颠覆!NVIDIA发明新技术KVTC:内存使用量缩减20倍
 发布于2026-04-29 阅读(0)
发布于2026-04-29 阅读(0)
扫一扫,手机访问
NVIDIA推出KVTC技术:将LLM对话内存压缩20倍,推理速度提升8倍
最近,NVIDIA的研究团队放了个大招——一项名为KVTC(KV快取转换编码)的全新技术。它的目标直指一个让许多企业头疼的问题:大型语言模型在处理长对话时,那不断膨胀的内存占用。这项技术能在不修改模型本身的前提下,将追踪对话历史所需的内存用量,最高压缩20倍。
这意味着什么?简单说,它有望彻底解决长上下文推理时的内存瓶颈,大幅降低企业运行AI的硬件成本。更诱人的是,它还能将模型首次生成回应的速度,最高提升8倍。对于追求效率的应用场景来说,这无疑是雪中送炭。
理解KV缓存:AI的“短期记忆簿”
要弄懂KVTC的价值,得先明白它要压缩的对象——KV缓存。你可以把它想象成AI模型的“短期记忆”或“工作笔记”。当模型进行多轮对话时,它会把每次交互中的关键信息(Key和Value)记录下来。这样,在生成下一句回应时,就不需要把整个对话历史重新计算一遍,响应速度自然就快了。

但麻烦也随之而来:对话越长,这份“笔记”就越厚,体积呈指数级增长,轻松就能占到几个GB的GPU内存。这不仅会拖慢模型运行,更会严重限制其处理长上下文的能力。内存告急,成了性能提升路上的一大绊脚石。
性能瓶颈不在算力,而在内存
NVIDIA资深深度学习工程师Adrian Lancucki点破了关键:“大型语言模型进行推论时,性能瓶颈往往不在运算能力,而在GPU内存。”那些暂时用不上、却又不敢丢的KV缓存,长期霸占着宝贵的GPU资源。系统被逼无奈,只能把它们“挤”到更慢的CPU内存甚至硬盘里。这一来一回的数据搬运,不仅增加了额外负担,还可能引发新的延迟问题,最终所有这些成本,都会转嫁到企业的账单上。
化繁为简:借鉴JPEG的压缩哲学
那么,KVTC是如何破局的?它与现有的许多压缩技术不同,没有那么多条条框框的限制。其思路借鉴了我们都非常熟悉的JPEG图片压缩——在尽可能保持“视觉”(对AI来说就是“语义”)质量的前提下,大幅缩减体积。
它主要通过三个步骤实现高效压缩:主成分分析、自适应量化和熵编码。这套组合拳的精妙之处在于,它抓住了KV缓存“数据高度相关”的内在特点,能够精准地区分关键信息和冗余数据,从而在压缩时做到“去粗取精”。
更值得一提的是,这项技术属于“非侵入式”设计。企业无需改动模型的核心架构或代码,拿过来就能快速集成部署。在解压时,它支持分块、逐层进行,完全不会干扰模型的实时响应能力。
实测表现:压缩20倍,精度损失不到1%
纸上谈兵不如实际测试。在多轮评估中,KVTC的表现大幅超越了现有的主流压缩方法。在参数量从15亿到700亿不等的多种主流模型(包括Llama 3系列、R1-Qwen 2.5等)上,即便将内存压缩到原来的1/20,模型的准确率也几乎纹丝不动,损失控制在1%以内,与未压缩时的表现相差无几。
相比之下,一些传统压缩方法仅仅压缩5倍,就会出现明显的精度下滑。这足以证明KVTC在精度与效率的平衡上,找到了更优的解法。
速度提升同样惊人。在H100 GPU上处理一段8000个Token的提示时,不使用KVTC需要等待3秒才能看到第一个词生成;而启用KVTC后,这个时间缩短到了380毫秒,提速整整8倍。这“第一句话”的等待时间,直接决定了用户体验的流畅度。
适用场景与未来展望
当然,任何技术都有其最适合的舞台。KVTC的价值在长对话、多轮交互的场景中最为凸显,例如复杂的编程助手、需要反复迭代的智能体推理等。如果只是三两句话的简短交流,它的压缩优势就难以充分发挥了。
目前,NVIDIA正计划将这项技术整合进TensorRT-LLM的KV缓存管理器中,以确保其能与vLLM等主流开源推理引擎无缝兼容。
行业观察家们认为,随着大模型处理上下文的能力不断突破,对话长度越来越长,像KVTC这样的标准化压缩技术,未来很可能像如今的视频压缩编码一样普及。它将成为AI大规模落地应用的一项关键基础设施,帮助更多企业以更低的成本,用上更强大的模型能力。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 技嘉带来 Z890 D PLUS 主板,提供 3 条物理全长 PCIe 插槽
- 技嘉推出Z890 D PLUS主板:面向主流用户的实用之选 3月23日,技嘉正式发布了Z890 D PLUS主板。这款ATX规格的产品定位明确——就是要满足大多数用户的实际需求。它采用4DIMM内存插槽设计,官方标称支持DDR5-9466+的超频能力,这在同级别主板中颇具竞争力。 扩展性方面值得特别
- 19分钟前 0
-
 正版软件
正版软件
- vivo X300s 手机参数汇总:6.78 英寸直屏、7100mAh 电池,3 月 30 日发布
- vivo X300s 详细参数曝光:6.78英寸直屏与7100mAh电池组合,定档3月30日 关注手机动态的朋友们,近期又有新戏码了。官方已经敲定,vivo X300s 将于3月30日晚7点正式登场。这不,知名博主 @数码闲聊站 已经抢先一步,把这款新机的核心参数给汇总了个七七八八。 具体来看,这份
- 19分钟前 0
-
 正版软件
正版软件
- 北斗卫星消息版终下三千:华为 Pura 70 手机 512G 版 2999 元再降价
- 华为Pura 70手机的上市,一度是2024年4月业界关注的焦点。当时,其12GB+512GB版本的定价锁定在5999元,定位清晰。 然而市场风云变幻,价格总是充满悬念。谁能想到,如今在京东平台,得益于官方补贴,同一配置的北斗卫星消息版,入手价已经来到了2999元。这个价格,对于一款搭载卫星通信功能
- 19分钟前 0
-
 正版软件
正版软件
- 1599 → 678 元:MOVA G12 Mix 洗地机官方新低,除螨 / 吸尘 / 洗地等五合一
- 1599 → 678 元:MOVA G12 Mix 洗地机官方新低,除螨 / 吸尘 / 洗地等五合一 对于关注家庭清洁设备的朋友来说,MOVA G12 Mix 洗地机或许并不陌生。这款去年7月中旬上市的产品,当初以支持180°躺平洗地和1599元的定价进入市场,引起了不小的关注。而如今,它的价格迎来
- 20分钟前 0
-
 正版软件
正版软件
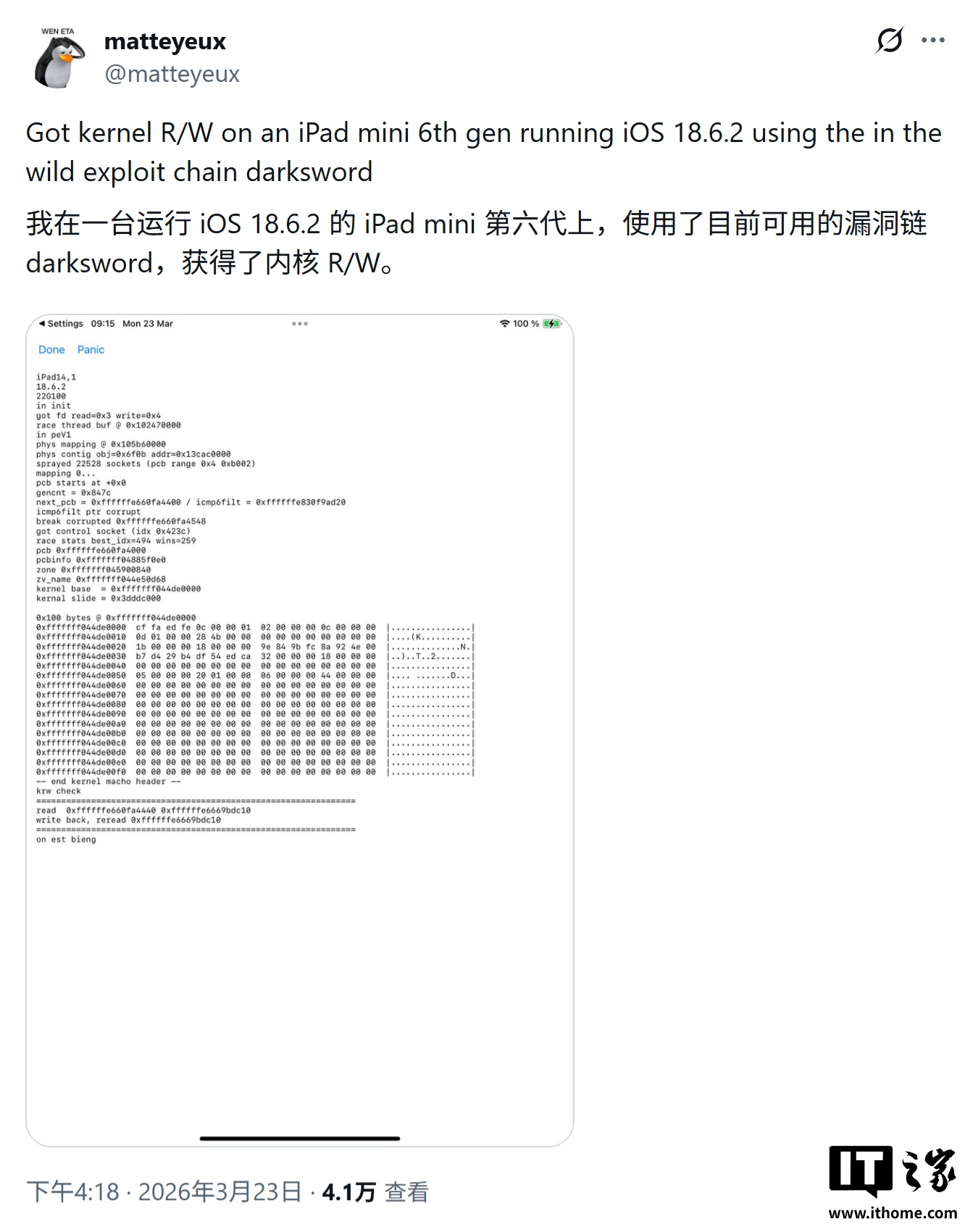
- 苹果 iOS 18 高危漏洞工具 DarkSword 代码公开,黑客无需专业知识即可入侵
- 苹果 iOS 18 高危漏洞工具 DarkSword 代码公开,黑客无需专业知识即可入侵 一则来自科技媒体 TechCrunch 的最新报道,让安全圈绷紧了神经。就在3月23日,一个名为 DarkSword 的高级 iPhone 黑客工具新版本被匿名者泄露,其完整代码已被公开发布在 GitHub 上
- 20分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 522天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 529天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 540天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 832天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 548天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2326天前
相关推荐
- 微星“MAG 276QRDY54”27英寸显示器上架,6299元
- 东方甄选:奖励俞敏洪180万股
- 马斯克法庭对决奥尔特曼 OpenAI能否转为营利性实体成焦点
- 六十余载科考路 三极探秘写春秋 高登义荣膺中国气象服务协会2025年度风云成就奖
- 因劳动力短缺,日本航司启动人形机器人应用实验,产品来自宇树、优必选
- 技嘉带来 Z890 D PLUS 主板,提供 3 条物理全长 PCIe 插槽
- vivo X300s 手机参数汇总:6.78 英寸直屏、7100mAh 电池,3 月 30 日发布
- 北斗卫星消息版终下三千:华为 Pura 70 手机 512G 版 2999 元再降价
- 1599 → 678 元:MOVA G12 Mix 洗地机官方新低,除螨 / 吸尘 / 洗地等五合一
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00