Linux如何排查系统句柄数超限问题 修改file-max与ulimit
 发布于2026-05-20 阅读(0)
发布于2026-05-20 阅读(0)
扫一扫,手机访问
遇到“Too many open files”报错,很多人的第一反应就是去调大file-max或者ulimit。但这就好比家里水管漏水,第一反应不是去找漏点,而是去把水表的总阀门拧大——水压是暂时上来了,但地板迟早要被泡坏。句柄超限问题的核心,从来不是“调大就完事”,而是要先确认三件事:系统是不是真的满了?是谁在“吃”句柄?以及,为什么它只吃不吐?否则,盲目修改参数,往往只是把系统崩溃的时间往后推迟了一天而已。

怎么看系统到底满没满
别只看报错信息就下结论。句柄限制其实有两层天花板,得分开验证:一层是整个系统的全局总量,另一层是单个进程的个体限额。
- 系统级总量:
cat /proc/sys/fs/file-max显示的是内核允许的全局上限,比如常见的1048576。但真正反映压力的,是另一个命令的输出:cat /proc/sys/fs/file-nr。它会返回三列数字,其中第二列才是当前已分配且未释放的文件描述符(fd)数量。只有当这个数字接近第一列(已分配总数)时,才说明系统级资源真的告急了。 - 进程级限额:在shell里执行
ulimit -n,看到的只是当前shell会话的软限制,默认通常是1024。但实际运行的进程可能继承了一个更小的值。想知道真相,得查进程运行时真实的限制:cat /proc/$(pidof nginx)/limits | grep “Max open files”,重点看“Soft Limit”这一项到底是多少。 - 一个常见的迷惑点:用
lsof -p统计某个进程打开的fd数,发现结果远超其Soft Limit,但进程居然没报错?这通常意味着它没有通过标准的| wc -l open()系统调用来打开文件(比如使用了memfd_create()这类特殊接口),或者它的限制被systemd的LimitNOFILE配置给覆盖了。
为什么改了 /etc/security/limits.conf 却不生效
这是最让人头疼的问题之一。原因很简单:大多数现代Linux发行版(尤其是使用systemd作为初始化系统的)在启动后台服务时,根本不会去读取这个经典的配置文件。
- 对于交互式登录用户:修改
/etc/security/limits.conf后,你需要重新登录(开启一个新的login shell),su或者已有的ssh会话子进程是不会生效的。同时,还得确认/etc/pam.d/common-session(或类似PAM配置)中包含了session required pam_limits.so这一行。 - 对于systemd服务(比如Nginx、Redis、MySQL):
limits.conf完全无效。你必须修改对应的service unit文件。推荐的做法是创建一个override配置片段,例如在/etc/systemd/system/nginx.service.d/override.conf中写入[Service]\nLimitNOFILE=65536,然后执行systemctl daemon-reload并重启服务。 - 对于容器环境(Docker/K8s):在宿主机上修改任何参数对容器内部都是无效的。你需要在启动容器时指定,例如
docker run --ulimit nofile=65536:65536,或者在Kubernetes Pod的securityContext.fdsLimit字段中进行设置。
file-max 和 nr_open 不能乱调
把file-max调大听起来很解渴,但它并非没有代价。每个文件描述符在内核中都会占用一小块内存(大约1KB),无节制地调高会消耗宝贵的内核内存。更关键的是另一个参数:nr_open。它定义了单个进程能够申请的文件描述符硬上限。你必须保证nr_open的值大于或等于file-max,否则,你连想通过ulimit -n设置一个较大的进程限制都做不到。
- 临时调整:执行
sysctl -w fs.file-max=2097152可以立即生效,但重启后会丢失。 - 永久生效:将
fs.file-max=2097152写入/etc/sysctl.conf。同时,务必检查fs.nr_open的值是否足够大,可以用cat /proc/sys/fs/nr_open查看。如果不够,你需要修改内核启动参数,通常在/etc/default/grub文件的GRUB_CMDLINE_LINUX行末尾添加nr_open=2097152,然后执行update-grub并重启。 - 一个隐蔽的坑:某些云服务商的系统镜像(例如阿里云的一些CentOS镜像)默认
nr_open值设置得较低(比如1048576)。如果你把file-max设为200万,修改会“静默失败”——sysctl -p命令可能不会报错,但实际上限并没有提上去。
真正该花时间的地方:定位泄漏而非调参
调整系统参数最多为你争取到几个小时的排查时间。如果不找到并修复泄漏的根源,问题迟早会卷土重来。排查时,重点关注以下几类文件描述符:
- 大量处于
CLOSE_WAIT状态的 socket:这通常意味着你的应用程序(本端)没有主动调用close()。在Ja va中可能是Socket对象未关闭,在Node.js中可能是net.Socket没有调用destroy()。 - 一堆
anon_inode或eventpoll:这往往指向epoll实例泄漏。常见于C/C++自研的网络库,或者Go语言中net.Conn未正确关闭的情况。 - 重复路径的日志文件(如
/var/log/app.log.1,.2,.3):这通常是logrotate在切割日志时,程序没有正确处理SIGHUP信号重新打开日志文件,导致旧的fd一直被进程持有。检查logrotate配置是否使用了copytruncate选项,或者程序是否实现了信号处理逻辑。 - 使用统计命令快速定位:与其干巴巴地看
lsof输出的几千行,不如用这个命令快速筛选高频连接目标:lsof -p。它能帮你立刻看出进程在和哪个远程地址建立了大量连接。| awk ‘$5 ~ /IPv|sock/ {print $9}’ | sort | uniq -c | sort -nr
最后,还有一个最容易被忽略的泄漏场景:子进程继承了父进程的fd。尤其是在fork()后执行exec()的程序模型中,如果父进程打开的大量连接(比如5000个socket)没有设置FD_CLOEXEC标志,那么子进程一启动就会“继承”这5000个fd,而开发者很可能完全意识不到这一点。所以,在编写会创建子进程的服务时,检查文件描述符的close-on-exec标志是否设置,是一个很好的习惯。
排查句柄泄漏的正确思路是:先分层验证系统级(
/proc/sys/fs/file-nr第二列)与进程级(/proc/pid/limits)的实际使用量,定位到泄漏源,而不是盲目调整参数;对于systemd服务,需要配置LimitNOFILE;对于容器,必须在运行时指定ulimit;同时要注意file-max必须≤nr_open,否则修改可能会静默失败。
免责声明:正软商城发布此文仅为传递信息,不代表正软商城认同其观点或证实其描述。
产品推荐
-

售后无忧
立即购买>- DAEMON Tools Lite 10【序列号终身授权 + 中文版 + Win】
-
¥150.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Ultra 5【序列号终身授权 + 中文版 + Win】
-
¥198.00
office旗舰店
-

售后无忧
立即购买>- DAEMON Tools Pro 8【序列号终身授权 + 中文版 + Win】
-
¥189.00
office旗舰店
-

售后无忧
立即购买>- CorelDRAW X8 简体中文【标准版 + Win】
-
¥1788.00
office旗舰店
-
 正版软件
正版软件
- 麒麟系统怎么使用手写板 麒麟OS手写输入设置
- 麒麟系统手写板失效常因服务未开启、输入法组件缺失或配置不当。需先确认硬件识别,再安装并启用Fcitx5中文扩展包,配置环境变量与服务,通过工具启用手写面板并设快捷键。也可安装搜狗输入法使用其手写模块。若系统较新且使用Wayland协议,需切换至X11会话并调整设置以确保兼容。
- 1分钟前 0
-
 正版软件
正版软件
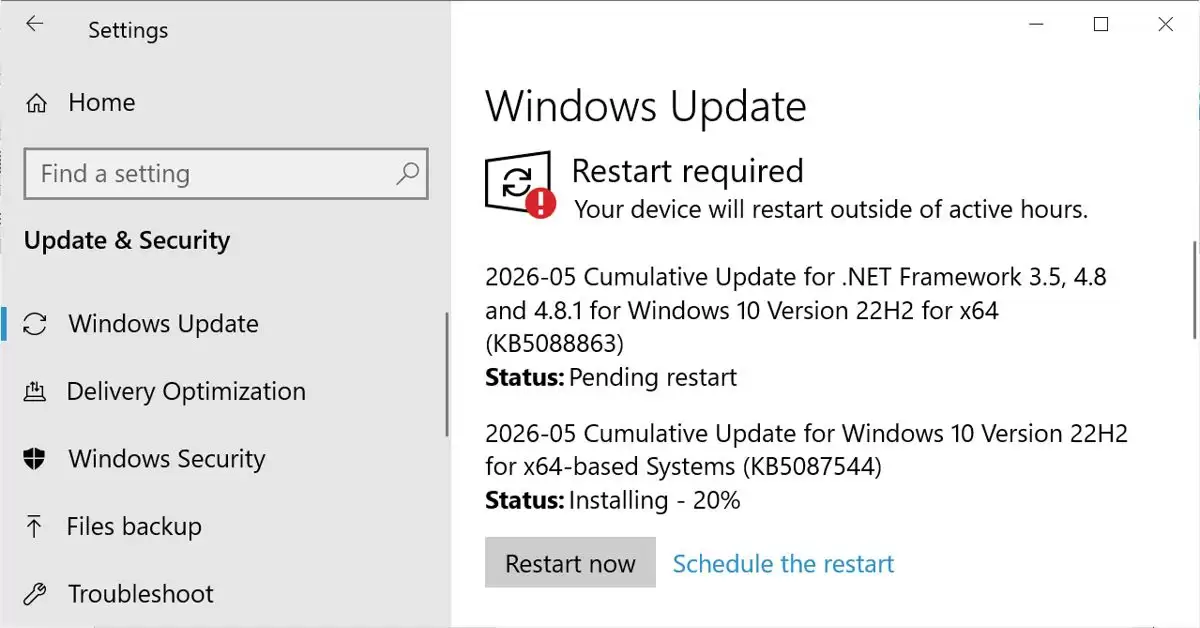
- Win10 五月扩展安全更新KB5087544推送:解决远程桌面警告异常
- 微软为Windows10推送五月安全更新KB5087544,修复多达120个安全漏洞,其中包括17个关键漏洞。此次更新重点解决了多显示器环境下远程桌面安全警告对话框的显示异常问题,并优化了Windows安全应用对SecureBoot状态的显示。微软提醒,部分设备更新后可能意外触发BitLocker恢复,需注意备份恢复密钥。
- 2分钟前 0
-
 正版软件
正版软件
- 增强辅助功能和系统交互! Win11 26H1 五月累积更新发布
- 微软为Windows11推送五月累积更新KB5089548,重点提升辅助功能与交互体验。讲述人现可联动Copilot,帮助视障用户理解图片内容;智能应用控制开关更便捷。设置应用界面获更新,包括重新设计的对话框、深色主题及更清晰的设备信息展示。文件资源管理器、高刷新率显示支持及远程桌面连接等功能也得到改进。
- 4分钟前 0
-
 正版软件
正版软件
- 不会全面开放Xbox模式! win11安装五月更新KB5089549后仍需服务器端激活
- 微软推送Windows11五月更新KB5089549,引入需服务器端激活的Xbox模式。该功能目前仅在部分市场分批推送,激活后将提供为手柄优化的全屏游戏界面,聚合游戏库并优化系统资源以提升性能。用户可通过设置、Xbox应用或快捷键启用,但需配备手柄。
- 4分钟前 0
-
 正版软件
正版软件
- 文件管理器原生支持更多压缩格式! Win11 5月累积更新KB5089549/KB5087420推送
- 微软五月为Windows11推送累积更新,修复了多达120个安全漏洞,含17个关键漏洞。更新提升了系统稳定性,改进了文件资源管理器,使其原生支持更多压缩格式,并优化了文件夹视图记忆和深色模式显示。此外还引入了Xbox模式新功能,增强了触控、远程桌面及安全启动等体验与安全性。
- 5分钟前 0
最新发布
-
 1
1
- 《抖音》充值抖币官网入口
- 534天前
-
 2
2
- 大麦网官网订票入口
- 429天前
-
 3
3
- 直接点击打开漫蛙网页版
- 544天前
-
 4
4
- 天堂漫画免费入口及最新观看链接
- 216天前
-
 5
5
- 喵趣漫画官网
- 536天前
-
 6
6
- B站免费入口长期可用指南
- 277天前
-
 7
7
- 58动漫网入口及永久访问方法
- 161天前
-
 8
8
- 中国裁判文书网官网入口查询
- 204天前
-
 9
9
- B站免费入口永久有效网址推荐
- 250天前
相关推荐
- 麒麟系统怎么使用手写板 麒麟OS手写输入设置
- Win10 五月扩展安全更新KB5087544推送:解决远程桌面警告异常
- 增强辅助功能和系统交互! Win11 26H1 五月累积更新发布
- 不会全面开放Xbox模式! win11安装五月更新KB5089549后仍需服务器端激活
- 文件管理器原生支持更多压缩格式! Win11 5月累积更新KB5089549/KB5087420推送
- 点击时CPU瞬时超频! Win11不再卡了
- Linux系统安装中文包教程 解决系统界面显示全英文问题
- Linux系统安装Python3环境 源码编译与多版本管理
- Linux怎么查看文件的最后一次读取时间 Linux下stat命令用法详解
热门关注
-

- Xshell 6 简体中文
- ¥899.00-¥1149.00
-

- DaVinci Resolve Studio 16 简体中文
- ¥2550.00-¥2550.00
-

- Camtasia 2019 简体中文
- ¥689.00-¥689.00
-

- Luminar 3 简体中文
- ¥288.00-¥288.00
-

- Apowersoft 录屏王 简体中文
- ¥129.00-¥339.00