至台前。公告显示,应美团旗下Keeta公司的申请,Cade正式对滴滴旗下99Food涉嫌的反竞争行为启动行政调查。 消息本身不算意外,更像是靴子落地。这场调查其实早有铺垫。 早在去年,当Keeta尚未在巴西正式上
- 20分钟前 0
-
 正版软件
正版软件
- 10%营业额罚款的背后:韩国数据监管,已经进入董事会层面
- 问题从来不只是“被攻击” 回顾修法前后的一个背景是,韩国市场接连曝出几起颇具代表性的数据泄露案。比如,有金融机构将居民登记号这样敏感的信息,直接用明文写进日志系统,最终导致数百万条用户数据暴露。再比如,一些品牌因为访问控制和身份认证过于薄弱,被攻击者长驱直入,直接拿到了客户数据库。还有的平台型企业,
- 20分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 518天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 525天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 536天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 828天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 544天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2322天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00