千问发布Qwen3.7-Max 致力成为全能的智能体基座
 发布于2026-05-20 阅读(0)
发布于2026-05-20 阅读(0)
扫一扫,手机访问
5月20日,通义千问正式发布了新一代旗舰模型Qwen3.7-Max。这款被定位为“面向智能体时代”的模型,即将通过API提供服务,其核心目标是成为一个全能的智能体基座。无论是编写调试代码、自动化办公流程,还是执行跨越数百甚至数千步的长周期复杂任务,它都旨在提供持续、自主且稳定的支持。
核心优势:广度与深度兼备的智能体能力
Qwen3.7-Max的竞争力,在于其智能体能力的广泛覆盖与深度执行。在编程领域,从前端原型快速搭建到复杂的多文件软件工程,它都能驾驭。在办公与生产力场景,通过支持MCP集成和多智能体协作,可以实现工作流的深度自动化。更值得关注的是其长周期任务执行能力:在一项长达35小时、涉及超过1000次工具调用的全自主内核优化实验中,模型展现了出色的连贯推理与持久稳定性。此外,无论部署在Claude Code、OpenClaw、Qwen Code还是其他自定义框架下,它都表现出了优秀的跨框架泛化能力,确保了其作为基座的可靠性。
Qwen3.7-Max即将通过阿里云百炼平台提供API服务,主要聚焦于以下几个前沿方向:
- 前沿编程智能体:覆盖从前端原型到复杂软件工程的全流程。
- 办公生产力与工作流自动化:支持MCP集成和多智能体协作。
- 持续稳定的长周期自主执行能力。
- 跨多种智能体框架的泛化能力。
模型表现
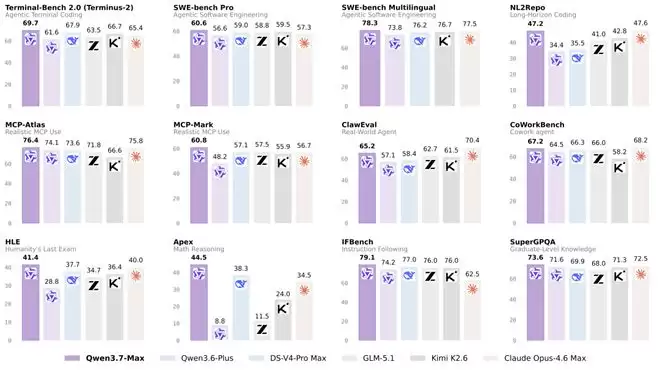
从具体评测数据来看,Qwen3.7-Max在不同维度均展现了领先或顶尖的实力。
编程智能体方面,在SWE-Pro(60.6)、SWE-Multilingual(78.3)、SciCode(53.5)和QwenSVG(1608)上均取得领先。在Terminal Bench 2.0-Terminus(69.7)上超越了DS-V4-Pro Max(67.9)。在SWE-Verified(80.4)上则与Opus-4.6 Max(80.8)和DS-V4-Pro Max(80.6)表现相当。
通用智能体方面,提升更为显著。在MCP-Mark(60.8 vs. GLM-5.1的57.5)、MCP-Atlas(76.4 vs. Opus-4.6的75.8)和Skillbench(59.2 vs. K2.6的56.2)上表现突出,并在Kernel Bench L3(1.98倍中位数加速,96%加速率)上展示了强大的GPU内核优化能力。在BFCL-V4(75.0)、Qwenclaw(64.3)和ClawEval(65.2)上同样表现出色,紧追Opus-4.6 Max。在办公自动化基准SpreadSheetBench-v1上得分87.0,处于顶尖水平。
推理能力方面,在多个高难度基准上取得领先:GPQA Diamond(92.4 vs. Opus-4.6的91.3)、HLE(41.4 vs. Opus-4.6的40.0)、HMMT 2026 Feb(97.1 vs. Opus-4.6的96.2)、IMOAnswerBench(90.0 vs. DS-V4-Pro的89.8)和Apex(44.5 vs. DS-V4-Pro的38.3)。
通用与多语言能力方面,在IFBench(79.1 vs. DS-V4-Pro的77.0)上表现突出,展示了精准的指令遵循能力。在WMT24++(85.8)和MAXIFE(89.2)上领先,表明其多语言理解和翻译质量处于一流水平。在SuperGPQA(73.6)和QwenWorldBench(57.3)上同样表现出色。
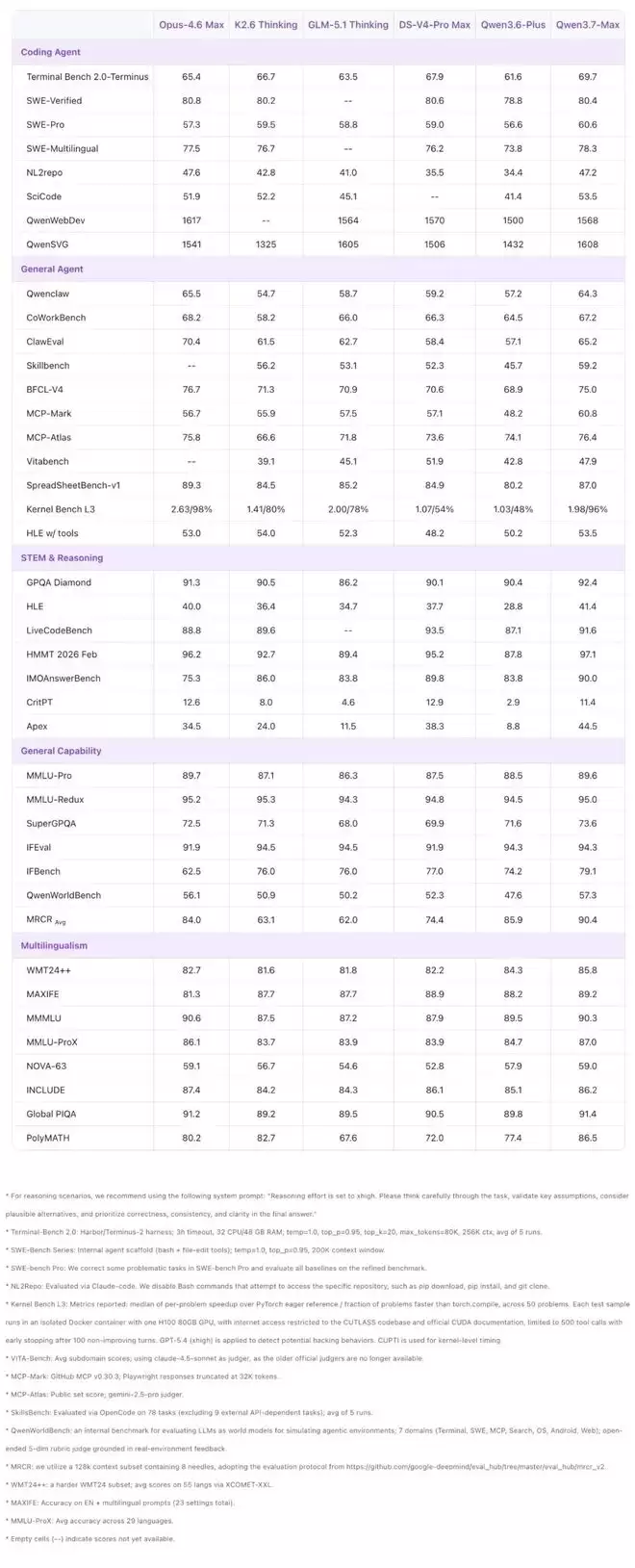
需要特别指出的是,上述评测分数是在多种不同的智能体框架下取得的。这意味着Qwen3.7-Max并非针对某一特定框架进行优化,而是在Claude Code、OpenClaw、Qwen Code及各类自定义工具使用框架下都能稳定发挥,这使其成为各类智能体系统更可靠、更通用的底座。
生产力助手:重塑专业工作流
面向真实的生产力场景,Qwen3.7-Max旨在成为深度的协作者。依托其强大的智能体能力,它可以全面重塑专业工作流:从海量信息的研读整合,到复杂数据的深度分析与建模,再到出版级文档与可视化的生成,它能够精准承接高复杂度、高强度的企业级任务。
该模型原生适配主流智能体框架。针对长链路交付任务,它支持长达数小时的自主规划与运行,通过上千次工具调用和数十轮版本迭代,持续提升最终交付物的质量。以往需要专业团队耗时一至两周的复杂项目,现在由Qwen3.7-Max驱动的智能体有望在数小时内完成端到端的交付闭环,从而推动生产力实现实质性的跃升。
智能体扩展:环境多样性驱动能力泛化
在Qwen3.5引入的环境扩展方法基础上,Qwen3.7进一步大幅提升了智能体训练环境的质量与多样性。这背后的逻辑与语言模型类似:正如语言模型从多样化的预训练文本中获得泛化能力,智能体能力同样可以从多样化的训练环境中实现泛化。
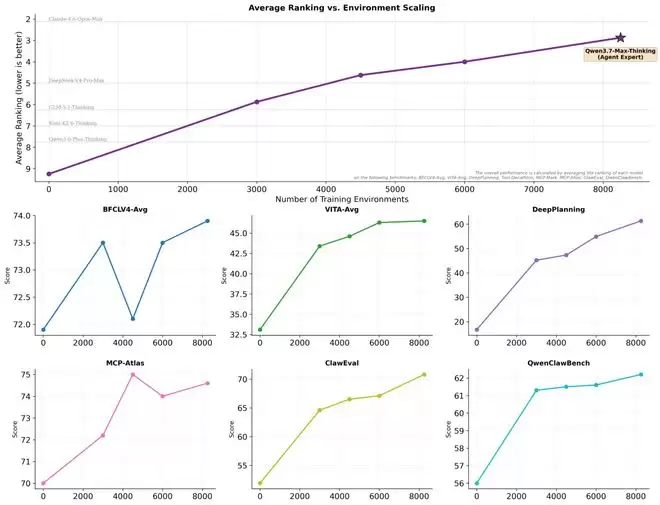
如图所示,这种环境扩展带来了清晰且稳定的性能提升轨迹,Qwen3.7-Max在综合排名中已位列前三,接近Claude-4.6-Opus-Max的水平。值得注意的是,评测中所有基准测试所涉及的环境,均为训练中从未出现过的全新领域外环境。
研究还观察到一个显著规律:在任意基准子集上获得的性能增益高度一致,可以可靠地预测其在其余基准或整体平均值上的相对增益。这表明,环境扩展驱动的是真正的、通用的能力泛化,而非针对特定基准的针对性提升。关于扩展动态和方法论的进一步分析,将在后续发布的技术报告中详细介绍。
跨框架泛化能力:掌握解题策略,而非框架捷径
为了实现真正的泛化,其训练基础设施将每个训练实例解耦为三个正交组件——任务(Task)、运行框架(Harness)与验证器(Verifier),这些组件可以自由重组。该设计兼容多种运行框架及其迭代版本,并将环境立足于真实场景。这种解耦实现了组合式扩展:同一任务能以极低的边际成本,与不同类型、版本的框架及验证器相匹配。
更关键的是,它赋能了跨框架与跨验证器的强化学习训练——迫使模型在多变的框架配置下处理同源任务,从而学习具备泛化能力的解题策略,而非依赖特定框架的“捷径”。在QwenClawBench与CoWorkBench评测中,无论评估时使用何种运行框架,Qwen3.7-Max均展现出强劲且一致的性能,显著超越Qwen3.6系列模型。这证实了该模型已真正掌握了解决任务的核心能力,而非过拟合于某个特定框架。
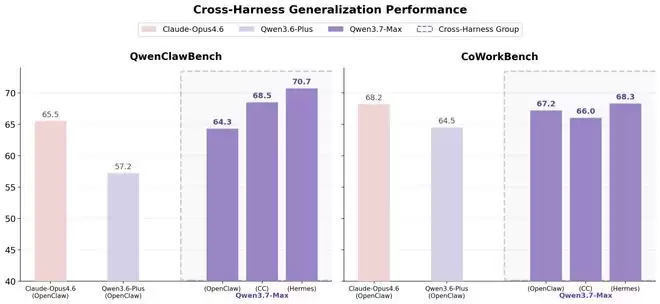
因此,Qwen3.7-Max可以无缝集成到包括Claude Code、OpenClaw、Qwen Code在内的主流智能体框架和编程助手中,为开发者提供一个强大而灵活的基座选择。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 曝iPhone Ultra或实现无折痕设计
- 5月20日,供应链传来新动向:苹果的首款折叠屏手机,据传将被命名为iPhone Ultra,其核心亮点在于一项旨在“消灭”折痕的无痕铰链设计。这意味着,当屏幕展开后,视觉上的凹凸感将被最大程度地弱化。 那么,这项技术从何而来?根据数码博主的爆料,苹果这套铰链方案的技术思路,与国内厂商OPPO已在Fi
- 25分钟前 0
-
 正版软件
正版软件
- “AI泔水”降效增本,1154条开发者讨论,指向游戏行业新问题
- “AI泔水”这个词,你最近在开发者社区里是不是听得越来越多了?它原本多指那些充斥社交媒体、污染搜索引擎的低质AI内容,但现在,它正悄然入侵一个更专业的领域:软件开发。 最近,海德堡大学、墨尔本大学和新加坡管理大学的研究者们联合发布了一篇论文,标题直接点明了这种忧虑:《一股无尽的AI泔水:AI辅助软件
- 25分钟前 0
-
 正版软件
正版软件
- 金蝶发布企业AI操作系统“灵基”,引领企业进入AI原生时代
- 5月20日,金蝶AI峰会2026于深圳圆满落幕。这场线上线下同步举行的盛会,汇聚了产业界与学术界的先锋力量,共同勾勒智能未来的图景。会上,一个关键产品正式亮相——金蝶发布的企业AI操作系统“灵基(Lingee)”。这不仅是金蝶自身AI战略的一次全面跃迁,更被视为驱动整个企业管理范式迈向AI原生时代的
- 26分钟前 0
-
 正版软件
正版软件
- 谷歌I/O大会的10个新东西,用Gemini接管一切
- 一年一度的谷歌I/O开发者大会,再次将全球的目光聚焦在山景城。与往年相比,今年的发布会透露出一个更清晰、更激进的信息:谷歌正试图用Gemini人工智能,全面接管用户从搜索、创作到日常任务执行的每一个环节。 Gemini 3.5 Flash:更快更强的模型核心 发布会最先登场的是新一代大语言模型Gem
- 27分钟前 0
-
 正版软件
正版软件
- 探微芯联完成数亿元融资,国产对标英伟达NVLink+NVSwitch方案商
- 如果用一个词概括未来的算力互联趋势,会是“统一”、“规模”,还是“能效”?答案是,三者缺一不可。 近日,国内算力基础设施领域传来一个重要消息。北京探微芯联科技有限公司,这家专注于提供国产全自研Scale-up超节点完整解决方案的公司,宣布已顺利完成天使+轮及Pre-A轮多轮融资,总额达数亿元软妹币。
- 27分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 543天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 550天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 561天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 853天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 569天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2347天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00