如何使用Python的sklearn CountVectorizer?
 发布于2023-04-24 阅读(0)
发布于2023-04-24 阅读(0)
扫一扫,手机访问
简介
CountVectorizer官方文档。
将一个文档集合向量化为为一个计数矩阵。
如果不提供一个先验字典,不使用分析器做某种特征选择,那么特征的数量将等于通过分析数据发现的词汇量。
数据预处理
两种方法:1.可以不分词直接投入模型;2.可以先将中文文本进行分词。
两种方法产生的词汇会非常不同。在后面会具体给出示范。
import jieba
import re
from sklearn.feature_extraction.text import CountVectorizer
#原始数据
text = ['很少在公众场合手机外放',
'大部分人都还是很认真去学习的',
'他们会用行动来',
'无论你现在有多颓废,振作起来',
'只需要一点点地改变',
'你的外在和内在都能焕然一新']
#提取中文
text = [' '.join(re.findall('[\u4e00-\u9fa5]+',tt,re.S)) for tt in text]
#分词
text = [' '.join(jieba.lcut(tt)) for tt in text]
text
构建模型
训练模型
#构建模型 vectorizer = CountVectorizer() #训练模型 X = vectorizer.fit_transform(text)
所有词汇:model.get_feature_names()
#所有文档汇集后生成的词汇 feature_names = vectorizer.get_feature_names() print(feature_names)
不分词生成的词汇

分词后生成的词汇

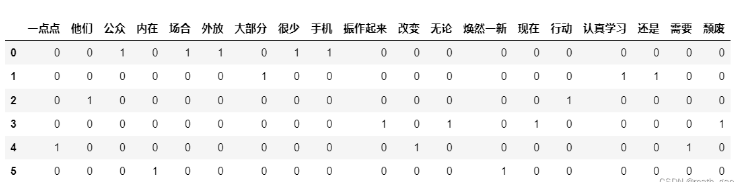
计数矩阵:X.toarray()
#每个文档相对词汇量出现次数形成的矩阵 matrix = X.toarray() print(matrix)

#计数矩阵转化为DataFrame df = pd.DataFrame(matrix, columns=feature_names) df
词汇索引:model.vocabulary_
print(vectorizer.vocabulary_)

本文转载于:https://www.yisu.com/zixun/775626.html 如有侵犯,请联系zhengruancom@outlook.com删除。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 夸克浏览器怎么设置电脑模式?夸克浏览器设置成电脑模式教程
- 夸克浏览器怎么设置电脑模式?嘿,兄弟们,你是否曾经需要在手机上看网页,但又要让页面显示效果如同在电脑上的体验?如果是,那么恭喜您,夸克浏览器就是您的不二之选!它不仅拥有简洁明了的界面设计,而且夸克浏览器手机版也可以轻松设置成电脑版,让你在手机端也能够享受到如同在电脑上的浏览体验。
- 19小时前 12:02 0
-
 正版软件
正版软件
- 夸克浏览器怎么开启成人模式?夸克浏览器设置成人模式的方法
- 如今电子产品不仅成年人在使用,未成年也是深深着迷,而各大产品为了更好的把控未成年人的电子产品使用时间,因此很多应用都提供了未成年模式,像夸克浏览器也一样,那么夸克浏览器怎么开启成人模式呢?夸克浏览器设置成人模式的方法1、打开您的夸克浏览器应用,点击屏幕右下角的三横线菜单图标。
- 19小时前 11:51 0
-
 正版软件
正版软件
- 东方甄选如何进行企业团购?东方甄选企业团购教程
- 东方甄选如何进行企业团购?每次节日到来前,各位企业的小伙伴是不是还在发愁为购买公司的礼品而发愁?不妨来看看东方甄选专享的企业团购吧!东方甄选能够给企业礼物提供定制化解决方案、企业优惠、专属服务,满足多元化的需求,让企业采购简单快捷、更省心,也能让员工更放心更满意。
- 20小时前 11:39 0
-
 正版软件
正版软件
- 饿了么怎么让别人代付?饿了么让别人代付的步骤教程
- 饿了么怎么让别人代付?现在夏天越来越热,相信在暑假时期外卖就是大家的救命稻草,饿了么这个软件大家应该也是十分熟悉,但是很多小伙伴跟小编反馈说不知道饿了么怎么让别人代付订单,那接下来小编就来给大家解决问题,带来饿了么让别人代付的步骤,一起来往下看看吧!
- 昨天 03-20 13:52 0
-
 正版软件
正版软件
- 饿了么如何设置小额免密支付功能?饿了么设置小额免密支付教程
- 饿了么如何设置小额免密支付功能?随着移动支付的普及和便利性,饿了么为了进一步提升用户体验,推出了小额免密支付功能。一些小伙伴反馈第一次使用不知道怎么去开启这个免密功能,让小编出一期关于这个操作的详细教程,这不它来了!本教程将详细介绍如何设置和使用这一功能,帮助您更加便捷地享受饿了么的服务。
- 昨天 03-20 13:30 0
最新发布
-
 1
1
-
 2
2
-
 3
3
- C语言中\n是什么意思?换行转义字符详解
- 195天前
-
4
- 探析Spring Boot框架的优点和特色
- 511天前
-
5
- 深入比较PyCharm社区版和专业版的功能
- 449天前
-
6
- 专家观点:谷歌是否会继续支持Golang的探讨
- 424天前
-
 7
7
- Python实战教程:批量转换多种音乐格式
- 1057天前
-
8
- 如何在在线答题中实现试卷的自动批改和自动评分
- 884天前
-
 9
9
- 解决Python安装失败的问题
- 435天前
相关推荐
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00