内存通胀“终结者”?谷歌公开最新极限压缩算法
 发布于2026-04-25 阅读(0)
发布于2026-04-25 阅读(0)
扫一扫,手机访问
要破解大模型面临的算力难题,降低其训练和运行时所需的存储与计算空间,路径其实不少。关键是要理清:痛点究竟是在训练环节,还是在推理环节?市面上主流的稀疏化、量化、模型压缩与知识蒸馏等技术,各有侧重,而不同的研究机构和模型厂商,也基于自身的技术栈和场景需求,选择了不同的突破方向。
就拿让许多模型头疼的长上下文任务来说吧。过去两年,业内算法团队的一个主流思路,是围绕“键值缓存”做文章,提出了分离式架构设计——也就是根据预填充和解码的不同计算特性,将它们分别部署到不同的服务器上。但这种方案在应对大批次处理和排队场景时,对系统内存带宽提出了更高要求。说白了,对于很多推理任务而言,真正的瓶颈往往不在于算得快不快,而在于数据从内存里“搬”得够不够快。
今天,谷歌推出了一项名为TurboQuant的新算法,瞄准的正是这个核心痛点:大模型运行时恐怖的内存消耗。它的目标很明确,就是让AI在“思考”和“回答”时,占用少得多的工作内存,同时还能保持几乎等价的智力水平,甚至反应更快。
这项技术的潜在影响是显而易见的。在模型推理侧,处理百万级Token上下文的成本有望显著下降;对于向量数据库,实时索引和亚毫秒级查询将更容易实现;而在边缘AI领域,手机和嵌入式设备运行长上下文推理也不再是遥不可及的幻想。此外,这一思路完全可以延伸到多模态领域,用于向量数据的压缩。
市场总是最敏锐的。就在这项技术发布的当天,美股存储板块,包括美光科技、闪迪等公司的股价应声下跌。近几年,受全球数据中心建设热潮的推动,内存、固态硬盘等存储产品一度供应紧张、价格高企。市场的这一反应不难理解:一旦TurboQuant这类技术得到广泛应用,未来AI推理服务器对内存容量规格的需求预期将被重塑,整个硬件成本曲线可能因此改变。
要真正理解TurboQuant的价值,得先弄明白大模型生成文本的基本原理。它们并非一下子吐出整段话,而是像我们人类边想边说,一个字一个字地往外“蹦”。在这个过程中,模型需要一个“临时记事本”,用来记住之前所有对话或文本的内容,避免对相同信息反复计算。这个技术上的“记事本”,就是键值缓存。麻烦在于,对话越长,“记事本”就越厚,对昂贵的高性能内存的占用也就越惊人。在处理超长文档或复杂多轮对话时,KV Cache会迅速成为拖慢AI速度、推高运行成本的主要瓶颈。
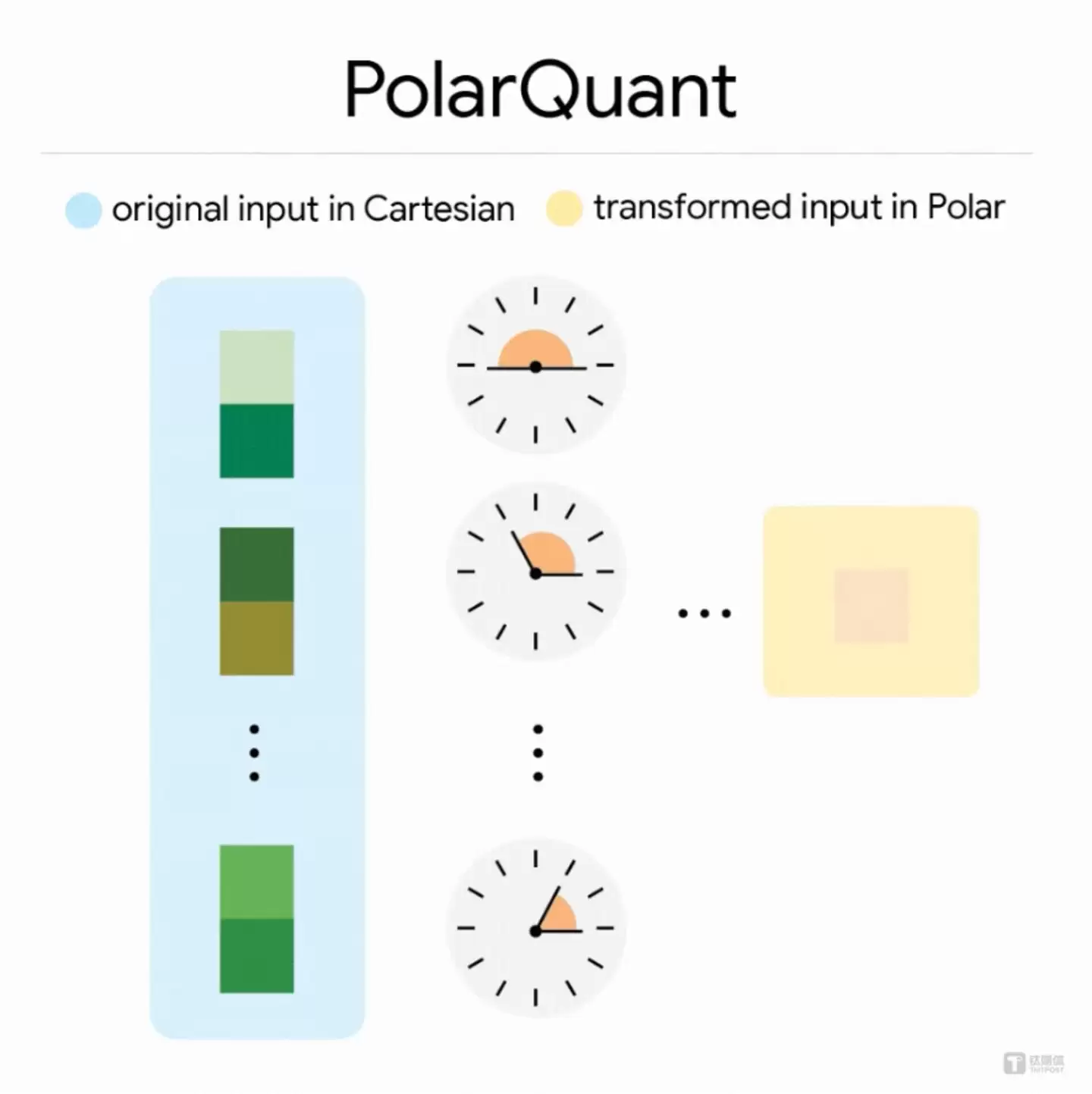
TurboQuant的破解之道,在于两个精巧的算法组合:负责主压缩的PolarQuant,和负责精细校正的QJL,双管齐下,目标直指压缩KV Cache中的高维向量。
第一步:PolarQuant——高质量压缩
传统的量化方法,好比用“东南西北”的直角坐标来记录一个点的位置。而TurboQuant的第一步PolarQuant,则换了一种思路,改用“角度和距离”的极坐标来描述。研究发现,经过一种特定的数学变换后,高维向量的数值分布会变得非常规整,就像一个刻好固定刻度的圆形标尺。这样一来,系统就能提前准备一套最优的压缩“密码本”,无需每次对话都临时校准,实现了真正的在线实时压缩。这一步,用大部分的比特位完成了对数据主体的高质量“瘦身”。
第二步:QJL——消除隐藏误差
主压缩之后,总会残留一些微小的误差。如果置之不理,当AI计算“注意力”(即判断该关注对话中的哪部分内容)时,这些误差会不断累积,最终导致“关注点”出现偏差。TurboQuant的第二个创新点,就是用名为QJL的方法来处理这些残差。QJL的聪明之处在于,它仅用1个比特来标记残差的方向,然后与高精度的原始查询向量结合,最终能实现无偏差的内积估算。这意味着,数据虽然被大幅压缩了,但AI在判断“信息重要性”时,得出的结论依然精准可靠。
根据谷歌官方博客披露的数据,TurboQuant带来了接近理论极限的性能提升:
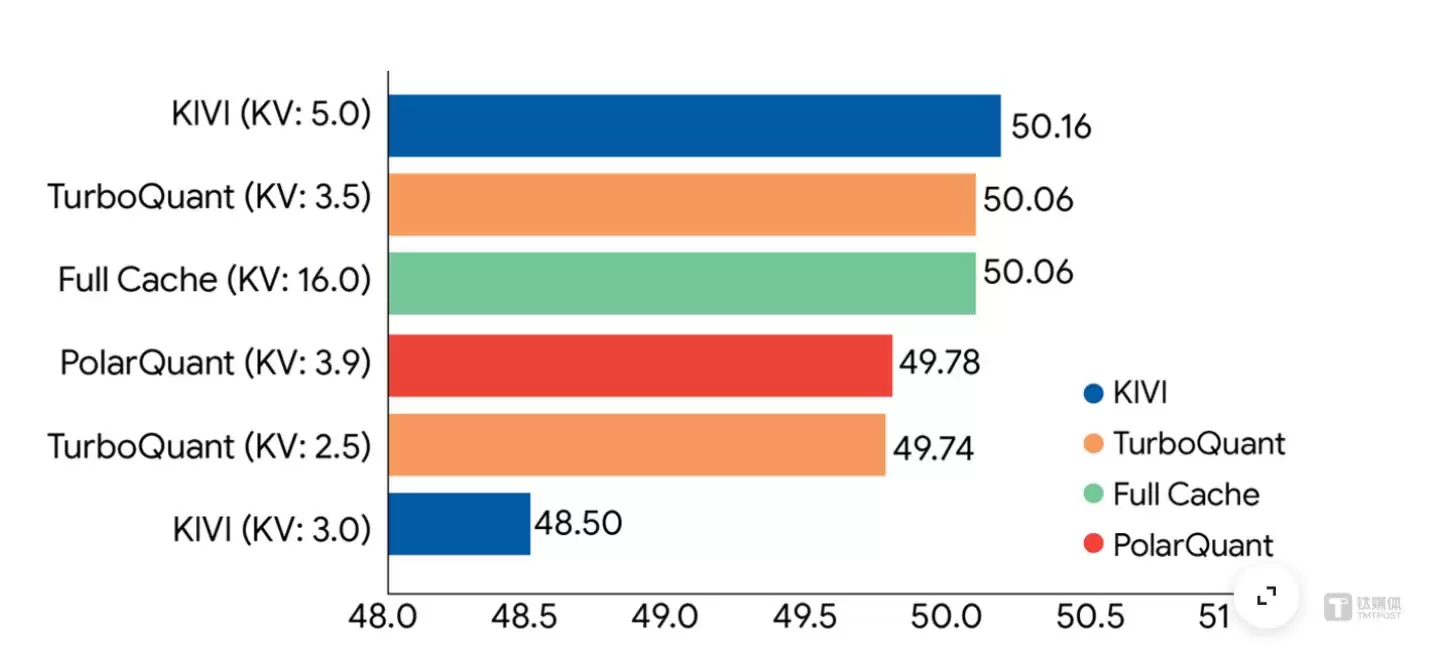
极致压缩:能将KV Cache压缩到每通道仅3比特,与传统16或32比特存储相比,内存占用减少至少6倍。在长上下文测试中,即便经过如此极致的压缩,模型仍然能精准找到隐藏信息,表现满分。
精度无损:在多个标准长上下文基准测试上,使用3.5比特配置的TurboQuant,模型性能与使用全精度缓存时完全一致;即便是2.5比特配置,性能也只有轻微下降。
速度飞跃:由于需要从内存中读取的数据量锐减,计算速度获得极大提升。在H100 GPU上,4比特TurboQuant处理注意力核心步骤的速度,比未压缩的32比特版本快了整整8倍。
总而言之,TurboQuant能够以极低的内存占用、近乎零的预处理时间,构建并查询高精度的大型向量索引。这使得谷歌规模的语义搜索变得更快、更高效。当然,这项技术的意义绝不仅仅是实验室里的突破。据博客透露,虽然TurboQuant目前主要解决的是Gemini等模型的KV Cache瓶颈,但其底层技术同样适用于任何需要在高维向量数据库中进行海量搜索的场景,比如现代的语义搜索引擎。
该技术的相关论文已被接收,将于ICLR 2026和AISTATS 2026学术会议上正式发表。
相关链接:https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
相关论文链接:https://arxiv.org/pdf/2502.02617
(本文作者 | 杨丽,编辑 | 杨林)
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 上汽大众途观L Pro再添新成员!300TSI智悦版入门款上市 21.38万起售
- 上汽大众途观L Pro新增入门款:21.38万元起,精准定位性价比市场 紧凑型SUV市场最近又迎来了一位新玩家。上汽大众途观L Pro家族新添了一位成员——300TSI智悦版,起售价定在了21.38万元。简单来说,这款车在保留了家族核心设计和空间优势的前提下,通过一些配置上的精打细算,把价格门槛往下
- 17分钟前 0
-
 正版软件
正版软件
- 苹果Studio Display XDR功能已获FDA批准用于诊断放射学领域
- 苹果 Studio Display XDR 获 FDA 认证,专业显示器“跨界”医疗诊断 苹果最近放出了一个重磅消息:其 Studio Display XDR 内置的“医学影像校准器”功能,正式拿到了美国食品药品监督管理局(FDA)的认证许可。这意味着,从本周开始,美国的放射科医生等专业人士,可以直
- 17分钟前 0
-
 正版软件
正版软件
- 世界上第一部手机:充电10小时,通话半小时
- 时间倒回1973年4月3日。在美国纽约的第六大道上,摩托罗拉的工程师马丁·库珀做了一个划时代的举动——他掏出了一台设备,并拨出了一通电话。这可不是普通的通话,而是人类历史上的第一通移动电话。 后来据库珀回忆,他当时把电话打给了贝尔实验室的竞争对手。他带着几分得意告诉对方,自己正使用的是一部“个人、手
- 18分钟前 0
-
 正版软件
正版软件
- 苹果可折叠iPhone遭遇工程难题,股价一度重挫逾5%,但报道称仍计划9月发布
- 苹果首款可折叠iPhone,今年秋季见? 关于苹果首款可折叠iPhone的发布时间,市场情绪可谓一波三折。最新消息显示,这款备受瞩目的产品仍有望按原计划,在今年秋季与大家见面。此前,一篇关于技术障碍的报道曾引发市场对延期的担忧,甚至导致苹果股价单日一度重挫超过5%。现在看来,这场虚惊似乎可以告一段落
- 18分钟前 0
-
 正版软件
正版软件
- 商业头条No.111|揭秘追觅“宇宙”:狂人俞浩和他的百万亿美金梦
- 追觅“宇宙”:一场极限狂奔下的组织实验 2月4日晚,苏州奥林匹克体育中心被数万人填满。追觅科技以一场汇集韩红、李克勤等多位明星的年会,展示了它的不凡声势。开场前,创始人兼CEO俞浩登台许愿——这位1987年出生的清华毕业生,毫不掩饰自己的野心:一是将追觅打造为人类历史上最伟大的企业,二是让自己登上世
- 19分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 518天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 525天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 536天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 828天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 544天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2322天前
相关推荐
- 上汽大众途观L Pro再添新成员!300TSI智悦版入门款上市 21.38万起售
- 苹果Studio Display XDR功能已获FDA批准用于诊断放射学领域
- 世界上第一部手机:充电10小时,通话半小时
- 苹果可折叠iPhone遭遇工程难题,股价一度重挫逾5%,但报道称仍计划9月发布
- 商业头条No.111|揭秘追觅“宇宙”:狂人俞浩和他的百万亿美金梦
- “芯片荒”致苹果发货周期大幅拉长,Mac mini和Studio最长要等5个月
- AI早报 | 优必选招募具身智能首席科学家,年薪最高1.24亿;科技播客TBPN被OpenAI收购,曾访谈扎克伯格、奥特曼等巨头高管
- 运动相机赛道新增劲敌,影石创始人刘靖康怒斥对手“断指计划”恶意挖人
- 真我GT Neo6 SE体验:靠更亮的屏突围中端市场
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00