谷歌I/O大会的10个新东西,用Gemini接管一切
 发布于2026-05-20 阅读(0)
发布于2026-05-20 阅读(0)
扫一扫,手机访问
一年一度的谷歌I/O开发者大会,再次将全球的目光聚焦在山景城。与往年相比,今年的发布会透露出一个更清晰、更激进的信息:谷歌正试图用Gemini人工智能,全面接管用户从搜索、创作到日常任务执行的每一个环节。

Gemini 3.5 Flash:更快更强的模型核心
发布会最先登场的是新一代大语言模型Gemini 3.5 Flash。其核心卖点在于性能与效率:据称,其输出速度可比其他前沿模型快上4倍,在人工智能分析指数中占据“又快又强”的右上象限。
定价策略也体现了定位差异。3.5 Flash的输入定价为每百万token 1.5美元,输出为每百万token 9美元。这一价格比Gemini 3 Flash贵了约3倍,但比Gemini 3.1 Pro便宜了40%,意味着它在性能与成本之间找到了一个新的平衡点。
能力上,3.5 Flash在上一代强大的多模态基础上更进一步,尤其擅长生成丰富、交互性强的Web用户界面和图形。演示显示,它能在不到一分钟内生成6个不同的支付页面,或一次创造出64个分形图案变体。用户仅需文字描述一个想法,模型就能生成可交互的网页组件。
更复杂的应用在于内容转化。它可以将学术论文或课程视频,转化为互动式学习卡片和可视化页面。甚至在Google搜索中,也能根据用户问题现场生成图表、模拟器和沉浸式解释界面。谷歌将其定位为“能从任何输入,生成任何内容”的模型。目前,视频生成是第一步,未来还将支持图片、音频等多种输出形式。
Gemini Omni Flash:从多模态输入到完整视频
紧随其后的是Gemini Omni Flash,首个上线的“从任何输入生成任何内容”的模型。它已面向Google AI Plus、Pro和Ultra订阅用户开放,可在Gemini App和Google Flow中使用,并免费接入YouTube Shorts和YouTube Create App。未来几周,还将通过API开放给开发者和企业客户。
值得注意的是,Omni并非单纯的文生视频模型。它能够将文字、图片、音频、视频同时作为输入,合成一段完整视频,并支持对话式视频编辑,大大降低了视频创作的门槛。
焕然一新的Gemini App
过去一年对Gemini App而言堪称“硕果累累”,其月活跃用户数已从去年I/O时的4亿飙升至超过9亿,覆盖230多个国家和70多种语言。此次大会,App本身也迎来了多项重要更新。
首先,自然是接入了全新的Gemini 3.5 Flash模型。其次,推出了名为“Neural Expressive”的新设计语言,界面将更动态,拥有流体动画、更鲜明的色彩和新字体,并整合了触觉反馈。
Gemini Live功能被直接整合进主应用,用户可以从打字自然切换到语音对话。更重要的是,Gemini的回答将不再局限于“文字墙”,而是能根据问题实时生成最合适的呈现形式,如图片、交互时间线、旁白视频或动态图形。这一新设计已在Web、Android和iOS平台全球推出。
Gemini Spark:你的24小时云端个人助手
本次大会最值得单独关注的产品之一,便是Gemini Spark。谷歌将其定位为“24/7 personal AI agent”,即一个能在用户授权下持续工作的智能体。
它运行在Gemini 3.5之上,深度连接Gmail、Docs、Slides等谷歌办公套件。作为云端Agent,即使用户关闭电脑、锁上手机,它也能在后台持续工作。
谷歌给出了几个典型场景:让它定期解析信用卡账单,找出隐藏费用或新增订阅;教会它检查孩子的学校邮件,提取重要日期并每日生成简报;或者,从邮件和聊天记录的会议纪要中提炼信息,整理成Google Docs文档,并起草项目启动邮件。
这无疑是典型的Agent叙事:跨应用自动化完成一连串任务。这也是谷歌最具优势也最敏感的领域——手握Gmail、Calendar、Docs、Drive、Search、YouTube等核心应用,只要用户授权,Gemini能触及的个人上下文将构成一个无比庞大的生态。当然,谷歌也强调了权限与安全,Spark需用户手动开启并选择连接的应用,涉及消费、发邮件等高危操作时会预先征求同意。该功能本周将面向受信测试者,下周计划作为Beta版向美国Google AI Ultra用户推出。
进入桌面:macOS版Gemini
一个容易被忽略的更新是Gemini推出了macOS桌面版应用。谷歌计划将Spark能力带到桌面端,使其能处理本地文件并自动化桌面工作流。
此外,还将加入新的语音能力:用户即使对着屏幕说一段不完整、夹杂停顿和口头禅的话,Gemini也能根据屏幕上下文,将其整理成准确文本,并直接插入光标所在位置。这看似微小的改进,实则意义重大,因为许多真实工作发生在本地环境和多窗口之间。将Agent能力延伸至桌面,是走向真正实用化的关键一步。
Google Search:25年来最大改版
本次最具象征意义的产品更新,莫过于Google Search。其搜索框迎来了25年历史上最大的交互变革。
新搜索框将动态展开,允许用户以更自然的方式描述问题;它会根据意图给出AI建议,而非传统的自动补全;同时支持多模态输入,用户可以使用文本、图片、文件、视频甚至Chrome标签页作为搜索起点。这意味着,搜索从“给我十个链接”演变为“基于我的问题或材料,请帮我理解和推进”。
AI Overview功能现在也能更自然地接入AI对话模式,用户可以直接对概述结果进行追问,搜索将带着上下文进入连续对话。这一体验已在桌面和移动端全球上线。
更进一步的Agent化能力体现在“Search agents”上。用户未来可以在Search中创建、定制和管理多个AI智能体。首批推出的是“信息型Agent”,它们可以24小时在后台监控用户关心的主题,并在适当时机提供一份综合更新。这类似于升级版的Google Alerts,但不再局限于关键词匹配,而是能够理解用户的深层意图,并跨网页、新闻、社交、金融等多源信息进行监控。该功能计划于今年夏季面向Google AI Pro和Ultra用户推出。
同时,Search正在扩展其“袋里预订”能力。例如,当用户搜索“周五晚上、能坐6人、有夜宵的私人KTV”时,Search会综合价格和可用性,并提供直接完成预订的入口。对于家政、美容、宠物护理等部分品类,用户甚至可授权Google袋里拨打商家电话。这些能力将于今年夏天在美国向所有用户推出。
此外,谷歌将Antigra vity与Gemini 3.5 Flash的编码能力整合进Search,目标是让搜索结果超越文本、图片和表格,能根据问题即时生成合适的交互界面。例如,理解天体物理或手表内部结构时,Search可以实时组装交互式图表、模拟器和可视化组件。这些生成式UI能力将于今夏免费开放给所有Search用户。
更进一步,对于搬家、筹备婚礼、管理健康计划等持续性项目,Search可以生成一个定制化的仪表盘或追踪器,供用户长期使用。
Universal Cart:跨平台的智能购物车
谷歌发布了“Universal Cart”,一个跨服务、跨商家的智能购物车系统。它可以出现在Search、Gemini、YouTube、Gmail中,用户无论在何处浏览商品,都可将其加入同一购物车。
它的智能之处在于,商品一旦加入,便会自动在后台运行:寻找优惠、追踪价格历史、提醒补货。它甚至能运用推理能力提前发现问题,例如,当用户在不同零售商处购买电脑配件时,它会提示组件兼容性问题并推荐替代方案。
Gemini智能眼镜:AI的“自然入口”
备受关注的Gemini智能眼镜也公布了更多细节。与昔日的Google Glass不同,新产品逻辑发生了根本转变。Google Glass试图将手机通知、拍照等功能“塞”进眼镜,而Gemini智能眼镜的核心是让AI“看见”和“听见”用户所处的世界,并即时提供帮助,成为一个更自然的AI入口。
新眼镜分为两种形态:音频眼镜,通过耳内语音提供帮助;显示眼镜,在需要时眼前显示信息。两者都旨在解放双手,用户只需开口提问,即可获得Gemini的协助。音频眼镜将先行上市,计划于今年秋季推出。
从外观上看,新款眼镜设计日常了许多。功能上,用户可通过“Hey Google”或轻触镜腿唤醒Gemini,询问眼前所见事物的信息,如餐厅评价、云朵类型或复杂路牌解读。它还支持导航、接打电话、总结未读消息、播放音乐,并能进行拍照录像,随后通过语音指令直接编辑图片。实时语音翻译功能甚至会尽量匹配说话人的语气和音高。眼镜同时支持Android和iOS系统,并可连接Uber等第三方应用。
这次的产品路线显然避开了Google Glass当年的几个主要陷阱:不再将眼镜定位为微型手机,核心是AI对现实世界的理解与执行;不过度押注重AR,先推出接受度更高的音频眼镜;重视外观设计,与Gentle Monster等时尚品牌合作,承认眼镜是消费品而非纯科技玩具。应用场景也更加明确:导航、翻译、视觉识别、信息摘要,这些功能更直接地回答了“用户为何需要它”的问题。
Google Antigra vity 2.0:面向开发者的Agent工作台
在开发者侧,最重要的更新是Google Antigra vity 2.0。谷歌将其称为“以Agent为先的开发平台”,这意味着它超越了传统的IDE插件,旨在成为一个围绕智能体构建的完整开发生态。
本次发布了Antigra vity 2.0桌面应用、Gemini API中的“托管袋里”,以及AI Studio中的原生Android vibe coding功能。其目标不再是简单地辅助补全代码或解释错误,而是实现“从提示词到生产就绪的应用”——开发者给出一个目标,AI便能自主进行任务规划、拆解、工具调用、测试、调试直至部署,并可能协调多个子智能体并行工作。这标志着与Codex、Claude Code、Cursor等工具在同一赛道的竞争,谷歌的优势在于其整合了Android、Cloud、Workspace等在内的完整生态系统。
Project Genie + Street View:连接真实世界的“世界模型”
另一个偏向前沿探索的产品是Project Genie。虽然大会上细节披露有限,但结合街景技术的演示,暗示了谷歌正致力于构建连接真实物理环境的“世界模型”。这或许意味着,未来的AI不仅能理解和生成数字内容,还能与真实世界的街景、地理信息深度融合,开启全新的交互与应用可能。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 拯救者手机Y70硬核回归:全境畅连无缝接管PC端游,重塑掌上电竞
- 联想发布天禧AI4.0及多款AI硬件新品,涵盖PC、手机、平板及主机等。天禧AI4.0实现从“+AI”到“AI+”的跃迁,具备主动任务处理与跨设备协同能力。拯救者系列完成生态闭环,Y70手机支持畅连PC端游;YOGA旗舰兼顾轻薄与性能;moto折叠屏重塑移动办公。通过“端-边-云”架构与生态计划,联想旨在构建无缝协同的智能体验。
- 25分钟前 0
-
 正版软件
正版软件
- 2026中国AI应用全景图谱发布:五大趋势重塑行业
- 量子位智库报告显示,中国AI应用生态已成形,2026年国内访问量巨大,市场活跃度全球领先。应用正从“好玩”转向“离不开”,效率办公与创作类增长显著。行业呈现五大趋势:AI向智能体进化、模型成本降能力升、巨头争入口、付费模式初通、B端垂直场景加速渗透。发展主线是从辅助工具转向深度嵌入工作流的。
- 25分钟前 0
-
 正版软件
正版软件
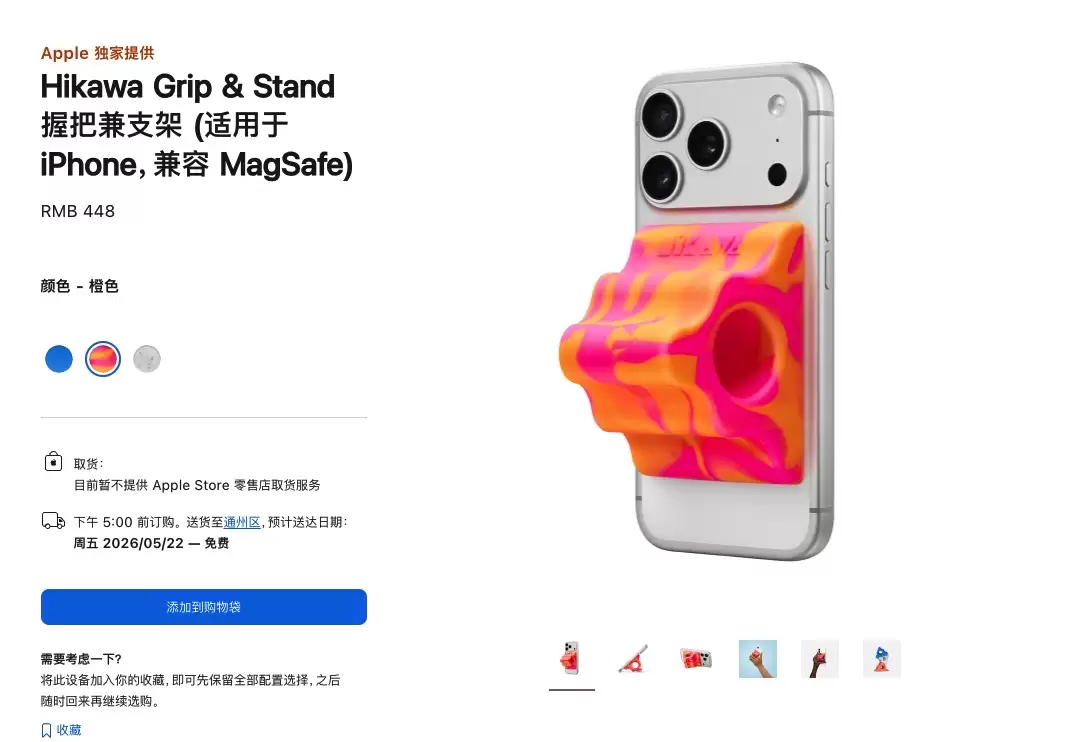
- iPhone绝版配件回归 Hikawa握把支架重新上架:售价 448 元
- 苹果官网重新上架绝版配件Hikawa握把支架,售价448元。该产品最初为纪念无障碍设计40周年限量推出,融合艺术与实用设计,提供多色可选并适配MagSafeiPhone。其采用亲肤硅树脂材质,兼具舒适握持感与横竖双模式支架功能,能有效缓解手部疲劳,提升使用体验。
- 26分钟前 0
-
 正版软件
正版软件
- 特斯拉Cybertruck当船开?美国真有人试了但失败了还被捕了
- 特斯拉Cybertruck车主在美国得州尝试将车辆驶入湖泊,启用涉水模式后车辆进水失灵被困。司机因此被捕并面临多项违规指控。该事件引发对其涉水能力的关注,实际该模式仅设计用于通过浅溪流,与马斯克曾宣传的“水陆两栖”愿景存在显著差距。
- 26分钟前 0
-
 正版软件
正版软件
- 平头哥AI芯片真武M890首次亮相,性能是真武810E的3倍
- 平头哥在2026阿里云峰会上发布新一代AI芯片真武M890,其性能为前代810E的三倍。该芯片支持广泛数据精度,适用于训练与推理全场景。配合自研互联芯片,可实现多芯片全带宽互联,提升集群效率。此次发布是阿里云“芯-云-模型-推理”技术体系升级的关键一环,旨在为下一代AI应用提供全栈基础设施支撑。
- 27分钟前 0
最新发布
-
 1
1
- 在哪里可以找到手机相片收藏
- 543天前
-
 2
2
- 详细解读I7-14650HX的性能评测数据
- 550天前
-
 3
3
- 如何选择DP接口版本: 1.2还是1.4?
- 561天前
-
 4
4
-
 5
5
- 华为GT4和Watch4,哪个更好?
- 853天前
-
 6
6
- 骁龙芯片的型号与天玑9400相当?
- 569天前
-
 7
7
-
 8
8
-
 9
9
- 三星“约谈”联发科 A系列智能手机有望搭载其5G芯片
- 2347天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00